Hamid Zain, Khalique Fatima, Mahmood Saba, Daud Ali, Bukhari Amal, Alshemaimri Bader
Department of Computer Science, Bahria University, Islamabad, Pakistan.
Faculty of Resilience, Rabdan Academy, Abu Dhabi, United Arab Emirates.
BMC Med Inform Decis Mak. 2024 Apr 26;24(1):112. doi: 10.1186/s12911-024-02512-4.
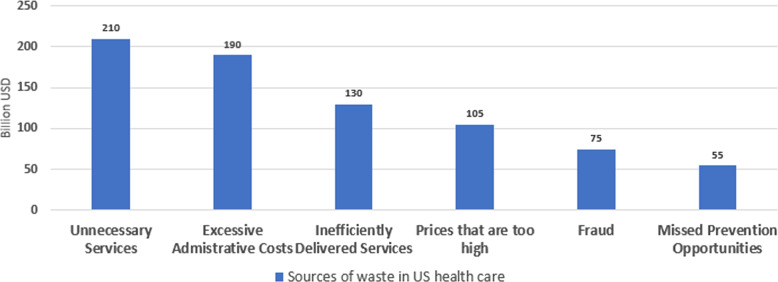
Healthcare programs and insurance initiatives play a crucial role in ensuring that people have access to medical care. There are many benefits of healthcare insurance programs but fraud in healthcare continues to be a significant challenge in the insurance industry. Healthcare insurance fraud detection faces challenges from evolving and sophisticated fraud schemes that adapt to detection methods. Analyzing extensive healthcare data is hindered by complexity, data quality issues, and the need for real-time detection, while privacy concerns and false positives pose additional hurdles. The lack of standardization in coding and limited resources further complicate efforts to address fraudulent activities effectively.
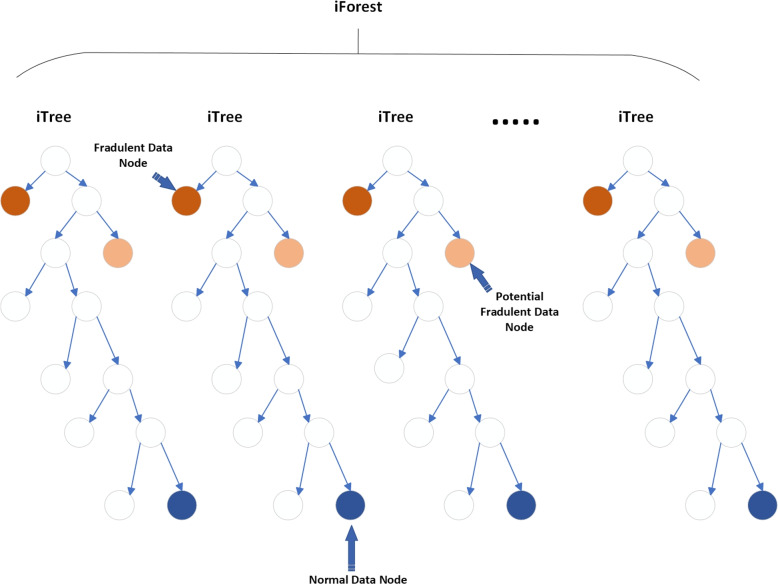
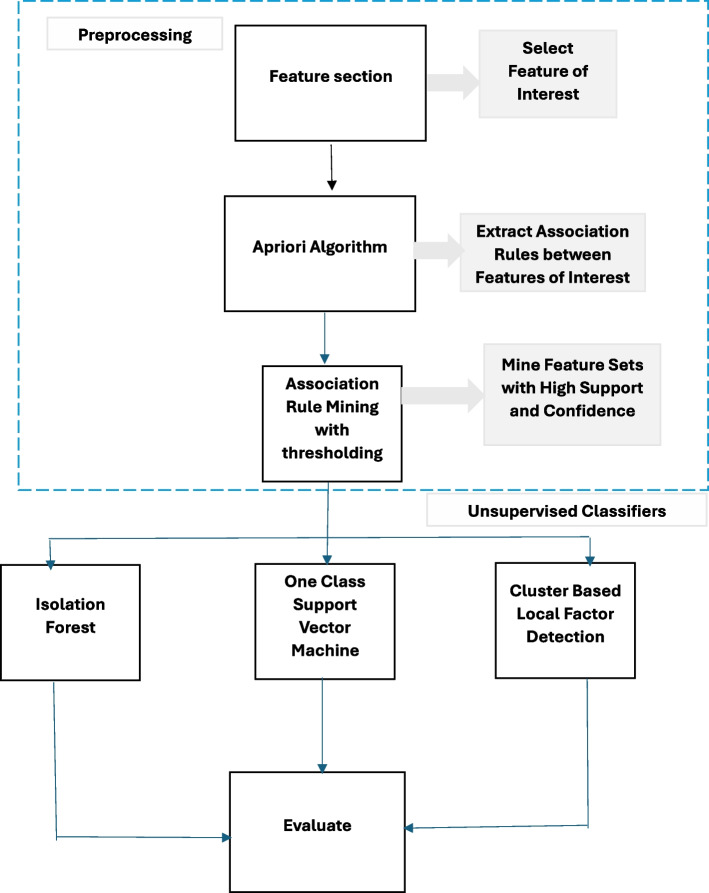
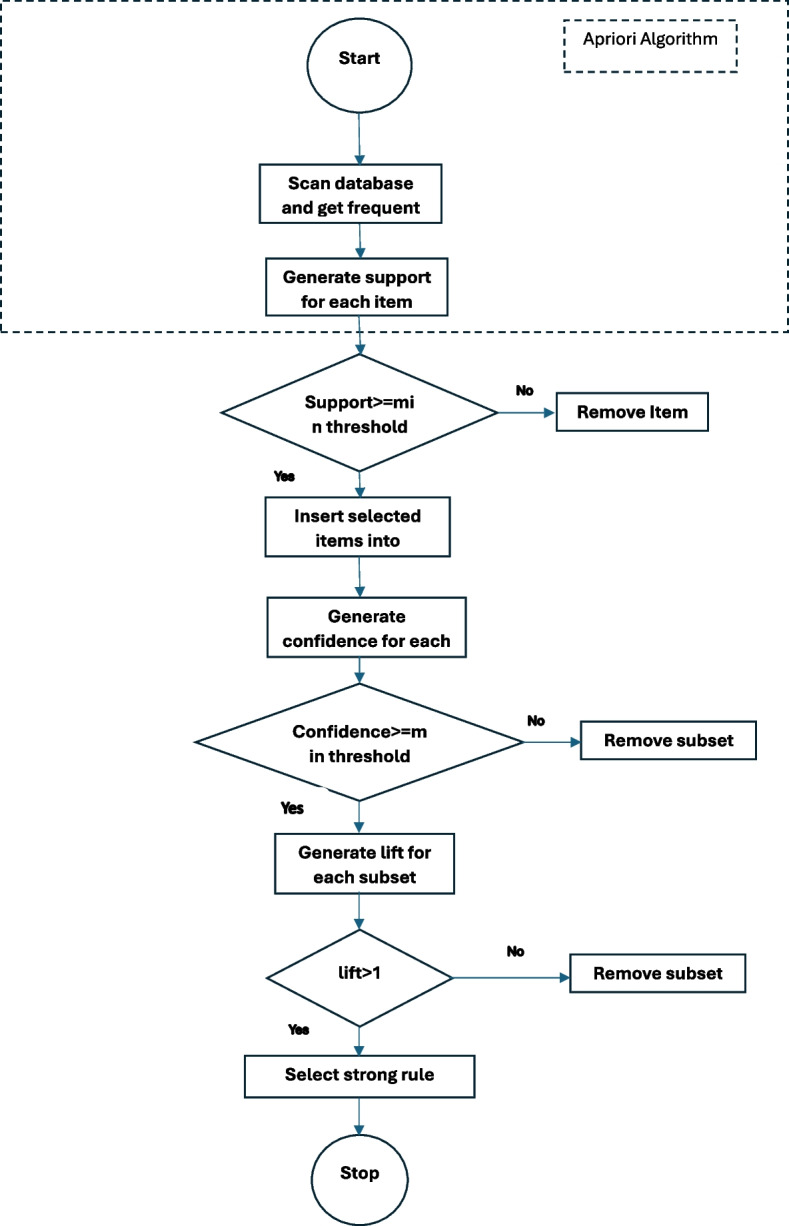
In this study, a fraud detection methodology is presented that utilizes association rule mining augmented with unsupervised learning techniques to detect healthcare insurance fraud. Dataset from the Centres for Medicare and Medicaid Services (CMS) 2008-2010 DE-SynPUF is used for analysis. The proposed methodology works in two stages. First, association rule mining is used to extract frequent rules from the transactions based on patient, service and service provider features. Second, the extracted rules are passed to unsupervised classifiers, such as IF, CBLOF, ECOD, and OCSVM, to identify fraudulent activity.
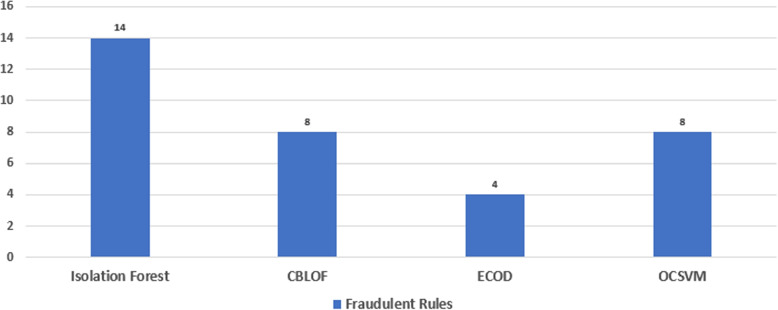
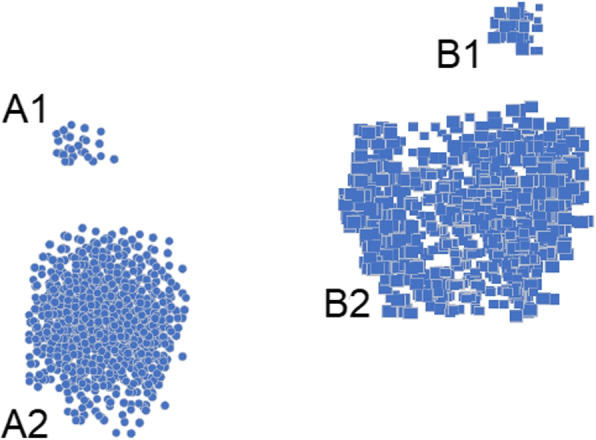
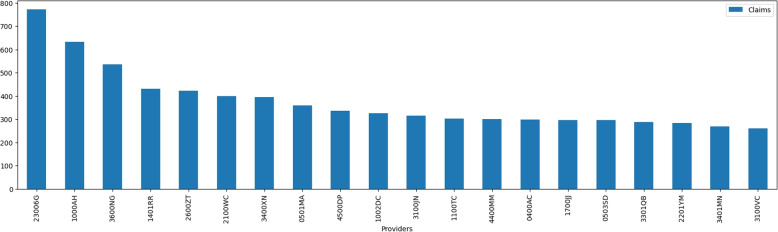
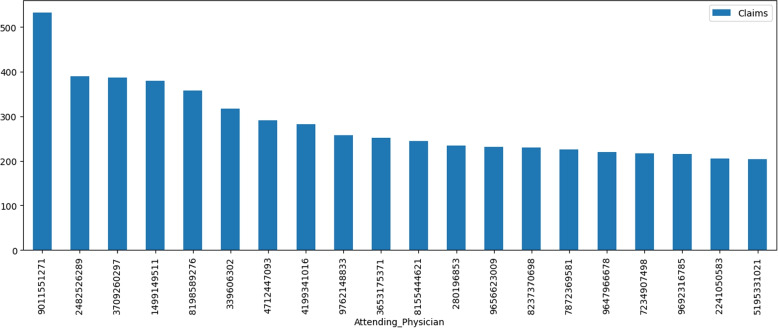
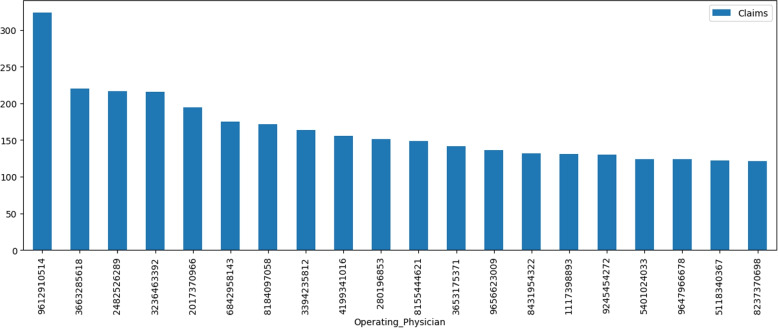
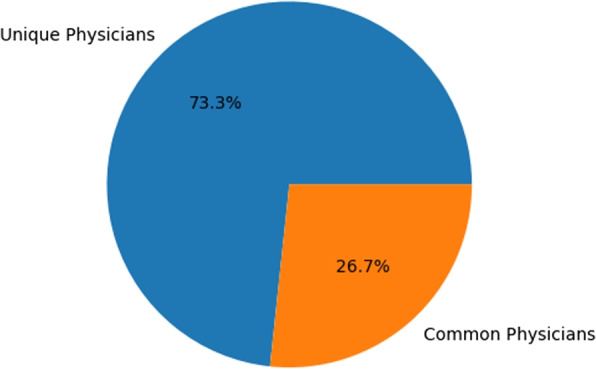
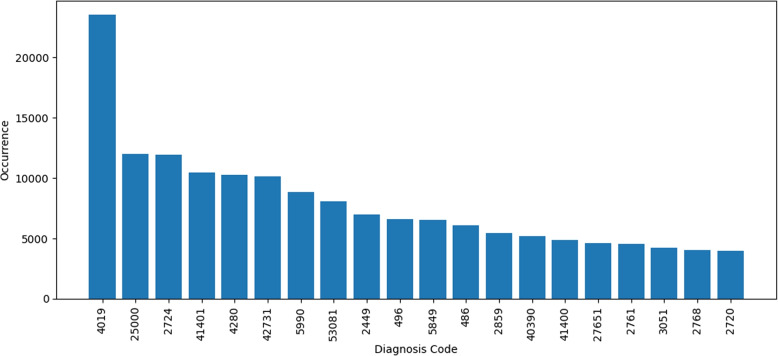
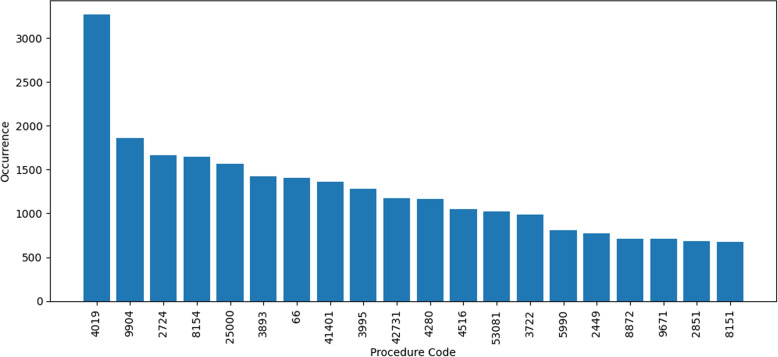
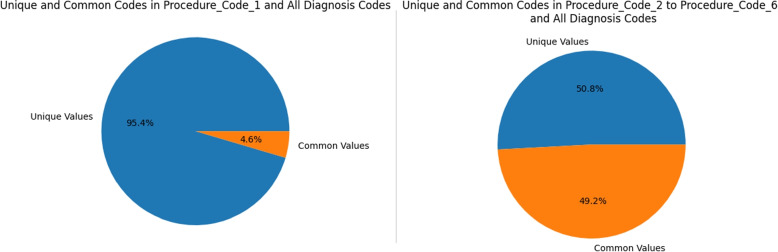
Descriptive analysis shows patterns and trends in the data revealing interesting relationship among diagnosis codes, procedure codes and the physicians. The baseline anomaly detection algorithms generated results in 902.24 seconds. Another experiment retrieved frequent rules using association rule mining with apriori algorithm combined with unsupervised techniques in 868.18 seconds. The silhouette scoring method calculated the efficacy of four different anomaly detection techniques showing CBLOF with highest score of 0.114 followed by isolation forest with the score of 0.103. The ECOD and OCSVM techniques have lower scores of 0.063 and 0.060, respectively.
The proposed methodology enhances healthcare insurance fraud detection by using association rule mining for pattern discovery and unsupervised classifiers for effective anomaly detection.
医疗保健项目和保险举措在确保人们能够获得医疗服务方面发挥着关键作用。医疗保险项目有诸多益处,但医疗保健领域的欺诈行为仍是保险行业面临的重大挑战。医疗保险欺诈检测面临着不断演变且复杂的欺诈计划带来的挑战,这些欺诈计划会适应检测方法。分析大量医疗保健数据受到复杂性、数据质量问题以及实时检测需求的阻碍,而隐私问题和误报则带来了额外的障碍。编码缺乏标准化以及资源有限,进一步使有效应对欺诈活动的努力变得复杂。
在本研究中,提出了一种欺诈检测方法,该方法利用关联规则挖掘并结合无监督学习技术来检测医疗保险欺诈。使用了来自医疗保险和医疗补助服务中心(CMS)2008 - 2010年DE - SynPUF的数据集进行分析。所提出的方法分两个阶段工作。首先,关联规则挖掘用于根据患者、服务和服务提供者特征从交易中提取频繁规则。其次,将提取的规则传递给无监督分类器,如IF、CBLOF、ECOD和OCSVM,以识别欺诈活动。
描述性分析显示了数据中的模式和趋势,揭示了诊断代码、程序代码和医生之间有趣的关系。基线异常检测算法在902.24秒内生成结果。另一个实验使用先验算法结合无监督技术的关联规则挖掘在868.18秒内检索到频繁规则。轮廓评分方法计算了四种不同异常检测技术的功效,显示CBLOF得分最高,为0.114,其次是孤立森林,得分为0.103。ECOD和OCSVM技术得分较低,分别为0.063和0.060。
所提出的方法通过使用关联规则挖掘进行模式发现以及无监督分类器进行有效异常检测,增强了医疗保险欺诈检测能力。