Botdorf Morgan, Dickinson Kimberley, Lorman Vitaly, Razzaghi Hanieh, Marchesani Nicole, Rao Suchitra, Rogerson Colin, Higginbotham Miranda, Mejias Asuncion, Salyakina Daria, Thacker Deepika, Dandachi Dima, Christakis Dimitri A, Taylor Emily, Schwenk Hayden, Morizono Hiroki, Cogen Jonathan, Pajor Nathan M, Jhaveri Ravi, Forrest Christopher B, Bailey L Charles
Applied Clinical Research Center, Children's Hospital of Philadelphia, Philadelphia, PA.
Department of Pediatrics, University of Colorado School of Medicine and Children's Hospital Colorado, Denver, CO.
medRxiv. 2024 Aug 26:2024.05.23.24307492. doi: 10.1101/2024.05.23.24307492.
Long COVID, marked by persistent, recurring, or new symptoms post-COVID-19 infection, impacts children's well-being yet lacks a unified clinical definition. This study evaluates the performance of an empirically derived Long COVID case identification algorithm, or computable phenotype, with manual chart review in a pediatric sample. This approach aims to facilitate large-scale research efforts to understand this condition better.
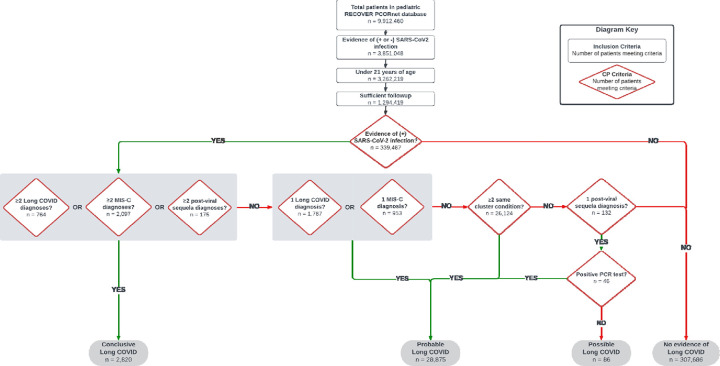
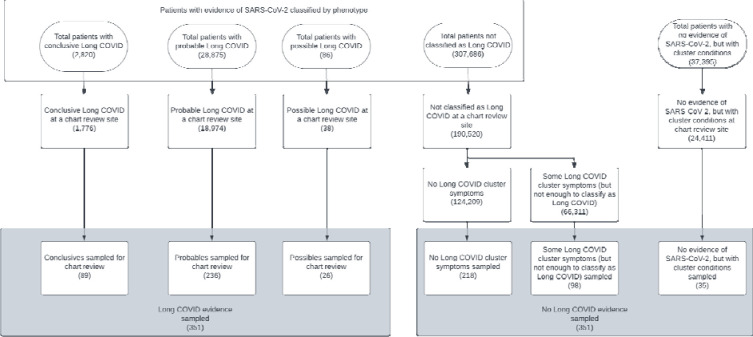
The algorithm, composed of diagnostic codes empirically associated with Long COVID, was applied to a cohort of pediatric patients with SARS-CoV-2 infection in the RECOVER PCORnet EHR database. The algorithm classified 31,781 patients with conclusive, probable, or possible Long COVID and 307,686 patients without evidence of Long COVID. A chart review was performed on a subset of patients (n=651) to determine the overlap between the two methods. Instances of discordance were reviewed to understand the reasons for differences.
The sample comprised 651 pediatric patients (339 females, = 10.10 years) across 16 hospital systems. Results showed moderate overlap between phenotype and chart review Long COVID identification (accuracy = 0.62, PPV = 0.49, NPV = 0.75); however, there were also numerous cases of disagreement. No notable differences were found when the analyses were stratified by age at infection or era of infection. Further examination of the discordant cases revealed that the most common cause of disagreement was the clinician reviewers' tendency to attribute Long COVID-like symptoms to prior medical conditions. The performance of the phenotype improved when prior medical conditions were considered (accuracy = 0.71, PPV = 0.65, NPV = 0.74).
Although there was moderate overlap between the two methods, the discrepancies between the two sources are likely attributed to the lack of consensus on a Long COVID clinical definition. It is essential to consider the strengths and limitations of each method when developing Long COVID classification algorithms.
新冠后长期症状(Long COVID)以新冠病毒感染后持续、反复出现或新发症状为特征,影响儿童健康,但缺乏统一的临床定义。本研究评估了一种通过实证得出的新冠后长期症状病例识别算法(即可计算表型)在儿科样本中与人工病历审查的表现。该方法旨在推动大规模研究工作,以便更好地了解这种情况。
该算法由与新冠后长期症状经验性相关的诊断代码组成,应用于RECOVER PCORnet电子健康记录(EHR)数据库中一组感染了严重急性呼吸综合征冠状病毒2(SARS-CoV-2)的儿科患者。该算法将31781例确诊、可能或疑似新冠后长期症状患者与307686例无新冠后长期症状证据的患者进行了分类。对一部分患者(n = 651)进行了病历审查,以确定两种方法之间的重叠情况。对不一致的情况进行了审查,以了解差异产生的原因。
样本包括来自16个医院系统的651名儿科患者(339名女性,平均年龄 = 10.10岁)。结果显示,表型与病历审查的新冠后长期症状识别之间存在中度重叠(准确率 = 0.62,阳性预测值 = 0.49,阴性预测值 = 0.75);然而,也有许多不一致的情况。按感染时年龄或感染时期分层分析时,未发现显著差异。对不一致病例的进一步检查发现,最常见的分歧原因是临床审查人员倾向于将类似新冠后长期症状的症状归因于既往疾病。考虑既往疾病后,表型的表现有所改善(准确率 = 0.71,阳性预测值 = 0.65,阴性预测值 = 0.74)。
虽然两种方法之间存在中度重叠,但两种来源之间的差异可能归因于对新冠后长期症状临床定义缺乏共识。在开发新冠后长期症状分类算法时,必须考虑每种方法的优点和局限性。