Nisanova Arina, Yavary Arefeh, Deaner Jordan, Ali Ferhina S, Gogte Priyanka, Kaplan Richard, Chen Kevin C, Nudleman Eric, Grewal Dilraj, Gupta Meenakashi, Wolfe Jeremy, Klufas Michael, Yiu Glenn, Soltani Iman, Emami-Naeini Parisa
School of Medicine, University of California Davis, Davis, California.
Department of Computer Science, University of California Davis, Davis, California.
Ophthalmol Sci. 2024 Jan 19;4(5):100470. doi: 10.1016/j.xops.2024.100470. eCollection 2024 Sep-Oct.
Automated machine learning (AutoML) has emerged as a novel tool for medical professionals lacking coding experience, enabling them to develop predictive models for treatment outcomes. This study evaluated the performance of AutoML tools in developing models predicting the success of pneumatic retinopexy (PR) in treatment of rhegmatogenous retinal detachment (RRD). These models were then compared with custom models created by machine learning (ML) experts.
Retrospective multicenter study.
Five hundred and thirty nine consecutive patients with primary RRD that underwent PR by a vitreoretinal fellow at 6 training hospitals between 2002 and 2022.
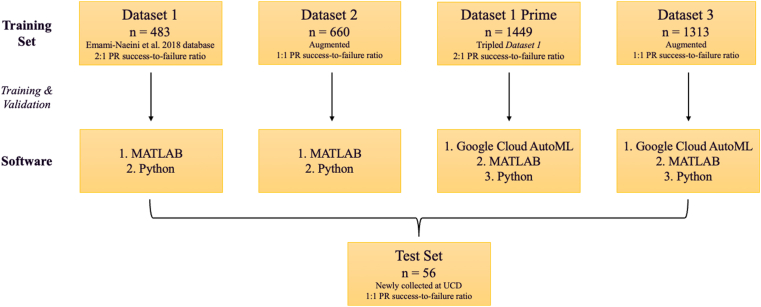
We used 2 AutoML platforms: MATLAB Classification Learner and Google Cloud AutoML. Additional models were developed by computer scientists. We included patient demographics and baseline characteristics, including lens and macula status, RRD size, number and location of breaks, presence of vitreous hemorrhage and lattice degeneration, and physicians' experience. The dataset was split into a training (n = 483) and test set (n = 56). The training set, with a 2:1 success-to-failure ratio, was used to train the MATLAB models. Because Google Cloud AutoML requires a minimum of 1000 samples, the training set was tripled to create a new set with 1449 datapoints. Additionally, balanced datasets with a 1:1 success-to-failure ratio were created using Python.
Single-procedure anatomic success rate, as predicted by the ML models. F2 scores and area under the receiver operating curve (AUROC) were used as primary metrics to compare models.
The best performing AutoML model (F2 score: 0.85; AUROC: 0.90; MATLAB), showed comparable performance to the custom model (0.92, 0.86) when trained on the balanced datasets. However, training the AutoML model with imbalanced data yielded misleadingly high AUROC (0.81) despite low F2-score (0.2) and sensitivity (0.17).
We demonstrated the feasibility of using AutoML as an accessible tool for medical professionals to develop models from clinical data. Such models can ultimately aid in the clinical decision-making, contributing to better patient outcomes. However, outcomes can be misleading or unreliable if used naively. Limitations exist, particularly if datasets contain missing variables or are highly imbalanced. Proper model selection and data preprocessing can improve the reliability of AutoML tools.
Proprietary or commercial disclosure may be found in the Footnotes and Disclosures at the end of this article.
自动机器学习(AutoML)已成为缺乏编码经验的医学专业人员的一种新型工具,使他们能够开发用于预测治疗结果的预测模型。本研究评估了AutoML工具在开发预测气性视网膜固定术(PR)治疗孔源性视网膜脱离(RRD)成功率模型方面的性能。然后将这些模型与机器学习(ML)专家创建的定制模型进行比较。
回顾性多中心研究。
2002年至2022年期间,6家培训医院的539例连续接受玻璃体视网膜专科医生进行PR治疗的原发性RRD患者。
我们使用了2个AutoML平台:MATLAB分类学习器和谷歌云AutoML。计算机科学家开发了其他模型。我们纳入了患者的人口统计学和基线特征,包括晶状体和黄斑状态、RRD大小、裂孔数量和位置、玻璃体出血和格子样变性的存在情况以及医生的经验。数据集被分为训练集(n = 483)和测试集(n = 56)。训练集以2:1的成功与失败比例用于训练MATLAB模型。由于谷歌云AutoML至少需要1000个样本,因此将训练集增加两倍以创建一个包含1449个数据点的新集。此外,使用Python创建了成功与失败比例为1:1的平衡数据集。
ML模型预测的单次手术解剖成功率。F2分数和受试者工作特征曲线下面积(AUROC)用作比较模型的主要指标。
表现最佳的AutoML模型(F2分数:0.85;AUROC:0.90;MATLAB)在平衡数据集上训练时,与定制模型(0.92,0.86)表现相当。然而,使用不平衡数据训练AutoML模型时,尽管F2分数低(0.2)和灵敏度低(0.17),但AUROC却高得出人意料(0.81)。
我们证明了使用AutoML作为医学专业人员从临床数据开发模型的一种可及工具的可行性。此类模型最终可有助于临床决策,为改善患者预后做出贡献。然而,如果盲目使用,结果可能会产生误导或不可靠。存在局限性,特别是如果数据集包含缺失变量或高度不平衡。正确的模型选择和数据预处理可以提高AutoML工具的可靠性。
在本文末尾的脚注和披露中可能会找到专有或商业披露信息。