Abdullahi Tassallah, Mercurio Laura, Singh Ritambhara, Eickhoff Carsten
Department of Computer Science, Brown University, Providence, RI, United States.
Departments of Pediatrics & Emergency Medicine, Alpert Medical School, Brown University, Providence, RI, United States.
JMIR Med Inform. 2024 Jun 19;12:e50209. doi: 10.2196/50209.
Diagnostic errors pose significant health risks and contribute to patient mortality. With the growing accessibility of electronic health records, machine learning models offer a promising avenue for enhancing diagnosis quality. Current research has primarily focused on a limited set of diseases with ample training data, neglecting diagnostic scenarios with limited data availability.
This study aims to develop an information retrieval (IR)-based framework that accommodates data sparsity to facilitate broader diagnostic decision support.
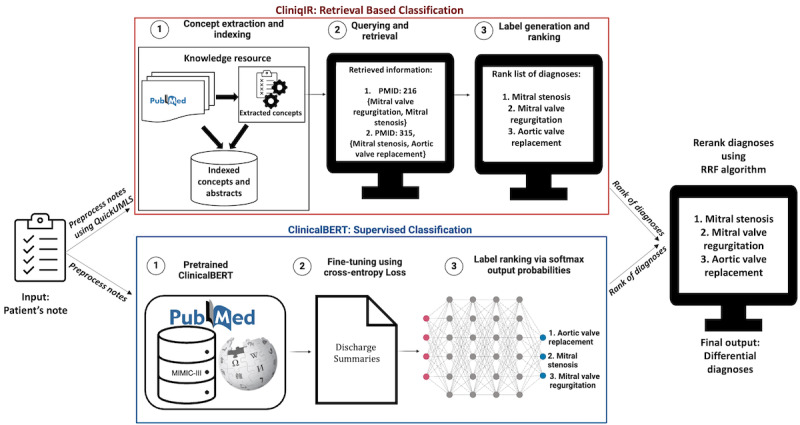
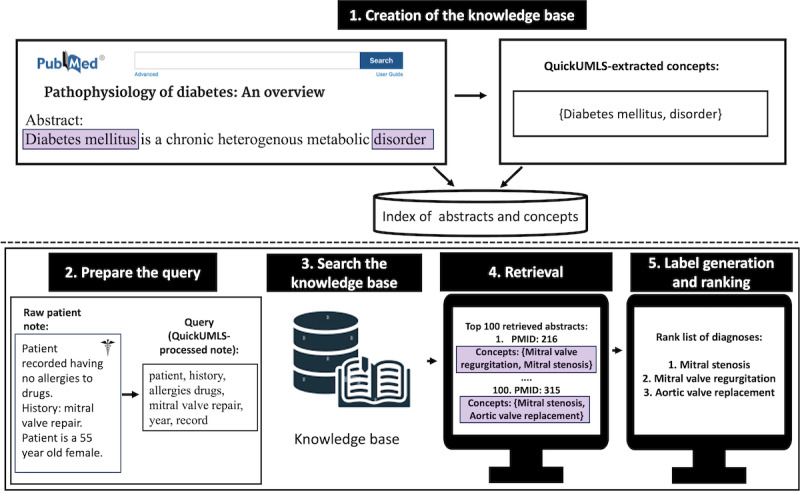
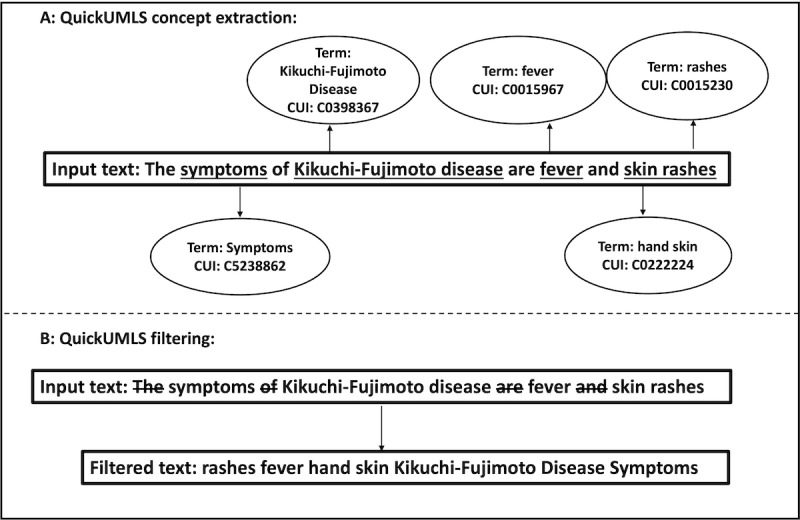
We introduced an IR-based diagnostic decision support framework called CliniqIR. It uses clinical text records, the Unified Medical Language System Metathesaurus, and 33 million PubMed abstracts to classify a broad spectrum of diagnoses independent of training data availability. CliniqIR is designed to be compatible with any IR framework. Therefore, we implemented it using both dense and sparse retrieval approaches. We compared CliniqIR's performance to that of pretrained clinical transformer models such as Clinical Bidirectional Encoder Representations from Transformers (ClinicalBERT) in supervised and zero-shot settings. Subsequently, we combined the strength of supervised fine-tuned ClinicalBERT and CliniqIR to build an ensemble framework that delivers state-of-the-art diagnostic predictions.
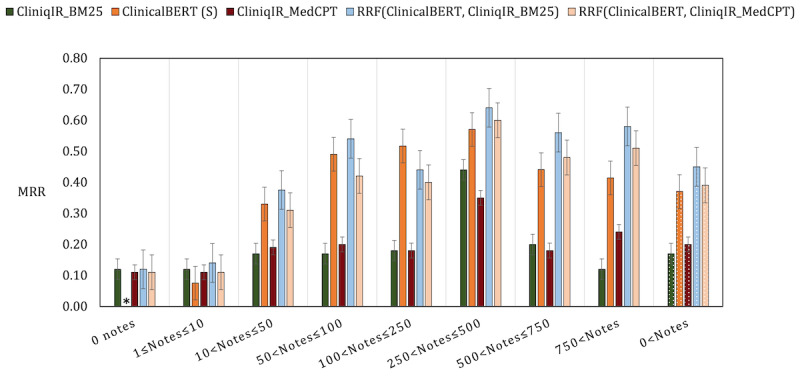
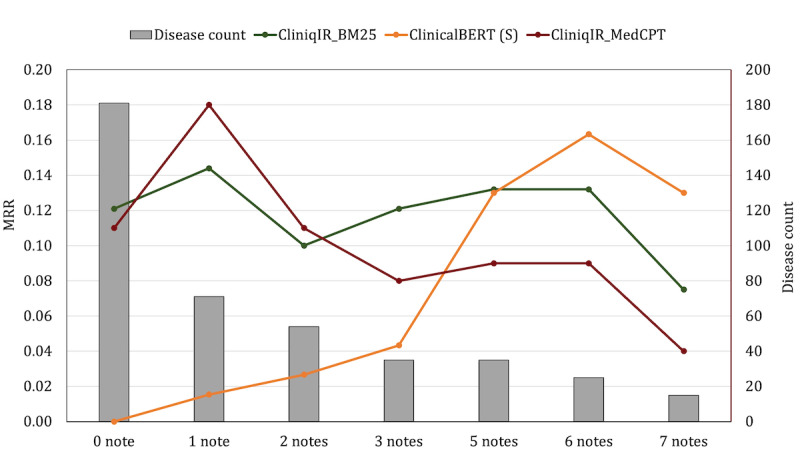
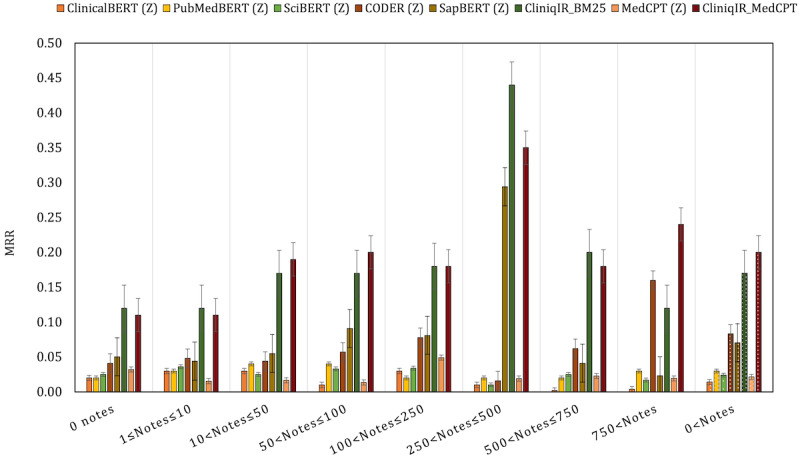
On a complex diagnosis data set (DC3) without any training data, CliniqIR models returned the correct diagnosis within their top 3 predictions. On the Medical Information Mart for Intensive Care III data set, CliniqIR models surpassed ClinicalBERT in predicting diagnoses with <5 training samples by an average difference in mean reciprocal rank of 0.10. In a zero-shot setting where models received no disease-specific training, CliniqIR still outperformed the pretrained transformer models with a greater mean reciprocal rank of at least 0.10. Furthermore, in most conditions, our ensemble framework surpassed the performance of its individual components, demonstrating its enhanced ability to make precise diagnostic predictions.
Our experiments highlight the importance of IR in leveraging unstructured knowledge resources to identify infrequently encountered diagnoses. In addition, our ensemble framework benefits from combining the complementary strengths of the supervised and retrieval-based models to diagnose a broad spectrum of diseases.
诊断错误会带来重大健康风险并导致患者死亡。随着电子健康记录的获取日益便捷,机器学习模型为提高诊断质量提供了一条有前景的途径。当前研究主要集中在有充足训练数据的有限疾病集上,而忽略了数据可用性有限的诊断场景。
本研究旨在开发一种基于信息检索(IR)的框架,该框架能够适应数据稀疏性,以促进更广泛的诊断决策支持。
我们引入了一个名为CliniqIR的基于IR的诊断决策支持框架。它使用临床文本记录、统一医学语言系统叙词表和3300万篇PubMed摘要,对广泛的诊断进行分类,而不依赖于训练数据的可用性。CliniqIR设计为与任何IR框架兼容。因此,我们使用密集和稀疏检索方法来实现它。我们在监督和零样本设置下,将CliniqIR的性能与预训练的临床变压器模型(如来自变压器的临床双向编码器表示(ClinicalBERT))的性能进行了比较。随后,我们结合了监督微调的ClinicalBERT和CliniqIR的优势,构建了一个能提供最先进诊断预测的集成框架。
在一个没有任何训练数据的复杂诊断数据集(DC3)上,CliniqIR模型在前3个预测中返回了正确的诊断。在重症监护医学信息集市III数据集上,CliniqIR模型在预测训练样本少于5个的诊断时,平均倒数排名的平均差异为0.10,超过了ClinicalBERT。在模型没有接受特定疾病训练的零样本设置中,CliniqIR仍然优于预训练的变压器模型,平均倒数排名至少高0.10。此外,在大多数情况下,我们的集成框架超过了其各个组件的性能,证明了其进行精确诊断预测的增强能力。
我们的实验强调了IR在利用非结构化知识资源识别罕见诊断方面的重要性。此外,我们的集成框架受益于结合基于监督和检索的模型的互补优势,以诊断广泛的疾病。