Pati Abhilash, Panigrahi Amrutanshu, Parhi Manoranjan, Giri Jayant, Qin Hong, Mallik Saurav, Pattanayak Sambit Ranjan, Agrawal Umang Kumar
Department of Computer Science and Engineering, Siksha 'O' Anusandhan (Deemed to be University), Bhubaneswar, Odisha, India.
Centre for Data Science, Siksha 'O' Anusandhan (Deemed to be University), Bhubaneswar, Odisha, India.
PLoS One. 2024 Aug 1;19(8):e0304768. doi: 10.1371/journal.pone.0304768. eCollection 2024.
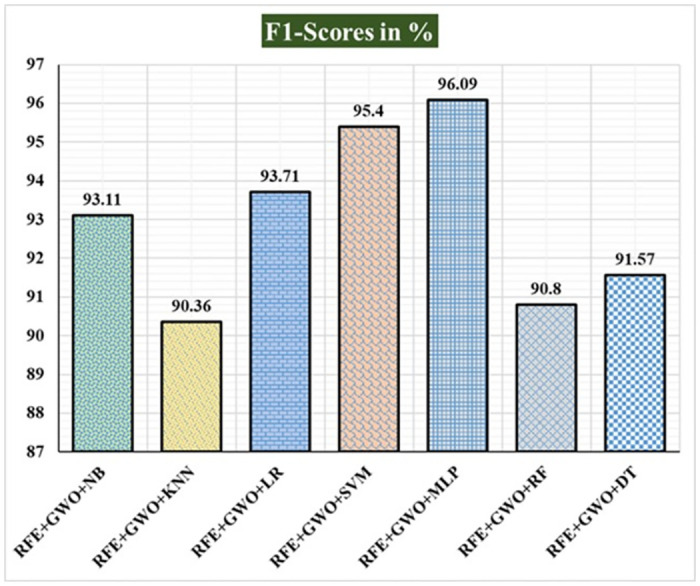
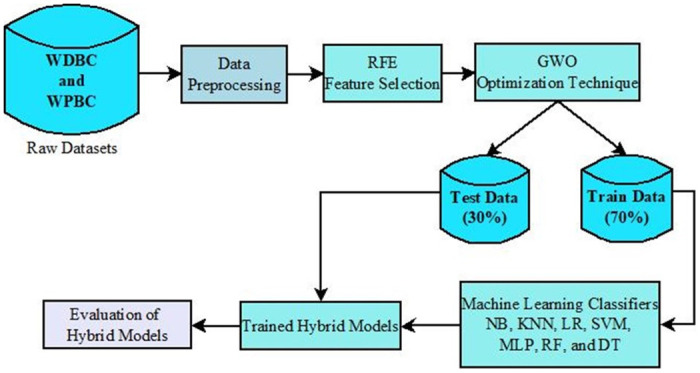
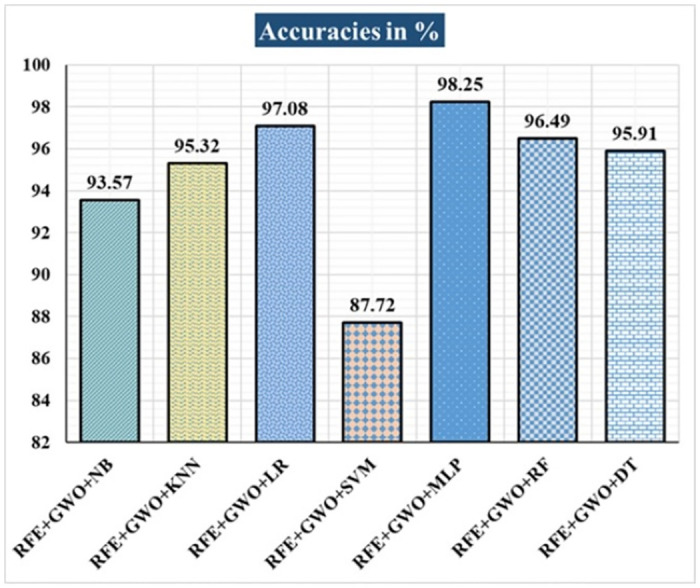
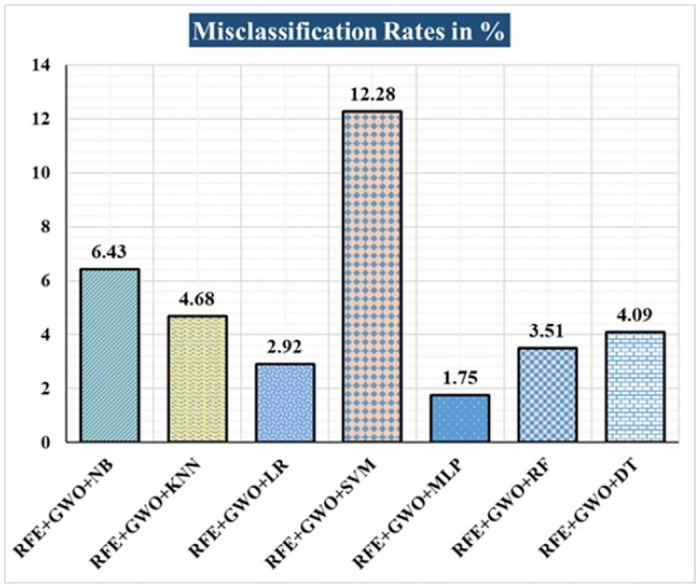
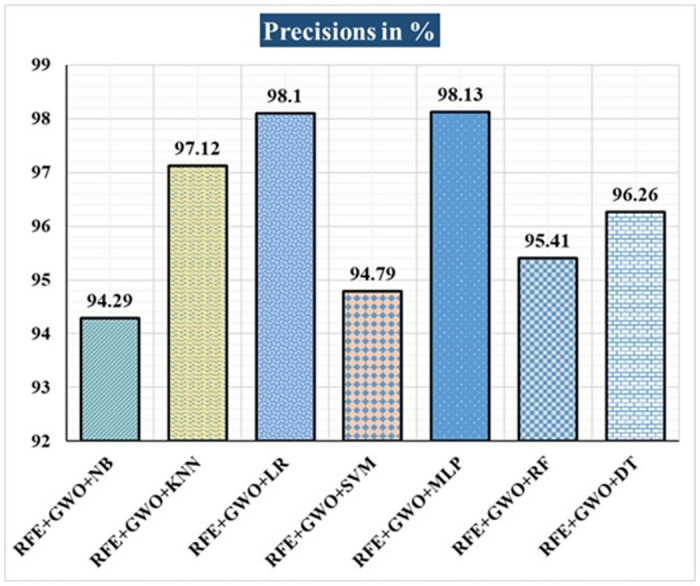
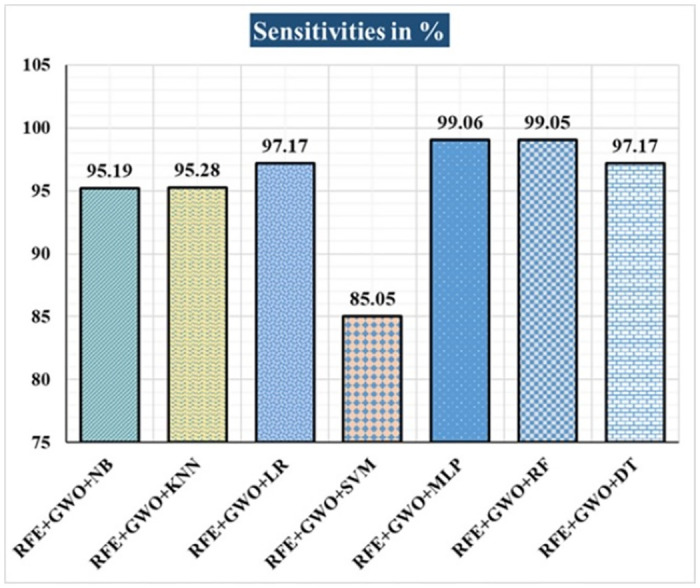
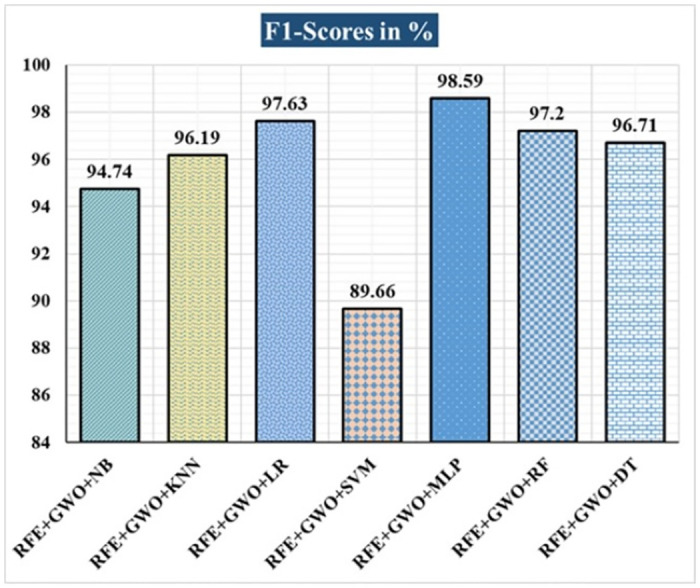
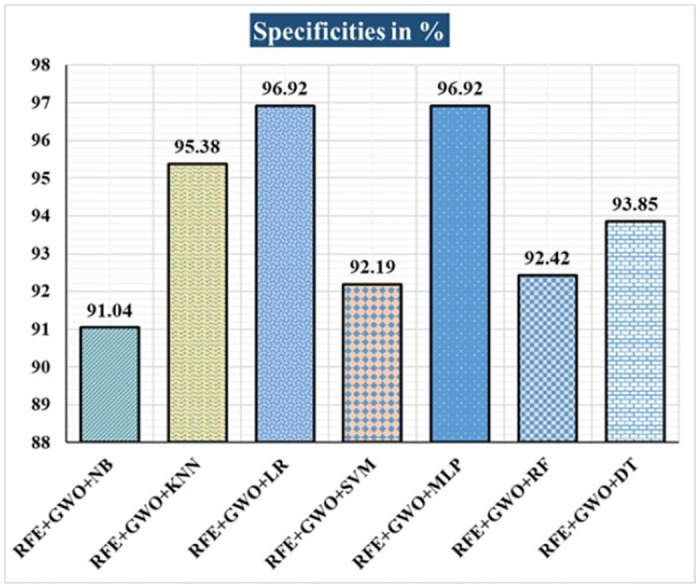
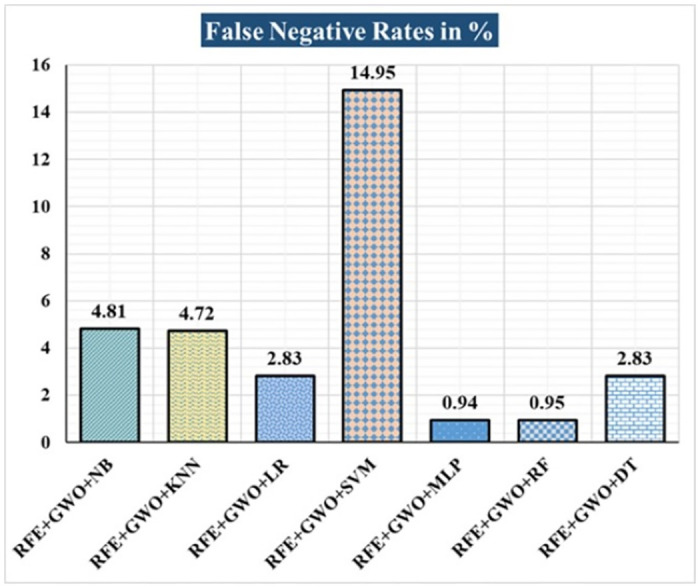
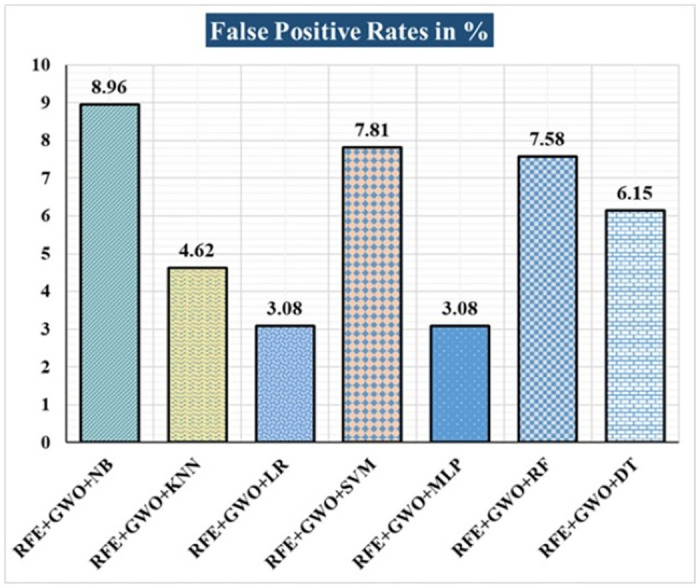
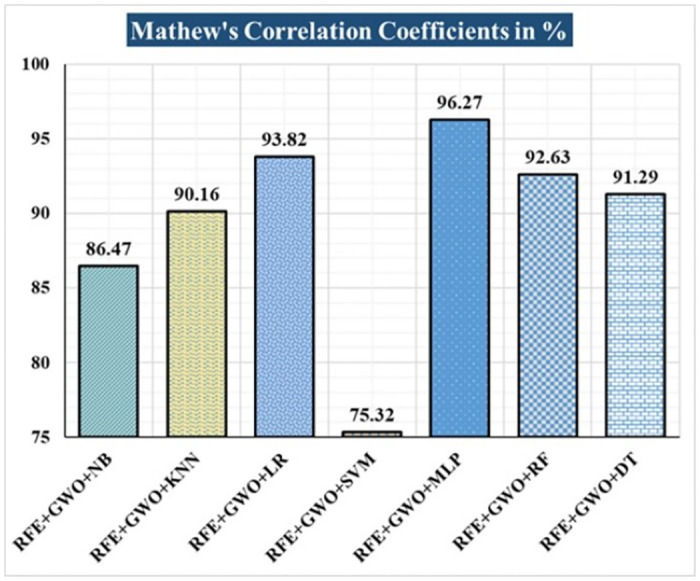
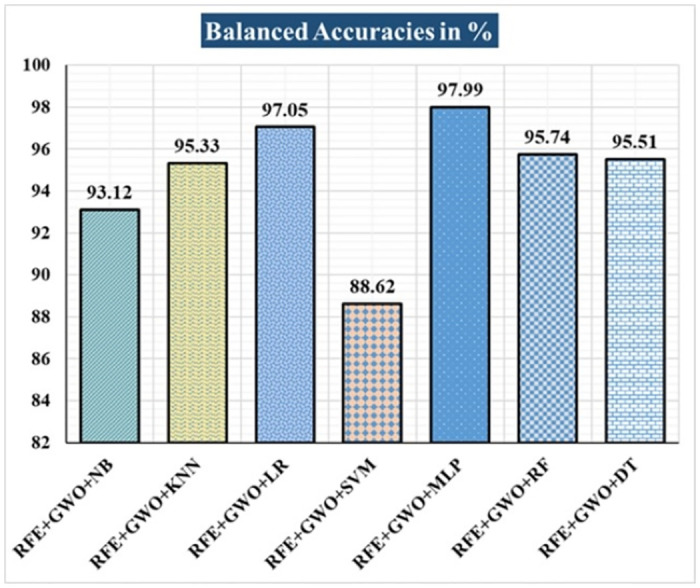
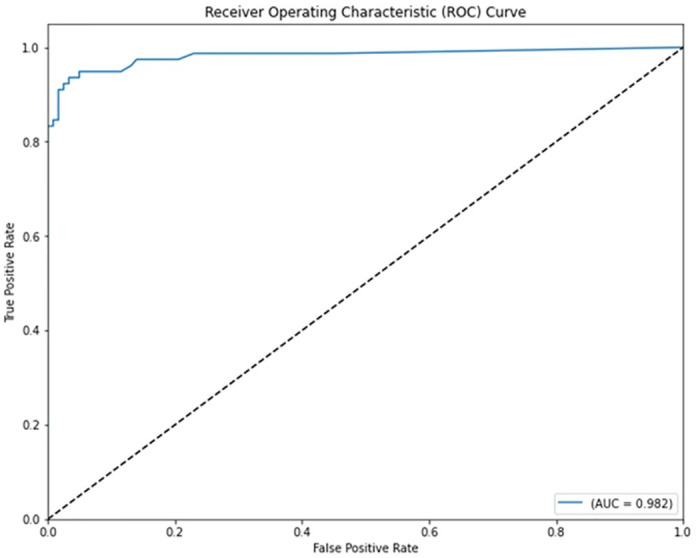
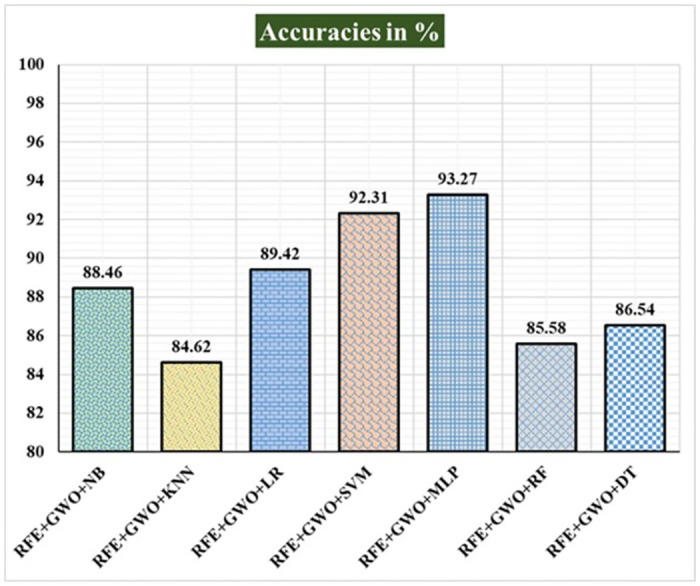
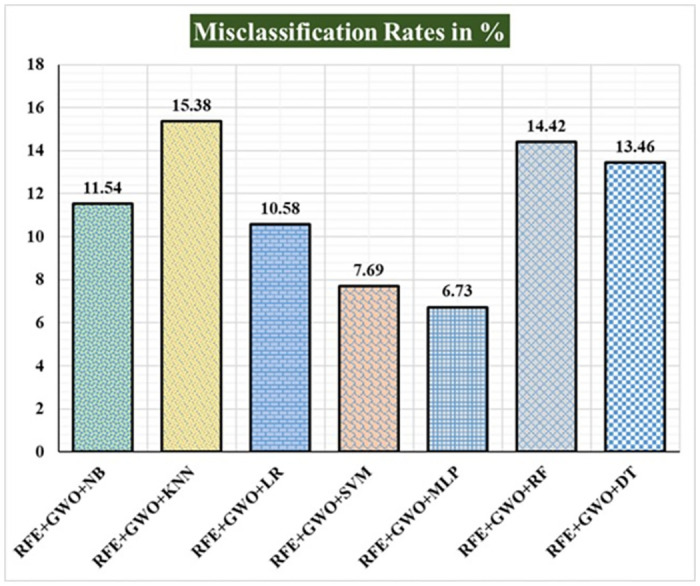
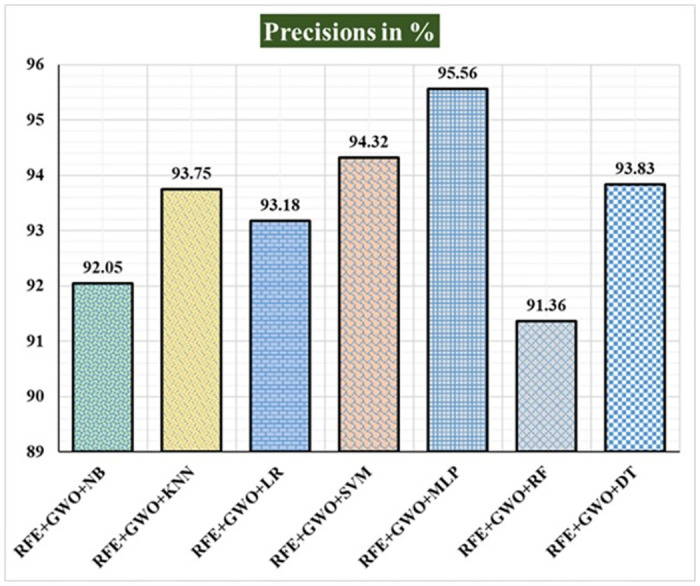
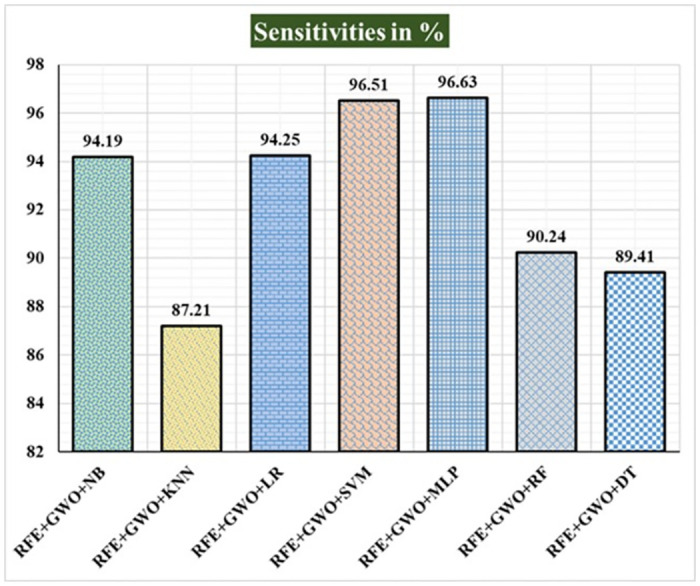
Breast cancer is a major health concern for women everywhere and a major killer of women. Malignant tumors may be distinguished from benign ones, allowing for early diagnosis of this disease. Therefore, doctors need an accurate method of diagnosing tumors as either malignant or benign. Even if therapy begins immediately after diagnosis, some cancer cells may persist in the body, increasing the risk of a recurrence. Metastasis and recurrence are the leading causes of death from breast cancer. Therefore, detecting a return of breast cancer early has become a pressing medical issue. Evaluating and contrasting various Machine Learning (ML) techniques for breast cancer and recurrence prediction is crucial to choosing the best successful method. Inaccurate forecasts are common when using datasets with a large number of attributes. This study addresses the need for effective feature selection and optimization methods by introducing Recursive Feature Elimination (RFE) and Grey Wolf Optimizer (GWO), in response to the limitations observed in existing approaches. In this research, the performance evaluation of methods is enhanced by employing the RFE and GWO, considering the Wisconsin Diagnostic Breast Cancer (WDBC) and Wisconsin Prognostic Breast Cancer (WPBC) datasets taken from the UCI-ML repository. Various preprocessing techniques are applied to raw data, including imputation, scaling, and others. In the second step, relevant feature correlations are used with RFE to narrow down candidate discriminative features. The GWO chooses the best possible combination of attributes for the most accurate result in the next step. We use seven ML classifiers in both datasets to make a binary decision. On the WDBC and WPBC datasets, several experiments have shown accuracies of 98.25% and 93.27%, precisions of 98.13% and 95.56%, sensitivities of 99.06% and 96.63%, specificities of 96.92% and 73.33%, F1-scores of 98.59% and 96.09% and AUCs of 0.982 and 0.936, respectively. The hybrid approach's superior feature selection improved the accuracy of breast cancer performance indicators and recurrence classification.
乳腺癌是世界各地女性主要的健康问题,也是女性的主要杀手。恶性肿瘤可与良性肿瘤区分开来,有助于对这种疾病进行早期诊断。因此,医生需要一种准确的方法来诊断肿瘤是恶性还是良性。即使在诊断后立即开始治疗,体内仍可能存在一些癌细胞,从而增加复发风险。转移和复发是乳腺癌死亡的主要原因。因此,早期检测乳腺癌复发已成为一个紧迫的医学问题。评估和对比用于乳腺癌及复发预测的各种机器学习(ML)技术对于选择最佳成功方法至关重要。使用具有大量属性的数据集时,不准确的预测很常见。本研究针对现有方法中观察到的局限性,通过引入递归特征消除(RFE)和灰狼优化器(GWO),满足了对有效特征选择和优化方法的需求。在本研究中,考虑从UCI-ML库获取的威斯康星诊断乳腺癌(WDBC)和威斯康星预后乳腺癌(WPBC)数据集,通过采用RFE和GWO提高了方法的性能评估。对原始数据应用了各种预处理技术,包括插补、缩放等。第二步,使用RFE进行相关特征关联,以缩小候选判别特征范围。GWO在下一步中选择最佳的属性组合以获得最准确的结果。我们在两个数据集中使用七个ML分类器进行二元决策。在WDBC和WPBC数据集上,多项实验分别显示准确率为98.25%和93.27%,精确率为98.13%和95.56%,灵敏度为99.06%和96.63%,特异性为96.92%和73.33%,F1分数为98.59%和96.09%,AUC分别为0.982和0.936。混合方法卓越的特征选择提高了乳腺癌性能指标和复发分类的准确性。