Core Facility Bioinformatics, Biomedical Center, LMU Munich, Grosshaderner Str. 9, 82152, Martinsried, Germany.
Molecular Biology Division, Biomedical Center, LMU Munich, Grosshaderner Str. 9, 82152, Martinsried, Germany.
BMC Bioinformatics. 2024 Aug 27;25(1):281. doi: 10.1186/s12859-024-05902-7.
Mining the vast pool of biomedical literature to extract accurate responses and relevant references is challenging due to the domain's interdisciplinary nature, specialized jargon, and continuous evolution. Early natural language processing (NLP) approaches often led to incorrect answers as they failed to comprehend the nuances of natural language. However, transformer models have significantly advanced the field by enabling the creation of large language models (LLMs), enhancing question-answering (QA) tasks. Despite these advances, current LLM-based solutions for specialized domains like biology and biomedicine still struggle to generate up-to-date responses while avoiding "hallucination" or generating plausible but factually incorrect responses.
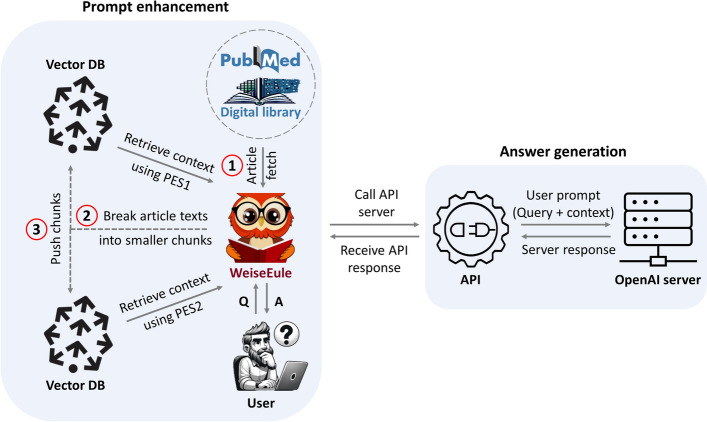
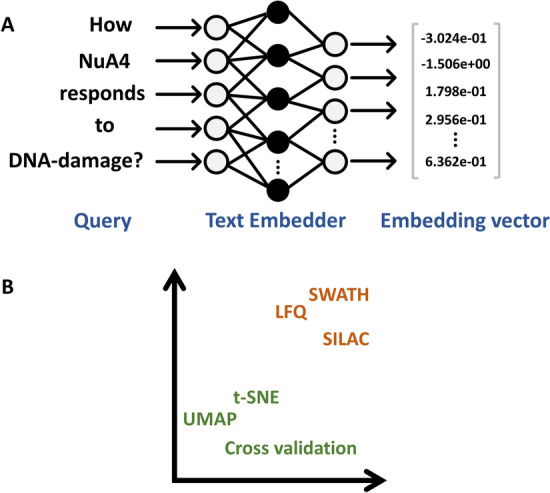
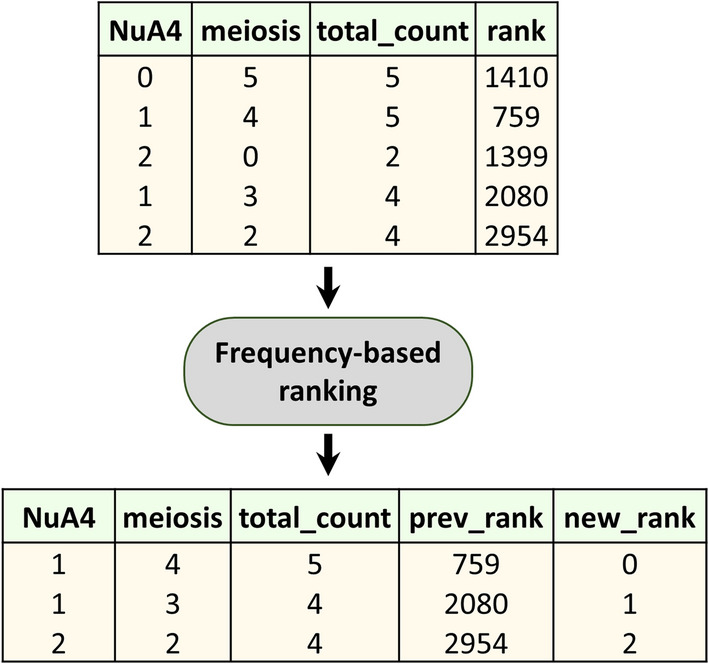
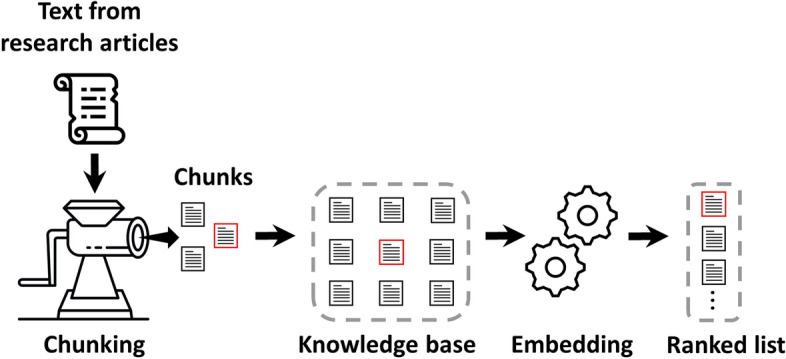
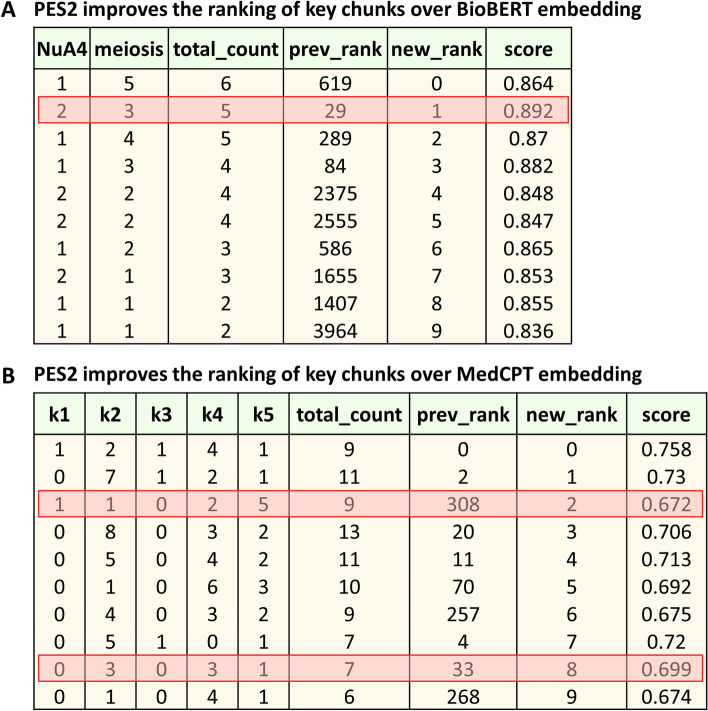
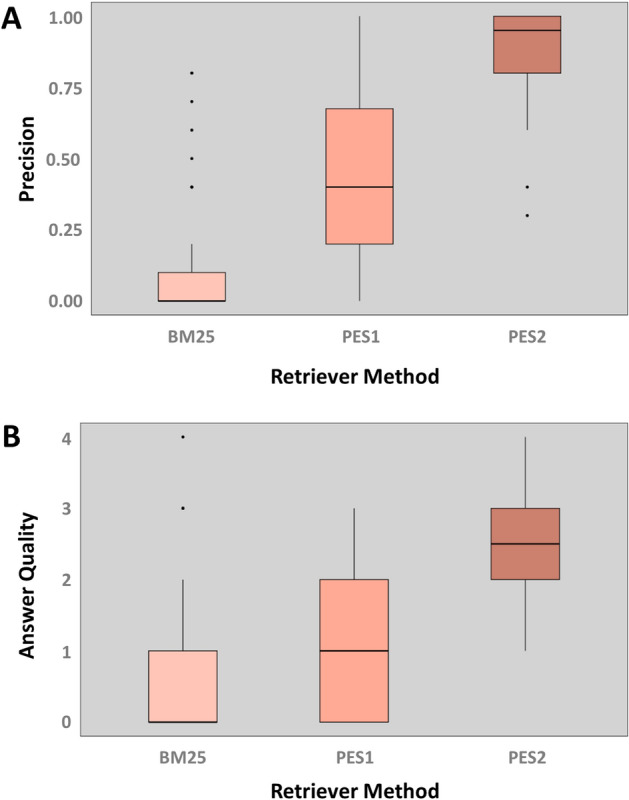
Our work focuses on enhancing prompts using a retrieval-augmented architecture to guide LLMs in generating meaningful responses for biomedical QA tasks. We evaluated two approaches: one relying on text embedding and vector similarity in a high-dimensional space, and our proposed method, which uses explicit signals in user queries to extract meaningful contexts. For robust evaluation, we tested these methods on 50 specific and challenging questions from diverse biomedical topics, comparing their performance against a baseline model, BM25. Retrieval performance of our method was significantly better than others, achieving a median Precision@10 of 0.95, which indicates the fraction of the top 10 retrieved chunks that are relevant. We used GPT-4, OpenAI's most advanced LLM to maximize the answer quality and manually accessed LLM-generated responses. Our method achieved a median answer quality score of 2.5, surpassing both the baseline model and the text embedding-based approach. We developed a QA bot, WeiseEule ( https://github.com/wasimaftab/WeiseEule-LocalHost ), which utilizes these methods for comparative analysis and also offers advanced features for review writing and identifying relevant articles for citation.
Our findings highlight the importance of prompt enhancement methods that utilize explicit signals in user queries over traditional text embedding-based approaches to improve LLM-generated responses for specialized queries in specialized domains such as biology and biomedicine. By providing users complete control over the information fed into the LLM, our approach addresses some of the major drawbacks of existing web-based chatbots and LLM-based QA systems, including hallucinations and the generation of irrelevant or outdated responses.
由于生物医学领域的跨学科性质、专业术语和不断发展,从大量生物医学文献中提取准确的答案和相关参考文献具有挑战性。早期的自然语言处理 (NLP) 方法往往会导致错误的答案,因为它们无法理解自然语言的细微差别。然而,转换器模型通过创建大型语言模型 (LLM),极大地推进了这个领域,增强了问答 (QA) 任务。尽管取得了这些进展,但当前基于 LLM 的生物学和生物医学等专业领域的解决方案仍然难以生成最新的答案,同时避免“幻觉”或生成合理但事实上错误的答案。
我们的工作重点是使用检索增强架构来增强提示,以指导 LLM 为生物医学 QA 任务生成有意义的答案。我们评估了两种方法:一种依赖于高维空间中的文本嵌入和向量相似度,另一种是我们提出的方法,该方法使用用户查询中的显式信号来提取有意义的上下文。为了进行稳健的评估,我们在来自不同生物医学主题的 50 个具体而具有挑战性的问题上测试了这些方法,将它们的性能与基线模型 BM25 进行了比较。我们的方法的检索性能明显优于其他方法,在 10 个检索到的块中,相关块的比例达到了中位数 0.95。我们使用 OpenAI 最先进的 LLM GPT-4 来最大化答案质量,并手动访问 LLM 生成的答案。我们的方法达到了中位数 2.5 的答案质量得分,超过了基线模型和基于文本嵌入的方法。我们开发了一个 QA 机器人 WeiseEule(https://github.com/wasimaftab/WeiseEule-LocalHost),它利用这些方法进行比较分析,并提供了用于评论撰写和识别相关引文的高级功能。
我们的研究结果强调了在用户查询中使用显式信号而不是传统基于文本嵌入的方法来增强提示的重要性,这可以改善生物学和生物医学等专业领域中针对专业查询的 LLM 生成的答案。通过为用户提供对输入到 LLM 的信息的完全控制,我们的方法解决了现有基于网络的聊天机器人和基于 LLM 的 QA 系统的一些主要缺点,包括幻觉和生成不相关或过时的答案。