Center for Innovations in Quality, Effectiveness, and Safety, Michael E. DeBakey VA Medical Center, Houston, TX, USA.
Department of Medicine, Baylor College of Medicine, Houston, TX, USA.
Cancer Control. 2024 Jan-Dec;31:10732748241279518. doi: 10.1177/10732748241279518.
Performance status (PS), an essential indicator of patients' functional abilities, is often documented in clinical notes of patients with cancer. The use of natural language processing (NLP) in extracting PS from electronic medical records (EMRs) has shown promise in enhancing clinical decision-making, patient monitoring, and research studies. We designed and validated a multi-institute NLP pipeline to automatically extract performance status from free-text patient notes.
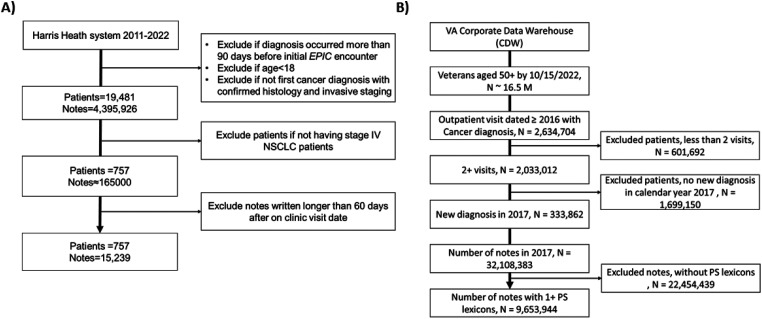
We collected data from 19,481 patients in Harris Health System (HHS) and 333,862 patients from veteran affair's corporate data warehouse (VA-CDW) and randomly selected 400 patients from each data source to train and validate (50%) and test (50%) the proposed pipeline. We designed an NLP pipeline using an expert-derived rule-based approach in conjunction with extensive post-processing to solidify its proficiency. To demonstrate the pipeline's application, we tested the compliance of PS documentation suggested by the American Society of Clinical Oncology (ASCO) Quality Metric and investigated the potential disparity in PS reporting for stage IV non-small cell lung cancer (NSCLC). We used a logistic regression test, considering patients in terms of race/ethnicity, conversing language, marital status, and gender.
The test results on the HHS cohort showed 92% accuracy, and on VA data demonstrated 98.5% accuracy. For stage IV NSCLC patients, the proposed pipeline achieved an accuracy of 98.5%. Furthermore, our analysis revealed a documentation rate of over 85% for PS among NSCLC patients, surpassing the ASCO Quality Metrics. No disparities were observed in the documentation of PS.
Our proposed NLP pipeline shows promising results in extracting PS from free-text notes from various health institutions. It may be used in longitudinal cancer data registries.
体能状态(PS)是评估患者功能能力的重要指标,通常在癌症患者的临床病历中记录。自然语言处理(NLP)在从电子病历(EMR)中提取 PS 方面的应用显示出了在增强临床决策、患者监测和研究方面的潜力。我们设计并验证了一个多机构的 NLP 管道,以自动从患者病历的自由文本中提取体能状态。
我们从哈里斯健康系统(HHS)中收集了 19481 名患者的数据,从退伍军人事务公司数据仓库(VA-CDW)中收集了 333862 名患者的数据,并从每个数据源中随机选择 400 名患者用于训练和验证(50%)和测试(50%)所提出的管道。我们使用了一种专家推导的基于规则的方法设计了一个 NLP 管道,并结合了广泛的后处理来增强其专业性。为了展示该管道的应用,我们测试了美国临床肿瘤学会(ASCO)质量指标建议的 PS 文档的一致性,并调查了 IV 期非小细胞肺癌(NSCLC)患者 PS 报告中的潜在差异。我们使用逻辑回归测试,考虑了患者的种族/民族、交谈语言、婚姻状况和性别。
在 HHS 队列中的测试结果显示准确率为 92%,在 VA 数据中的准确率为 98.5%。对于 IV 期 NSCLC 患者,该管道的准确率为 98.5%。此外,我们的分析显示,NSCLC 患者的 PS 记录率超过 85%,超过了 ASCO 质量指标。在 PS 的记录方面没有发现差异。
我们提出的 NLP 管道在从各种医疗机构的自由文本记录中提取 PS 方面显示出了有前景的结果。它可用于纵向癌症数据登记处。