Strzalkowski Piotr, Strzalkowska Alicja, Chhablani Jay, Pfau Kristina, Errera Marie-Hélène, Roth Mathias, Schaub Friederike, Bechrakis Nikolaos E, Hoerauf Hans, Reiter Constantin, Schuster Alexander K, Geerling Gerd, Guthoff Rainer
Department of Ophthalmology, Medical Faculty and University Hospital Düsseldorf - Heinrich Heine University Düsseldorf, Düsseldorf, Germany.
UPMC Eye Center, University of Pittsburgh, Pittsburgh, PA, USA.
Int J Retina Vitreous. 2024 Sep 2;10(1):61. doi: 10.1186/s40942-024-00579-9.
Large language models (LLMs) such as ChatGPT-4 and Google Gemini show potential for patient health education, but concerns about their accuracy require careful evaluation. This study evaluates the readability and accuracy of ChatGPT-4 and Google Gemini in answering questions about retinal detachment.
Comparative study analyzing responses from ChatGPT-4 and Google Gemini to 13 retinal detachment questions, categorized by difficulty levels (D1, D2, D3). Masked responses were reviewed by ten vitreoretinal specialists and rated on correctness, errors, thematic accuracy, coherence, and overall quality grading. Analysis included Flesch Readability Ease Score, word and sentence counts.
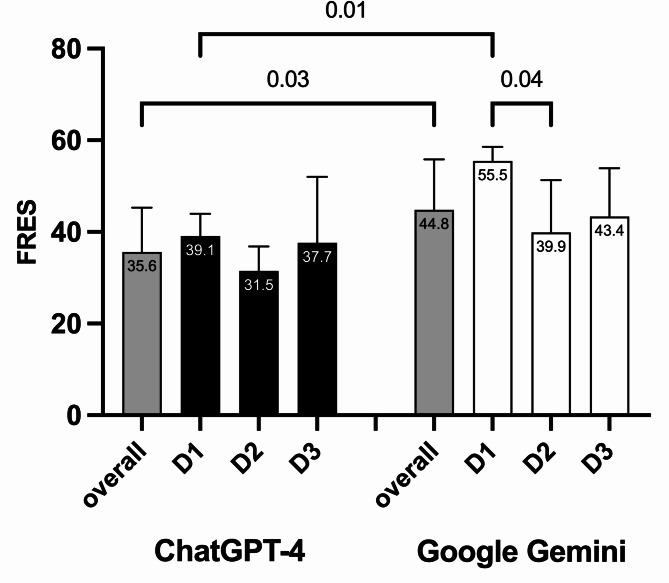
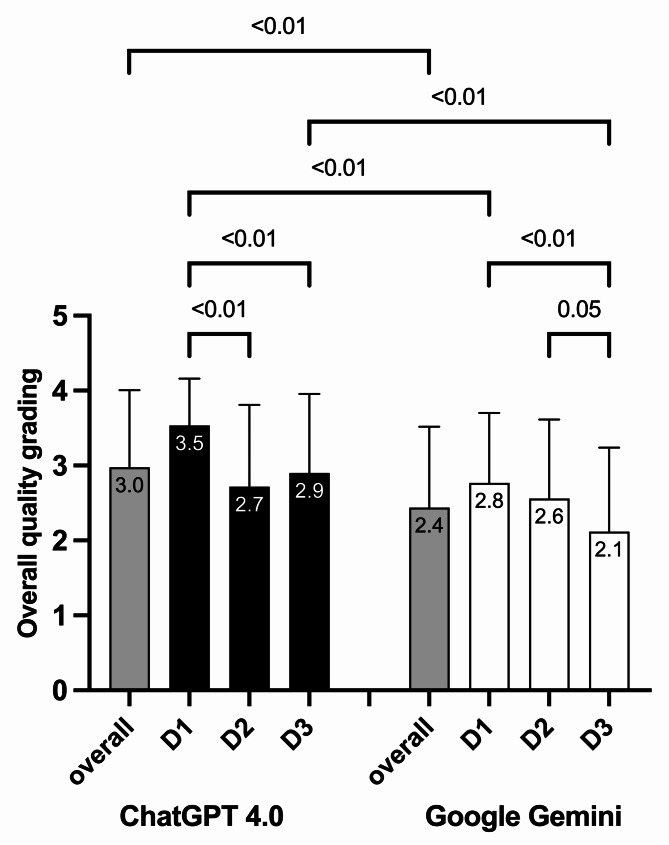
Both Artificial Intelligence tools required college-level understanding for all difficulty levels. Google Gemini was easier to understand (p = 0.03), while ChatGPT-4 provided more correct answers for the more difficult questions (p = 0.0005) with fewer serious errors. ChatGPT-4 scored highest on most challenging questions, showing superior thematic accuracy (p = 0.003). ChatGPT-4 outperformed Google Gemini in 8 of 13 questions, with higher overall quality grades in the easiest (p = 0.03) and hardest levels (p = 0.0002), showing a lower grade as question difficulty increased.
ChatGPT-4 and Google Gemini effectively address queries about retinal detachment, offering mostly accurate answers with few critical errors, though patients require higher education for comprehension. The implementation of AI tools may contribute to improving medical care by providing accurate and relevant healthcare information quickly.
ChatGPT-4和谷歌Gemini等大语言模型在患者健康教育方面显示出潜力,但对其准确性的担忧需要仔细评估。本研究评估了ChatGPT-4和谷歌Gemini在回答视网膜脱离相关问题时的可读性和准确性。
比较研究,分析ChatGPT-4和谷歌Gemini对13个视网膜脱离问题的回答,这些问题按难度级别(D1、D2、D3)分类。由十位玻璃体视网膜专家对匿名回答进行评审,并根据正确性、错误、主题准确性、连贯性和整体质量分级进行评分。分析包括弗莱什易读性分数、单词和句子数量。
两种人工智能工具在所有难度级别上都需要大学水平的理解能力。谷歌Gemini更容易理解(p = 0.03),而ChatGPT-4在回答较难问题时提供了更多正确答案(p = 0.0005),严重错误更少。ChatGPT-4在最具挑战性的问题上得分最高,显示出卓越的主题准确性(p = 0.003)。ChatGPT-4在13个问题中的8个上表现优于谷歌Gemini,在最容易(p = 0.03)和最难级别(p = 0.0002)的整体质量评分更高,随着问题难度增加评分降低。
ChatGPT-4和谷歌Gemini有效地回答了关于视网膜脱离的问题,提供了大多准确的答案,关键错误很少,不过患者需要接受高等教育才能理解。人工智能工具的应用可能有助于通过快速提供准确和相关的医疗保健信息来改善医疗服务。