Du Xinsong, Zhou Zhengyang, Wang Yifei, Chuang Ya-Wen, Yang Richard, Zhang Wenyu, Wang Xinyi, Zhang Rui, Hong Pengyu, Bates David W, Zhou Li
Division of General Internal Medicine and Primary Care, Brigham and Women's Hospital, Boston, Massachusetts 02115.
Department of Medicine, Harvard Medical School, Boston, Massachusetts 02115.
medRxiv. 2024 Aug 19:2024.08.11.24311828. doi: 10.1101/2024.08.11.24311828.
Generative Large language models (LLMs) represent a significant advancement in natural language processing, achieving state-of-the-art performance across various tasks. However, their application in clinical settings using real electronic health records (EHRs) is still rare and presents numerous challenges.
This study aims to systematically review the use of generative LLMs, and the effectiveness of relevant techniques in patient care-related topics involving EHRs, summarize the challenges faced, and suggest future directions.
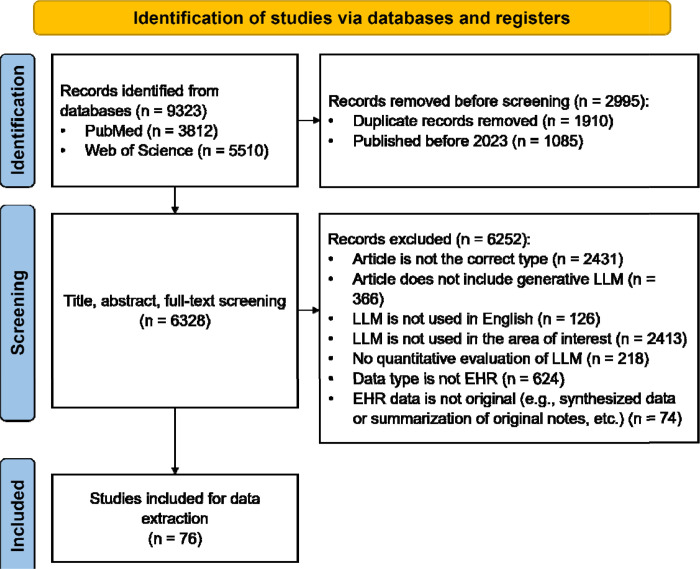
A Boolean search for peer-reviewed articles was conducted on May 19, 2024 using PubMed and Web of Science to include research articles published since 2023, which was one month after the release of ChatGPT. The search results were deduplicated. Multiple reviewers, including biomedical informaticians, computer scientists, and a physician, screened the publications for eligibility and conducted data extraction. Only studies utilizing generative LLMs to analyze real EHR data were included. We summarized the use of prompt engineering, fine-tuning, multimodal EHR data, and evaluation matrices. Additionally, we identified current challenges in applying LLMs in clinical settings as reported by the included studies and proposed future directions.
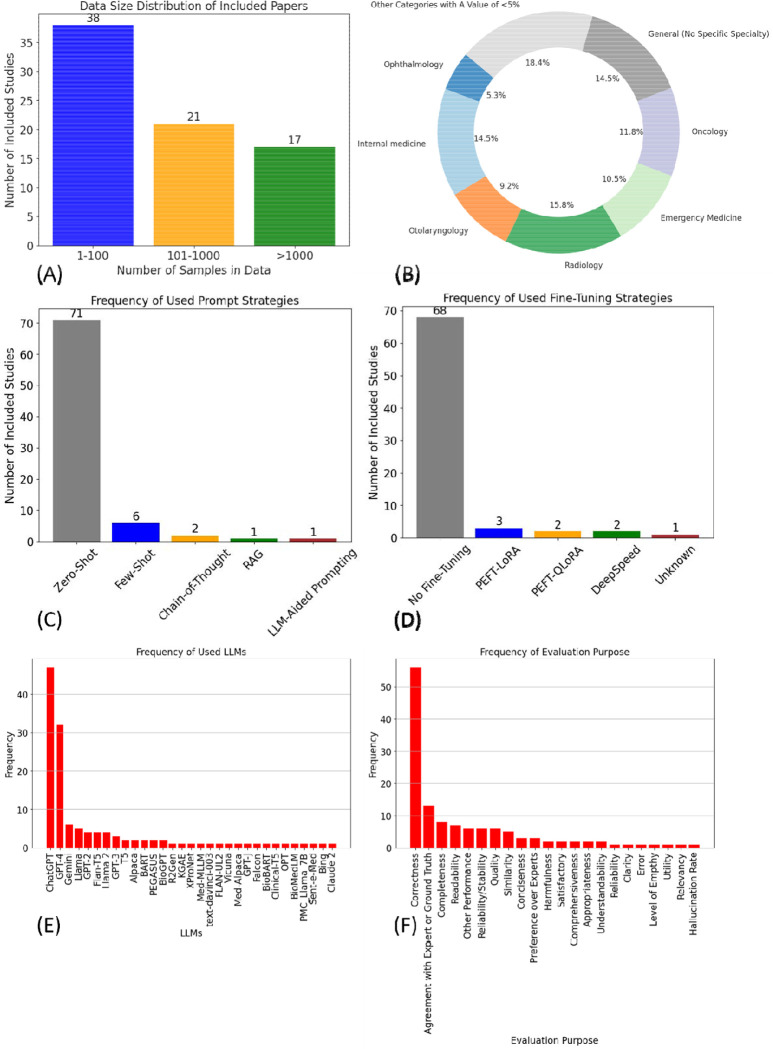
The initial search identified 6,328 unique studies, with 76 studies included after eligibility screening. Of these, 67 studies (88.2%) employed zero-shot prompting, five of them reported 100% accuracy on five specific clinical tasks. Nine studies used advanced prompting strategies; four tested these strategies experimentally, finding that prompt engineering improved performance, with one study noting a non-linear relationship between the number of examples in a prompt and performance improvement. Eight studies explored fine-tuning generative LLMs, all reported performance improvements on specific tasks, but three of them noted potential performance degradation after fine-tuning on certain tasks. Only two studies utilized multimodal data, which improved LLM-based decision-making and enabled accurate rare disease diagnosis and prognosis. The studies employed 55 different evaluation metrics for 22 purposes, such as correctness, completeness, and conciseness. Two studies investigated LLM bias, with one detecting no bias and the other finding that male patients received more appropriate clinical decision-making suggestions. Six studies identified hallucinations, such as fabricating patient names in structured thyroid ultrasound reports. Additional challenges included but were not limited to the impersonal tone of LLM consultations, which made patients uncomfortable, and the difficulty patients had in understanding LLM responses.
Our review indicates that few studies have employed advanced computational techniques to enhance LLM performance. The diverse evaluation metrics used highlight the need for standardization. LLMs currently cannot replace physicians due to challenges such as bias, hallucinations, and impersonal responses.
生成式大语言模型(LLMs)代表了自然语言处理领域的一项重大进展,在各种任务中都取得了领先的性能。然而,它们在使用真实电子健康记录(EHRs)的临床环境中的应用仍然很少,并且存在众多挑战。
本研究旨在系统回顾生成式大语言模型的使用情况,以及相关技术在涉及电子健康记录的患者护理相关主题中的有效性,总结面临的挑战,并提出未来的方向。
2024年5月19日,使用PubMed和Web of Science对同行评审文章进行布尔搜索,以纳入自2023年(ChatGPT发布后一个月)以来发表的研究文章。对搜索结果进行去重。包括生物医学信息学家、计算机科学家和一名医生在内的多名评审人员对出版物进行资格筛选并进行数据提取。仅纳入利用生成式大语言模型分析真实电子健康记录数据的研究。我们总结了提示工程、微调、多模态电子健康记录数据和评估矩阵的使用情况。此外,我们确定了纳入研究报告的在临床环境中应用大语言模型当前面临的挑战,并提出了未来的方向。
初步搜索识别出6328项独特研究,经过资格筛选后纳入76项研究。其中,67项研究(88.2%)采用了零样本提示,其中5项研究在五项特定临床任务上报告了100%的准确率。9项研究使用了先进的提示策略;4项对这些策略进行了实验测试,发现提示工程提高了性能,其中一项研究指出提示中的示例数量与性能提升之间存在非线性关系。8项研究探索了生成式大语言模型的微调,所有研究都报告了在特定任务上的性能提升,但其中3项研究指出在某些任务上微调后可能存在性能下降。只有2项研究使用了多模态数据,这改善了基于大语言模型的决策制定,并实现了准确的罕见病诊断和预后。这些研究为22个目的采用了55种不同的评估指标,如正确性完整性和简洁性。2项研究调查了大语言模型的偏差,一项未检测到偏差,另一项发现男性患者收到了更合适的临床决策建议。6项研究识别出幻觉,如在结构化甲状腺超声报告中编造患者姓名。其他挑战包括但不限于大语言模型咨询的客观语气让患者感到不舒服,以及患者理解大语言模型回复存在困难。
我们的综述表明,很少有研究采用先进的计算技术来提高大语言模型的性能。所使用的多样化评估指标凸显了标准化的必要性。由于偏差、幻觉和客观回复等挑战,大语言模型目前无法取代医生。