TUM School of Computation, Information and Technology, Bioinformatics & Computational Biology - i12, Boltzmannstr. 3, 85748, Garching/Munich, Germany.
TUM Graduate School, Center of Doctoral Studies in Informatics and Its Applications (CeDoSIA), Boltzmannstr. 11, 85748, Garching, Germany.
Sci Rep. 2024 Sep 5;14(1):20692. doi: 10.1038/s41598-024-71783-8.
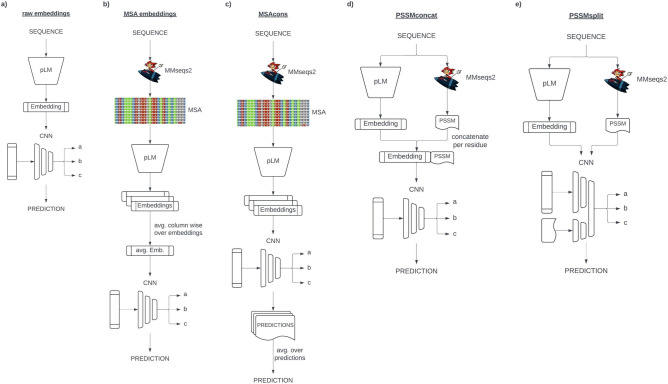
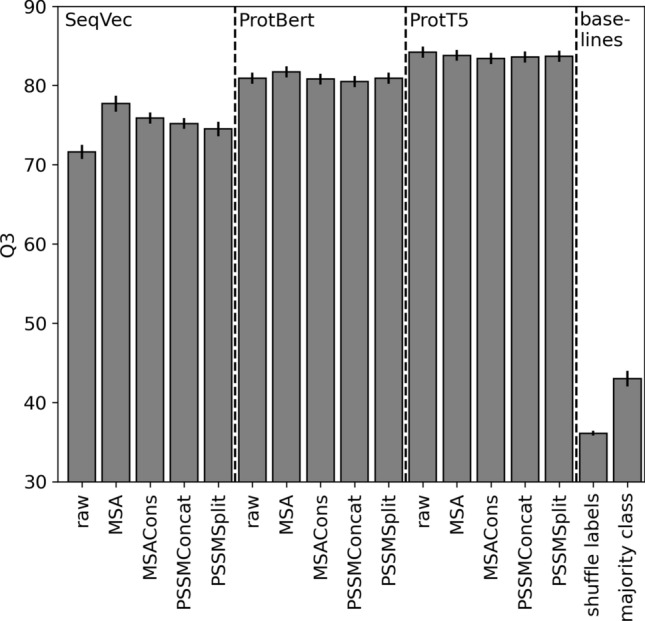
Embeddings from protein Language Models (pLMs) are replacing evolutionary information from multiple sequence alignments (MSAs) as the most successful input for protein prediction. Is this because embeddings capture evolutionary information? We tested various approaches to explicitly incorporate evolutionary information into embeddings on various protein prediction tasks. While older pLMs (SeqVec, ProtBert) significantly improved through MSAs, the more recent pLM ProtT5 did not benefit. For most tasks, pLM-based outperformed MSA-based methods, and the combination of both even decreased performance for some (intrinsic disorder). We highlight the effectiveness of pLM-based methods and find limited benefits from integrating MSAs.
基于蛋白质语言模型 (pLM) 的嵌入正在取代来自多重序列比对 (MSA) 的进化信息,成为蛋白质预测中最成功的输入。这是因为嵌入可以捕捉进化信息吗?我们测试了各种方法,试图在各种蛋白质预测任务中显式地将进化信息纳入嵌入。虽然较旧的 pLM(SeqVec、ProtBert)通过 MSA 显著提高,但更新的 pLM ProtT5 并没有受益。对于大多数任务,基于 pLM 的方法优于基于 MSA 的方法,而两者的结合甚至在某些情况下(内在无序)降低了性能。我们强调了基于 pLM 的方法的有效性,并发现从整合 MSA 中获得的收益有限。