Cluster of Excellence "Balance of the Microverse", Leibniz Institute for Natural Product Research and Infection Biology Hans Knöll Institute, Adolf-Reichwein-Straße 23, Jena, Thuringia, 07745, Germany.
Department of Archaeogenetics, Max Planck Institute for Evolutionary Anthropology, Deutscher Pl. 6, Leipzig, Saxony, 04103, Germany.
F1000Res. 2024 May 28;12:926. doi: 10.12688/f1000research.134798.2. eCollection 2023.
Access to sample-level metadata is important when selecting public metagenomic sequencing datasets for reuse in new biological analyses. The Standards, Precautions, and Advances in Ancient Metagenomics community (SPAAM, https://spaam-community.org) has previously published AncientMetagenomeDir, a collection of curated and standardised sample metadata tables for metagenomic and microbial genome datasets generated from ancient samples. However, while sample-level information is useful for identifying relevant samples for inclusion in new projects, Next Generation Sequencing (NGS) library construction and sequencing metadata are also essential for appropriately reprocessing ancient metagenomic data. Currently, recovering information for downloading and preparing such data is difficult when laboratory and bioinformatic metadata is heterogeneously recorded in prose-based publications.
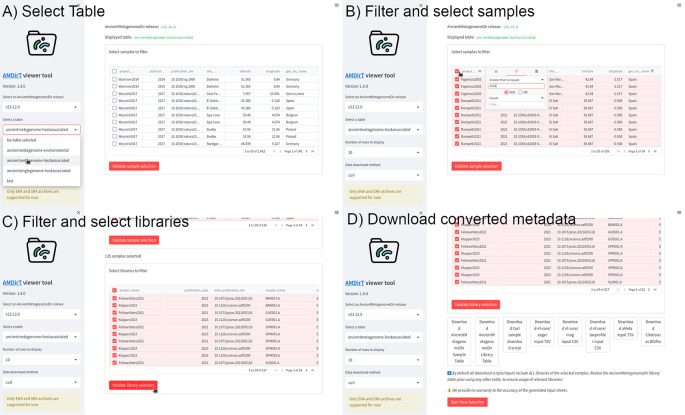
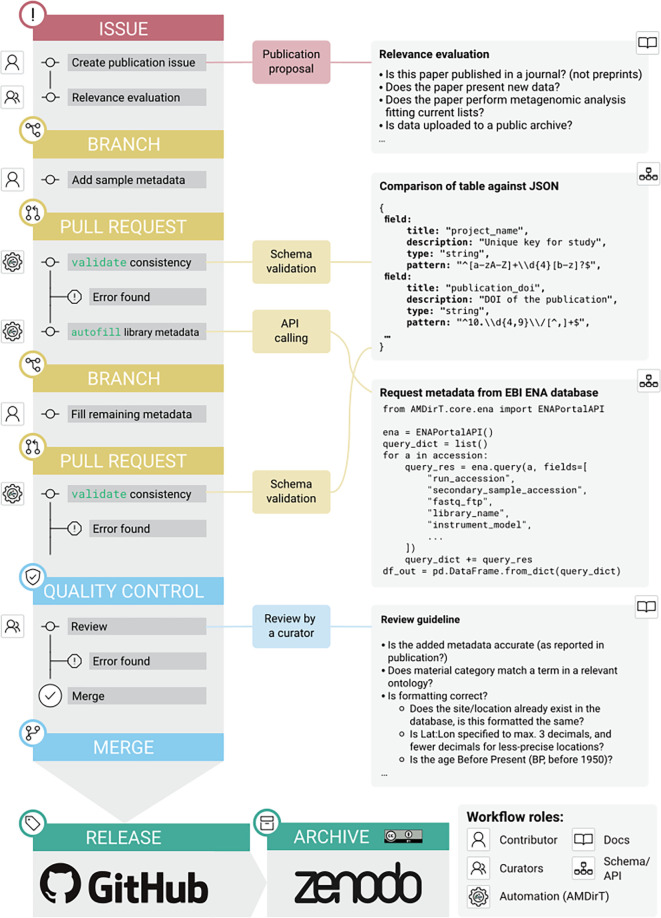
Through a series of community-based hackathon events, AncientMetagenomeDir was updated to provide standardised library-level metadata of existing and new ancient metagenomic samples. In tandem, the companion tool 'AMDirT' was developed to facilitate rapid data filtering and downloading of ancient metagenomic data, as well as improving automated metadata curation and validation for AncientMetagenomeDir.
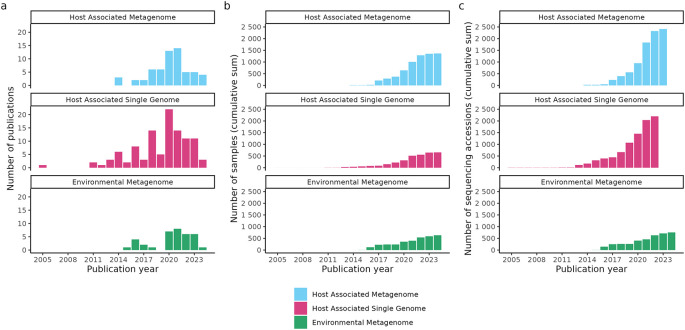
AncientMetagenomeDir was extended to include standardised metadata of over 6000 ancient metagenomic libraries. The companion tool 'AMDirT' provides both graphical- and command-line interface based access to such metadata for users from a wide range of computational backgrounds. We also report on errors with metadata reporting that appear to commonly occur during data upload and provide suggestions on how to improve the quality of data sharing by the community.
Together, both standardised metadata reporting and tooling will help towards easier incorporation and reuse of public ancient metagenomic datasets into future analyses.
在选择公共宏基因组测序数据集以供新的生物分析重复使用时,访问样本级别的元数据非常重要。标准、预防措施和古代宏基因组学社区(SPAAM,https://spaam-community.org)之前发布了 AncientMetagenomeDir,这是一个经过精心整理和标准化的样本元数据表格的集合,用于从古代样本中生成的宏基因组和微生物基因组数据集。然而,虽然样本级别的信息对于识别相关样本以纳入新项目非常有用,但下一代测序 (NGS) 文库构建和测序元数据对于适当处理古代宏基因组数据也至关重要。目前,当实验室和生物信息学元数据以基于散文的出版物中的异质方式记录时,恢复用于下载和准备此类数据的信息非常困难。
通过一系列基于社区的黑客马拉松活动,AncientMetagenomeDir 进行了更新,以提供现有和新的古代宏基因组样本的标准化库级元数据。与此同时,开发了配套工具 'AMDirT',以方便快速筛选和下载古代宏基因组数据,以及改进 AncientMetagenomeDir 的自动化元数据整理和验证。
AncientMetagenomeDir 扩展到包含超过 6000 个古代宏基因组文库的标准化元数据。配套工具 'AMDirT' 为来自广泛计算背景的用户提供了对这些元数据的图形和命令行界面访问。我们还报告了在数据上传过程中似乎经常出现的元数据报告错误,并提供了有关如何提高社区数据共享质量的建议。
标准化元数据报告和工具的结合将有助于更轻松地将公共古代宏基因组数据集纳入未来的分析中进行重复使用。