Gunn Sophia, Wang Xin, Posner Daniel C, Cho Kelly, Huffman Jennifer E, Gaziano Michael, Wilson Peter W, Sun Yan V, Peloso Gina, Lunetta Kathryn L
Biostatistics, Boston University School of Public Health, Boston, MA, USA; VA Boston Healthcare System, Boston, MA, USA.
Cardiovascular Research Center, Massachusetts General Hospital, Boston, MA, USA; Cardiovascular Disease Initiative, Broad Institute of MIT and Harvard, Cambridge, MA, USA.
HGG Adv. 2025 Jan 9;6(1):100355. doi: 10.1016/j.xhgg.2024.100355. Epub 2024 Sep 25.
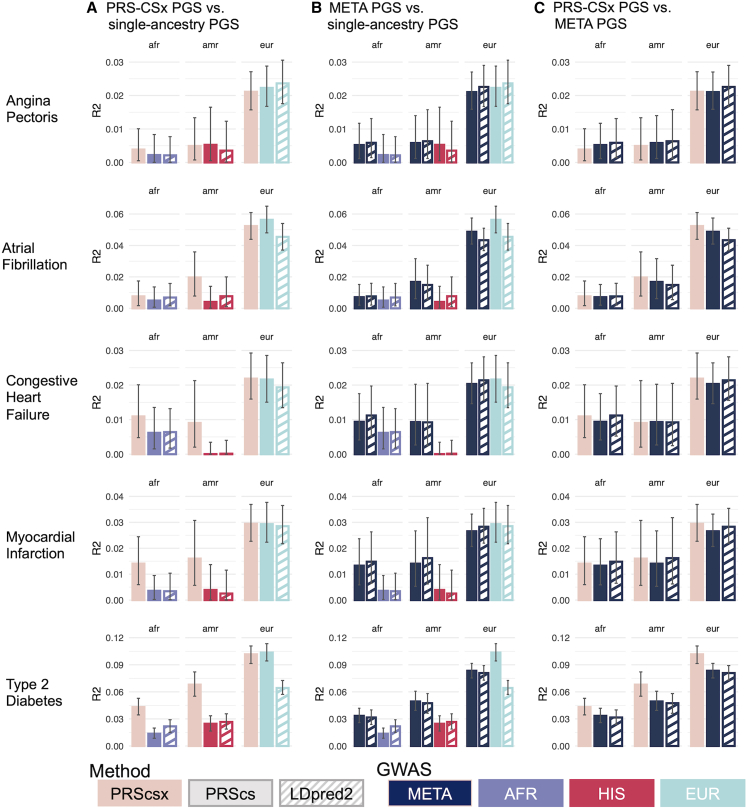
Polygenic scores (PGSs) are a promising tool for estimating individual-level genetic risk of disease based on the results of genome-wide association studies (GWASs). However, their promise has yet to be fully realized because most currently available PGSs were built with genetic data from predominantly European-ancestry populations, and PGS performance declines when scores are applied to target populations different from the populations from which they were derived. Thus, there is a great need to improve PGS performance in currently under-studied populations. In this work we leverage data from two large and diverse cohorts the Million Veterans Program (MVP) and All of Us (AoU), providing us the unique opportunity to compare methods for building PGSs for multi-ancestry populations across multiple traits. We build PGSs for five continuous traits and five binary traits using both multi-ancestry and single-ancestry approaches with popular Bayesian PGS methods and both MVP META GWAS results and population-specific GWAS results from the respective African, European, and Hispanic MVP populations. We evaluate these scores in three AoU populations genetically similar to the respective African, Admixed American, and European 1000 Genomes Project superpopulations. Using correlation-based tests, we make formal comparisons of the PGS performance across the multiple AoU populations. We conclude that approaches that combine GWAS data from multiple populations produce PGSs that perform better than approaches that utilize smaller single-population GWAS results matched to the target population, and specifically that multi-ancestry scores built with PRS-CSx outperform the other approaches in the three AoU populations.
多基因评分(PGS)是一种很有前景的工具,可根据全基因组关联研究(GWAS)的结果来估计个体层面的疾病遗传风险。然而,它们的潜力尚未得到充分发挥,因为目前大多数可用的PGS是基于主要为欧洲血统人群的遗传数据构建的,当将这些评分应用于与其所源自人群不同的目标人群时,PGS的性能会下降。因此,迫切需要提高PGS在目前研究不足的人群中的性能。在这项工作中,我们利用了来自两个大型且多样化队列的数据,即百万退伍军人计划(MVP)和全民计划(AoU),这为我们提供了一个独特的机会,来比较为多个性状的多血统人群构建PGS的方法。我们使用多血统和单血统方法以及流行的贝叶斯PGS方法,利用MVP元GWAS结果以及来自非洲、欧洲和西班牙裔MVP人群各自的特定人群GWAS结果,为五个连续性状和五个二元性状构建PGS。我们在三个与非洲、混合血统美国人和欧洲千人基因组计划超级人群在基因上相似的AoU人群中评估这些评分。使用基于相关性的测试,我们对多个AoU人群中的PGS性能进行了正式比较。我们得出结论,结合来自多个群体的GWAS数据的方法所产生的PGS比使用与目标群体匹配的较小单群体GWAS结果的方法表现更好,特别是使用PRS-CSx构建的多血统评分在三个AoU人群中优于其他方法。