Ghandian Sina, Albarghouthi Liane, Nava Kiana, Sharma Shivam R Rai, Minaud Lise, Beckett Laurel, Saito Naomi, DeCarli Charles, Rissman Robert A, Teich Andrew F, Jin Lee-Way, Dugger Brittany N, Keiser Michael J
Institute for Neurodegenerative Diseases, University of California, San Francisco, San Francisco, CA, 94158, USA.
Bakar Computational Health Sciences Institute, University of California, San Francisco, CA, 94158, USA.
bioRxiv. 2024 Sep 24:2024.05.15.594372. doi: 10.1101/2024.05.15.594372.
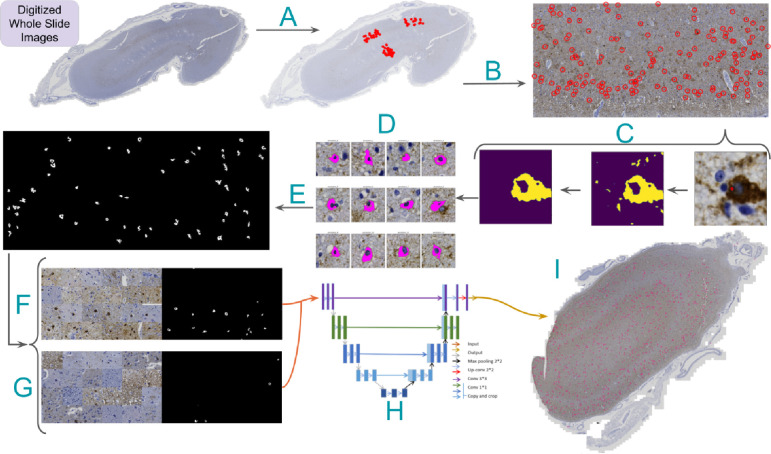
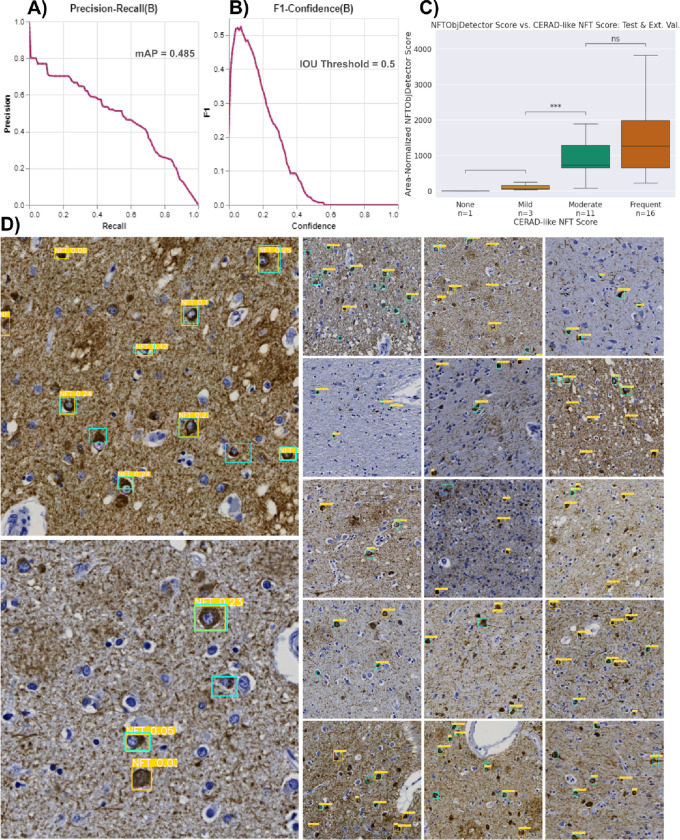
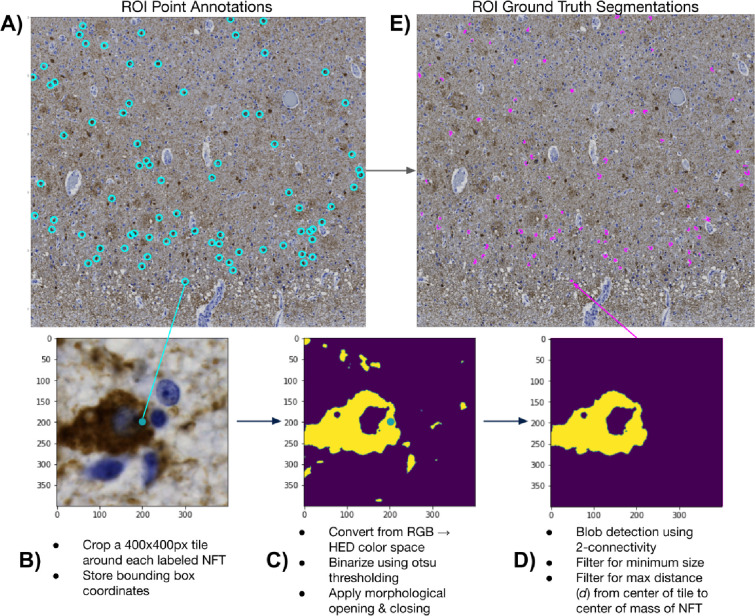
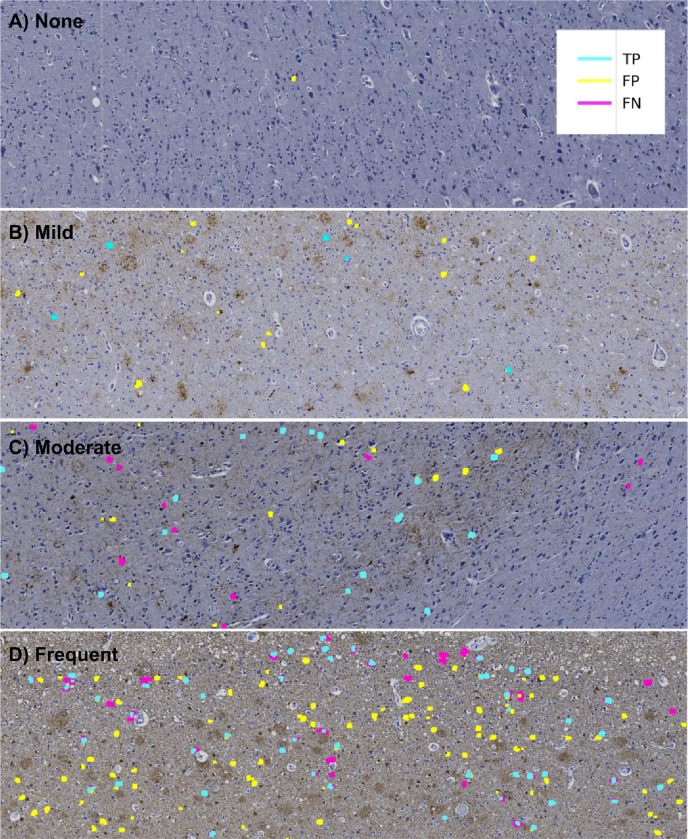
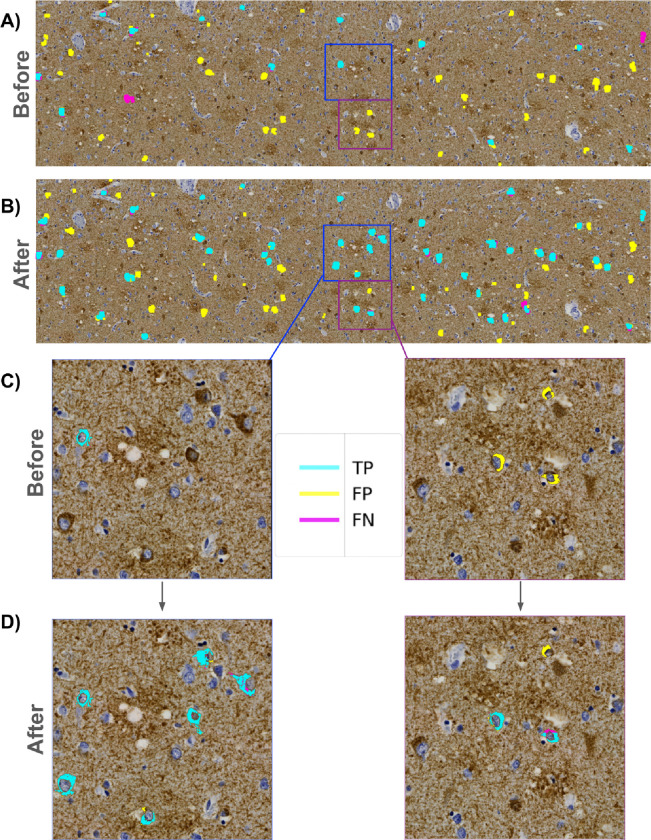
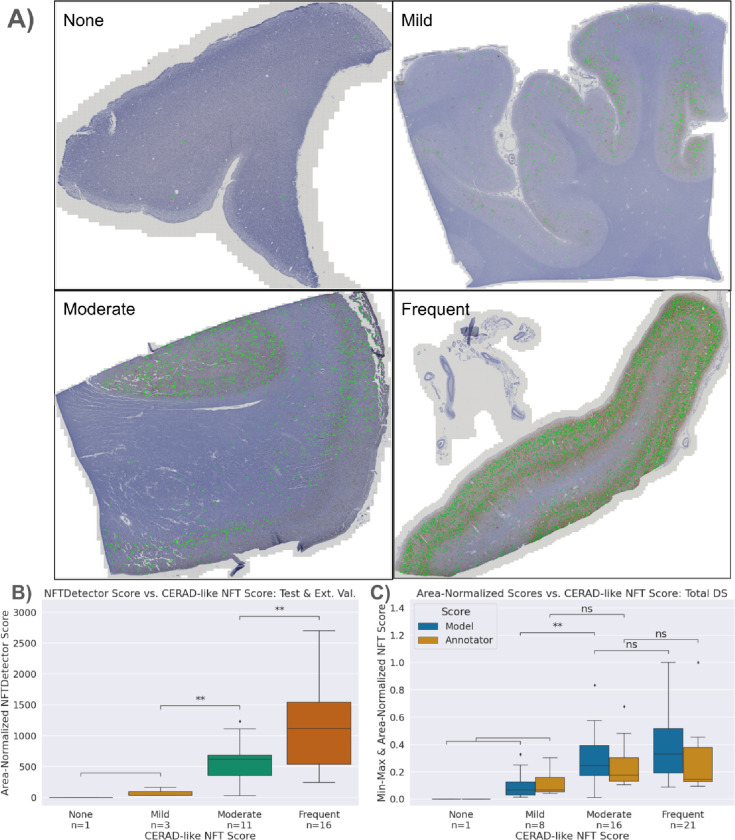
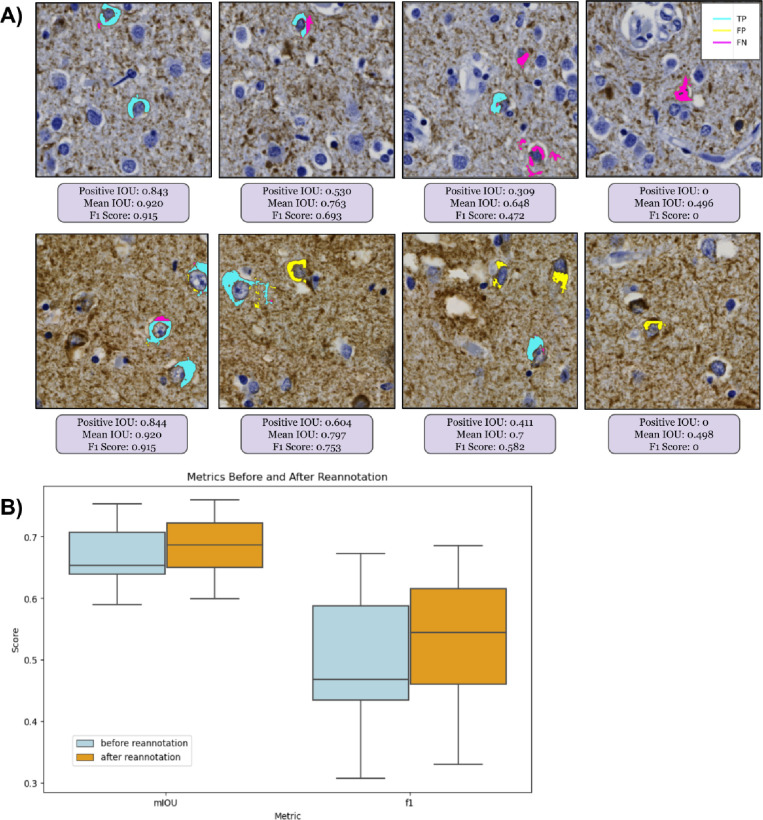
Accumulation of abnormal tau protein into neurofibrillary tangles (NFTs) is a pathologic hallmark of Alzheimer disease (AD). Accurate detection of NFTs in tissue samples can reveal relationships with clinical, demographic, and genetic features through deep phenotyping. However, expert manual analysis is time-consuming, subject to observer variability, and cannot handle the data amounts generated by modern imaging. We present a scalable, open-source, deep-learning approach to quantify NFT burden in digital whole slide images (WSIs) of post-mortem human brain tissue. To achieve this, we developed a method to generate detailed NFT boundaries directly from single-point-per-NFT annotations. We then trained a semantic segmentation model on 45 annotated 2400μm by 1200μm regions of interest (ROIs) selected from 15 unique temporal cortex WSIs of AD cases from three institutions (University of California (UC)-Davis, UC-San Diego, and Columbia University). Segmenting NFTs at the single-pixel level, the model achieved an area under the receiver operating characteristic of 0.832 and an F1 of 0.527 (196-fold over random) on a held-out test set of 664 NFTs from 20 ROIs (7 WSIs). We compared this to deep object detection, which achieved comparable but coarser-grained performance that was 60% faster. The segmentation and object detection models correlated well with expert semi-quantitative scores at the whole-slide level (Spearman's rho ρ=0.654 (p=6.50e-5) and ρ=0.513 (p=3.18e-3), respectively). We openly release this multi-institution deep-learning pipeline to provide detailed NFT spatial distribution and morphology analysis capability at a scale otherwise infeasible by manual assessment.
异常tau蛋白聚积形成神经原纤维缠结(NFTs)是阿尔茨海默病(AD)的病理标志。通过深度表型分析,准确检测组织样本中的NFTs可以揭示其与临床、人口统计学和遗传特征之间的关系。然而,专家手动分析耗时且受观察者差异影响,并且无法处理现代成像产生的数据量。我们提出了一种可扩展的、开源的深度学习方法,用于量化死后人类脑组织数字全切片图像(WSIs)中的NFT负担。为实现这一目标,我们开发了一种方法,可直接从每个NFT的单点注释生成详细的NFT边界。然后,我们在从三个机构(加利福尼亚大学(UC)-戴维斯分校、UC-圣地亚哥分校和哥伦比亚大学)的15个独特的AD病例颞叶皮质WSIs中选择的45个注释的2400μm×1200μm感兴趣区域(ROIs)上训练了一个语义分割模型。该模型在单像素水平上分割NFTs,在来自20个ROIs(7个WSIs)的664个NFTs的保留测试集中,其受试者操作特征曲线下面积为0.832,F1值为0.527(比随机情况高196倍)。我们将此与深度目标检测进行了比较,深度目标检测实现了可比但粒度更粗的性能,速度快60%。分割和目标检测模型在全切片水平上与专家半定量评分具有良好的相关性(斯皮尔曼相关系数ρ分别为0.654(p = 6.50e-5)和ρ = 0.513(p = 3.18e-3))。我们公开发布了这个多机构深度学习管道,以提供详细的NFT空间分布和形态分析能力,而这是通过手动评估在其他情况下无法实现的规模。