Department of Statistics, University of Oxford, Oxford OX1 3LB, United Kingdom.
GSK Medicines Research Centre, GSK, Stevenage SG1 2NY, United Kingdom.
Bioinformatics. 2024 Nov 1;40(11). doi: 10.1093/bioinformatics/btae618.
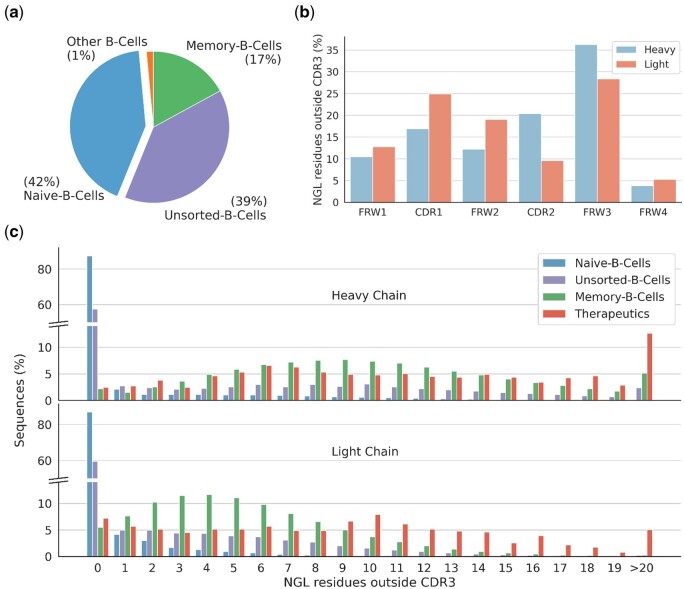
The versatile binding properties of antibodies have made them an extremely important class of biotherapeutics. However, therapeutic antibody development is a complex, expensive, and time-consuming task, with the final antibody needing to not only have strong and specific binding but also be minimally impacted by developability issues. The success of transformer-based language models in protein sequence space and the availability of vast amounts of antibody sequences, has led to the development of many antibody-specific language models to help guide antibody design. Antibody diversity primarily arises from V(D)J recombination, mutations within the CDRs, and/or from a few nongermline mutations outside the CDRs. Consequently, a significant portion of the variable domain of all natural antibody sequences remains germline. This affects the pre-training of antibody-specific language models, where this facet of the sequence data introduces a prevailing bias toward germline residues. This poses a challenge, as mutations away from the germline are often vital for generating specific and potent binding to a target, meaning that language models need be able to suggest key mutations away from germline.
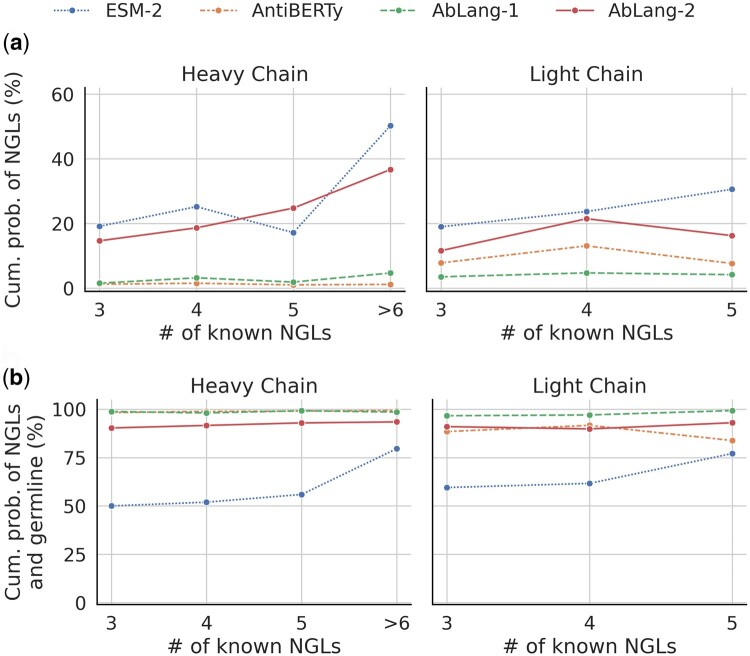
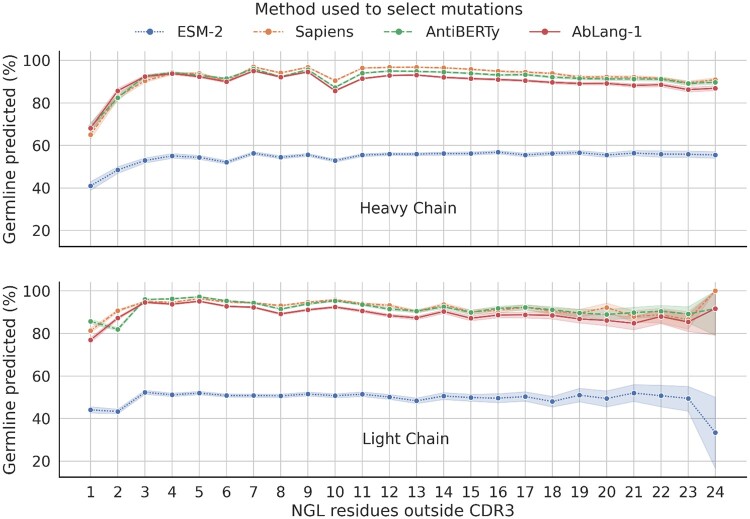
In this study, we explore the implications of the germline bias, examining its impact on both general-protein and antibody-specific language models. We develop and train a series of new antibody-specific language models optimized for predicting nongermline residues. We then compare our final model, AbLang-2, with current models and show how it suggests a diverse set of valid mutations with high cumulative probability.
AbLang-2 is trained on both unpaired and paired data, and is freely available at https://github.com/oxpig/AbLang2.git.
抗体的多功能结合特性使其成为一类极其重要的生物治疗药物。然而,治疗性抗体的开发是一项复杂、昂贵且耗时的任务,最终的抗体不仅需要具有强大和特异性的结合,还需要最小化可开发性问题的影响。基于变压器的语言模型在蛋白质序列空间中的成功以及大量抗体序列的可用性,促使开发了许多针对抗体的语言模型来帮助指导抗体设计。抗体多样性主要源于 V(D)J 重组、CDR 内的突变,和/或 CDR 外的少数非种系突变。因此,所有天然抗体序列的可变区很大一部分仍然是种系。这会影响针对抗体的语言模型的预训练,其中序列数据的这一方面会导致对种系残基的普遍偏见。这带来了一个挑战,因为远离种系的突变对于产生针对目标的特异性和强效结合通常是至关重要的,这意味着语言模型需要能够提出远离种系的关键突变。
在这项研究中,我们探讨了种系偏差的影响,研究了其对一般蛋白质和抗体特异性语言模型的影响。我们开发并训练了一系列针对预测非种系残基的新的抗体特异性语言模型。然后,我们将我们的最终模型 AbLang-2 与当前模型进行比较,并展示了它如何建议具有高累积概率的多样化有效突变。
AbLang-2 是在未配对和配对数据上进行训练的,并可在 https://github.com/oxpig/AbLang2.git 上免费获得。