Smolyak Daniel, Bjarnadóttir Margrét V, Crowley Kenyon, Agarwal Ritu
Department of Computer Science, University of Maryland, College Park, College Park, MD 20742, United States.
Robert H. Smith School of Business, University of Maryland, College Park, College Park, MD 20740, United States.
JAMIA Open. 2024 Oct 26;7(4):ooae114. doi: 10.1093/jamiaopen/ooae114. eCollection 2024 Dec.
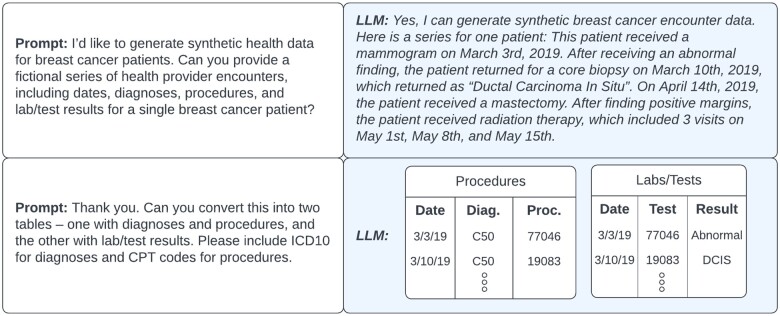
Given substantial obstacles surrounding health data acquisition, high-quality synthetic health data are needed to meet a growing demand for the application of advanced analytics for clinical discovery, prediction, and operational excellence. We highlight how recent advances in large language models (LLMs) present new opportunities for progress, as well as new risks, in synthetic health data generation (SHDG).
We synthesized systematic scoping reviews in the SHDG domain, recent LLM methods for SHDG, and papers investigating the capabilities and limits of LLMs.
We summarize the current landscape of generative machine learning models (eg, Generative Adversarial Networks) for SHDG, describe remaining challenges and limitations, and identify how recent LLM approaches can potentially help mitigate them.
Six research directions are outlined for further investigation of LLMs for SHDG: evaluation metrics, LLM adoption, data efficiency, generalization, health equity, and regulatory challenges.
LLMs have already demonstrated both high potential and risks in the health domain, and it is important to study their advantages and disadvantages for SHDG.
鉴于健康数据获取存在诸多重大障碍,需要高质量的合成健康数据来满足对先进分析方法在临床发现、预测和卓越运营方面应用日益增长的需求。我们强调了大语言模型(LLMs)的最新进展如何为合成健康数据生成(SHDG)带来新的机遇以及新的风险。
我们综合了SHDG领域的系统综述、用于SHDG的最新LLM方法以及研究LLMs能力和局限性的论文。
我们总结了用于SHDG的生成式机器学习模型(如生成对抗网络)的当前情况,描述了剩余的挑战和局限性,并确定了最近的LLM方法如何有可能帮助缓解这些问题。
概述了六个研究方向,以进一步研究用于SHDG的LLMs:评估指标、LLM采用、数据效率、泛化、健康公平性和监管挑战。
LLMs在健康领域已经展现出高潜力和风险,研究它们在SHDG方面的优缺点很重要。