Abdul Sami Mohammed, Abdul Samad Mohammed, Parekh Keyur, Suthar Pokhraj P
Department of Diagnostic Radiology and Nuclear Medicine, Rush University Medical Center, Chicago, USA.
Department of Diagnostic Radiology, Des Moines University College of Osteopathic Medicine, West Des Moines, USA.
Cureus. 2024 Oct 5;16(10):e70897. doi: 10.7759/cureus.70897. eCollection 2024 Oct.
This study evaluates the accuracy of two AI language models, ChatGPT 4.0 and Google Gemini (as of August 2024), in answering a set of 79 text-based pediatric radiology questions from "Pediatric Imaging: A Core Review." Accurate interpretation of text and images is critical in radiology, making AI tools valuable in medical education.
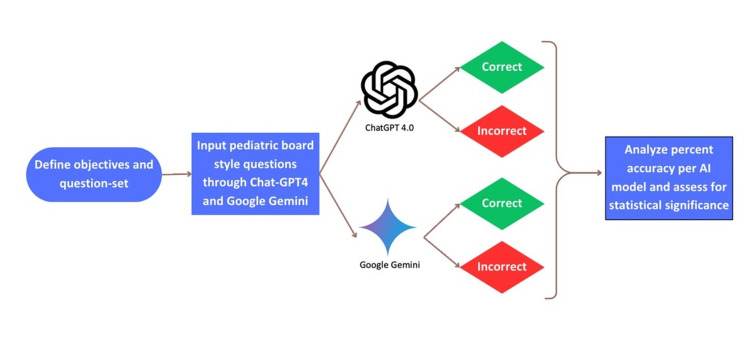
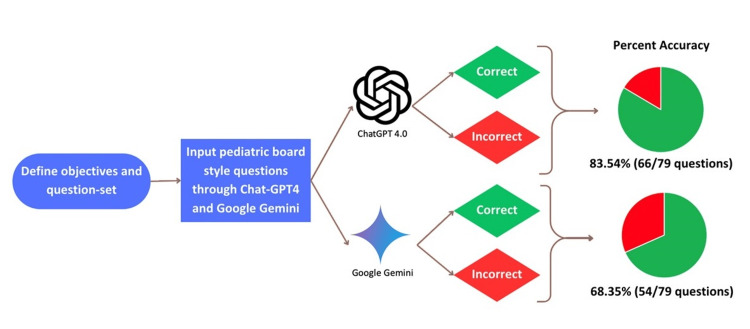
The study involved 79 questions selected from a pediatric radiology question set, focusing solely on text-based questions. ChatGPT 4.0 and Google Gemini answered these questions, and their responses were evaluated using a binary scoring system. Statistical analyses, including chi-square tests and relative risk (RR) calculations, were performed to compare the overall and subsection accuracy of the models.
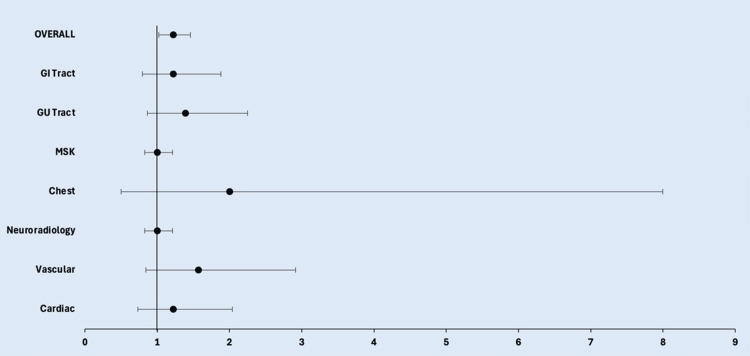
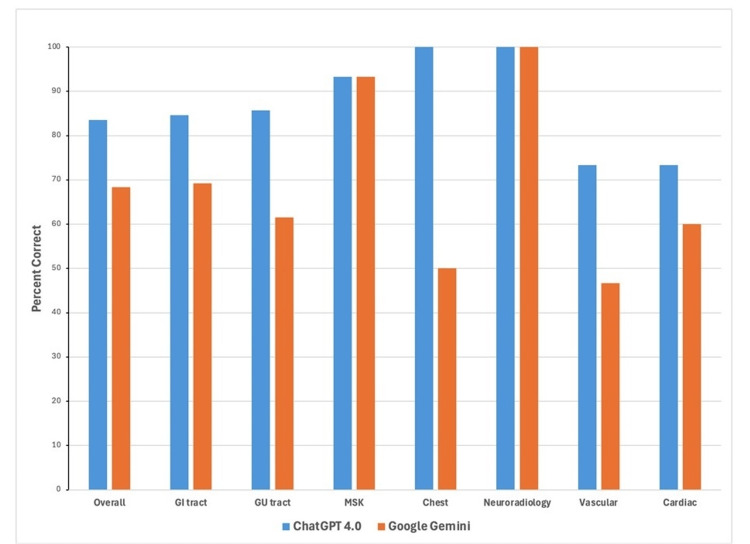
ChatGPT 4.0 demonstrated superior accuracy, correctly answering 83.5% (66/79) of the questions, compared to Google Gemini's 68.4% (54/79), with a statistically significant difference (p=0.0255, RR=1.221). No statistically significant differences were found between the models within individual subsections, with p-values ranging from 0.136 to 1.
ChatGPT 4.0 outperformed Google Gemini in overall accuracy for text-based pediatric radiology questions, highlighting its potential utility in medical education. However, the lack of significant differences within subsections and the exclusion of image-based questions underscore the need for further research with larger sample sizes and multimodal inputs to fully assess AI models' capabilities in radiology.
本研究评估了两个人工智能语言模型ChatGPT 4.0和谷歌Gemini(截至2024年8月)在回答一组来自《儿科影像:核心复习》的79道基于文本的儿科放射学问题时的准确性。在放射学中,对文本和图像的准确解读至关重要,这使得人工智能工具在医学教育中具有重要价值。
该研究从儿科放射学问题集中选取了79个问题,仅关注基于文本的问题。ChatGPT 4.0和谷歌Gemini回答了这些问题,并使用二元评分系统对它们的回答进行评估。进行了包括卡方检验和相对风险(RR)计算在内的统计分析,以比较模型的整体和各部分准确性。
ChatGPT 4.0表现出更高的准确性,正确回答了83.5%(66/79)的问题,而谷歌Gemini的正确率为68.4%(54/79),两者存在统计学显著差异(p = 0.0255,RR = 1.221)。在各个子部分中,模型之间未发现统计学显著差异,p值范围为0.136至1。
在基于文本的儿科放射学问题的整体准确性方面,ChatGPT 4.0优于谷歌Gemini,突出了其在医学教育中的潜在效用。然而,子部分内缺乏显著差异以及排除基于图像的问题,凸显了需要进行更大样本量和多模态输入的进一步研究,以全面评估人工智能模型在放射学中的能力。