Subbaswamy Adarsh, Sahiner Berkman, Petrick Nicholas, Pai Vinay, Adams Roy, Diamond Matthew C, Saria Suchi
Department of Computer Science, Johns Hopkins University, Baltimore, MD, USA.
Center for Devices and Radiological Health, U.S. Food and Drug Administration, Silver Spring, MD, USA.
NPJ Digit Med. 2024 Nov 21;7(1):334. doi: 10.1038/s41746-024-01275-6.
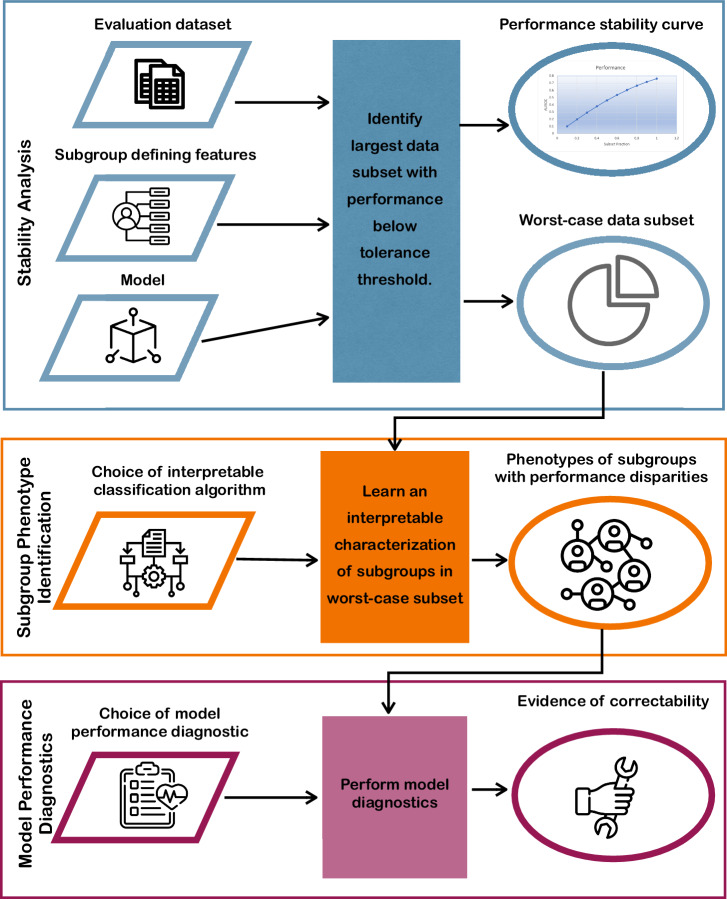
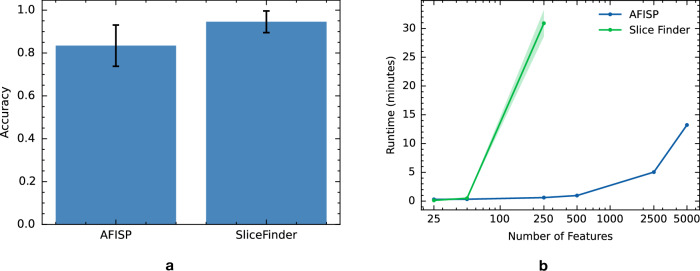
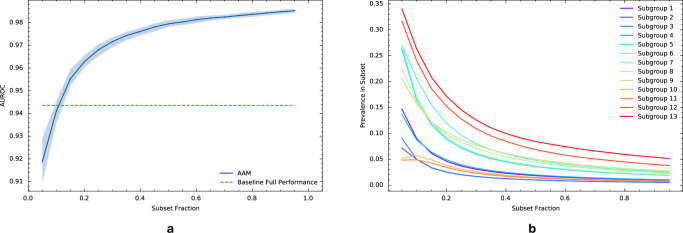
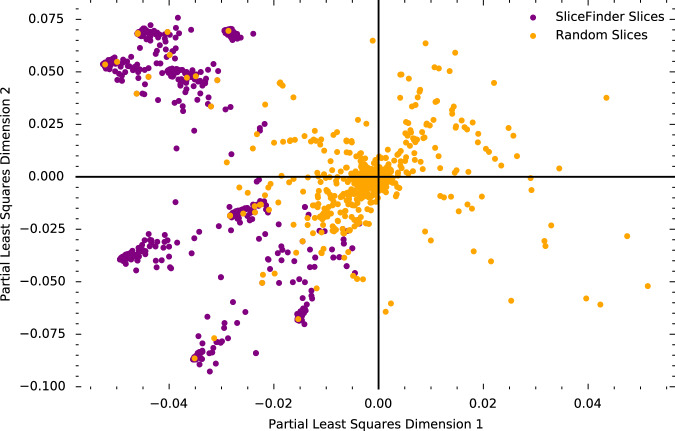
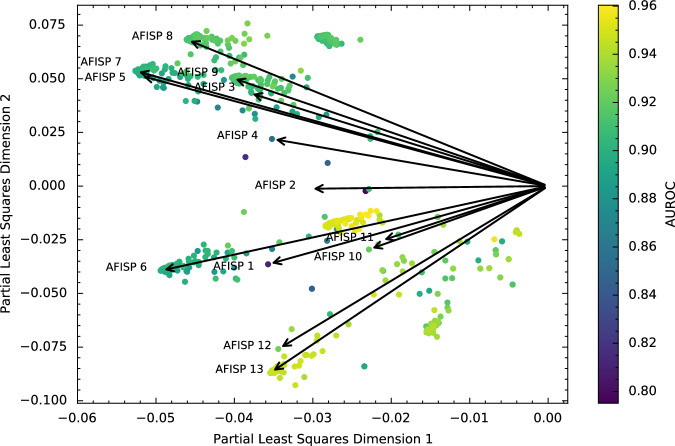
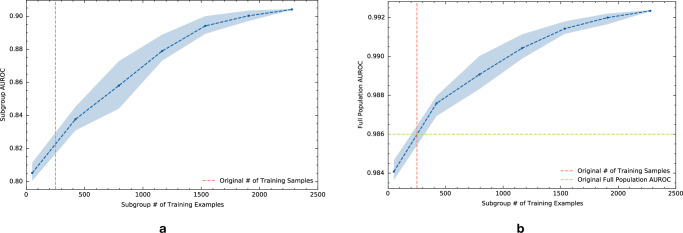
A fundamental goal of evaluating the performance of a clinical model is to ensure it performs well across a diverse intended patient population. A primary challenge is that the data used in model development and testing often consist of many overlapping, heterogeneous patient subgroups that may not be explicitly defined or labeled. While a model's average performance on a dataset may be high, the model can have significantly lower performance for certain subgroups, which may be hard to detect. We describe an algorithmic framework for identifying subgroups with potential performance disparities (AFISP), which produces a set of interpretable phenotypes corresponding to subgroups for which the model's performance may be relatively lower. This could allow model evaluators, including developers and users, to identify possible failure modes prior to wide-scale deployment. We illustrate the application of AFISP by applying it to a patient deterioration model to detect significant subgroup performance disparities, and show that AFISP is significantly more scalable than existing algorithmic approaches.
评估临床模型性能的一个基本目标是确保其在不同的目标患者群体中都能良好运行。一个主要挑战在于,模型开发和测试中使用的数据通常由许多重叠的、异质的患者亚组组成,这些亚组可能没有被明确界定或标记。虽然模型在数据集上的平均性能可能很高,但对于某些亚组,模型的性能可能会显著降低,而这可能很难被发现。我们描述了一种用于识别具有潜在性能差异的亚组的算法框架(AFISP),它会生成一组与模型性能可能相对较低的亚组相对应的可解释表型。这可以让包括开发者和用户在内的模型评估者在大规模部署之前识别出可能的失败模式。我们通过将AFISP应用于一个患者病情恶化模型来检测显著的亚组性能差异,从而展示AFISP的应用,并表明AFISP比现有的算法方法具有显著更高的可扩展性。