Luo Xiaoliang, Rechardt Akilles, Sun Guangzhi, Nejad Kevin K, Yáñez Felipe, Yilmaz Bati, Lee Kangjoo, Cohen Alexandra O, Borghesani Valentina, Pashkov Anton, Marinazzo Daniele, Nicholas Jonathan, Salatiello Alessandro, Sucholutsky Ilia, Minervini Pasquale, Razavi Sepehr, Rocca Roberta, Yusifov Elkhan, Okalova Tereza, Gu Nianlong, Ferianc Martin, Khona Mikail, Patil Kaustubh R, Lee Pui-Shee, Mata Rui, Myers Nicholas E, Bizley Jennifer K, Musslick Sebastian, Bilgin Isil Poyraz, Niso Guiomar, Ales Justin M, Gaebler Michael, Ratan Murty N Apurva, Loued-Khenissi Leyla, Behler Anna, Hall Chloe M, Dafflon Jessica, Bao Sherry Dongqi, Love Bradley C
Department of Experimental Psychology, University College London, London, UK.
Department of Engineering, University of Cambridge, Cambridge, UK.
Nat Hum Behav. 2025 Feb;9(2):305-315. doi: 10.1038/s41562-024-02046-9. Epub 2024 Nov 27.
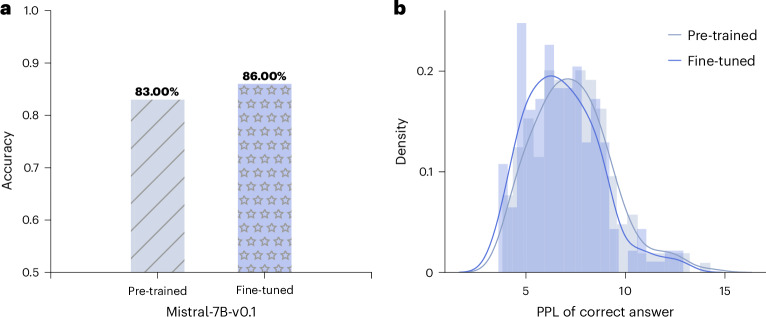
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. Here, to evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs indicated high confidence in their predictions, their responses were more likely to be correct, which presages a future where LLMs assist humans in making discoveries. Our approach is not neuroscience specific and is transferable to other knowledge-intensive endeavours.
科学发现往往取决于对数十年研究的综合,这一任务可能超出人类信息处理能力。大语言模型(LLMs)提供了一种解决方案。在海量科学文献上训练的大语言模型有可能整合有噪声但相互关联的发现,从而比人类专家更好地预测新结果。在此,为了评估这种可能性,我们创建了BrainBench,这是一个用于预测神经科学结果的前瞻性基准。我们发现大语言模型在预测实验结果方面超过了专家。我们在神经科学文献上微调的大语言模型BrainGPT表现更佳。与人类专家一样,当大语言模型对其预测表示高度自信时,它们的回答更有可能是正确的,这预示着大语言模型协助人类进行发现的未来。我们的方法并非特定于神经科学,而是可转移到其他知识密集型工作中。