Qin Guangrong, Narsinh Kamileh, Wei Qi, Roach Jared C, Joshi Arpita, Goetz Skye L, Moxon Sierra T, Brush Matthew H, Xu Colleen, Yao Yao, Glen Amy K, Morris Evan D, Ralevski Alexandra, Roper Ryan, Belhu Basazin, Zhang Yue, Shmulevich Ilya, Hadlock Jennifer, Glusman Gwênlyn
Institute for Systems Biology, 401 Terry Ave N, Seattle, WA 98109, USA.
The Scripps Research Institute, 10550 N Torrey Pines Rd, La Jolla, CA 92037, USA.
bioRxiv. 2024 Nov 15:2024.11.14.623648. doi: 10.1101/2024.11.14.623648.
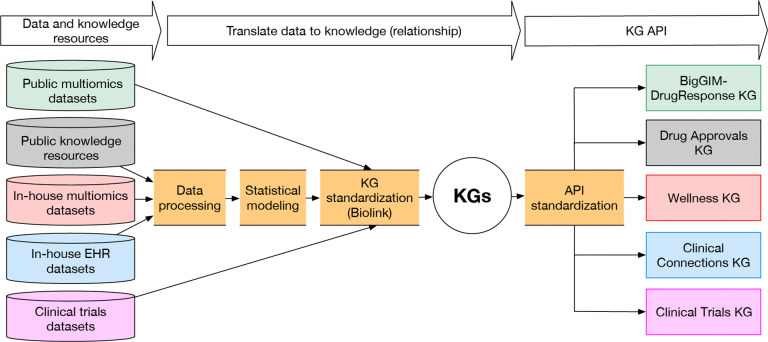
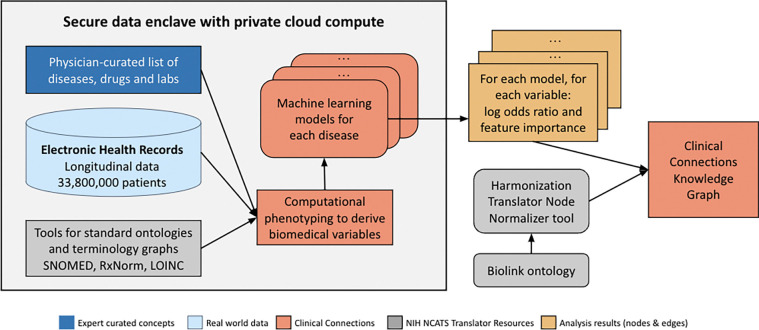
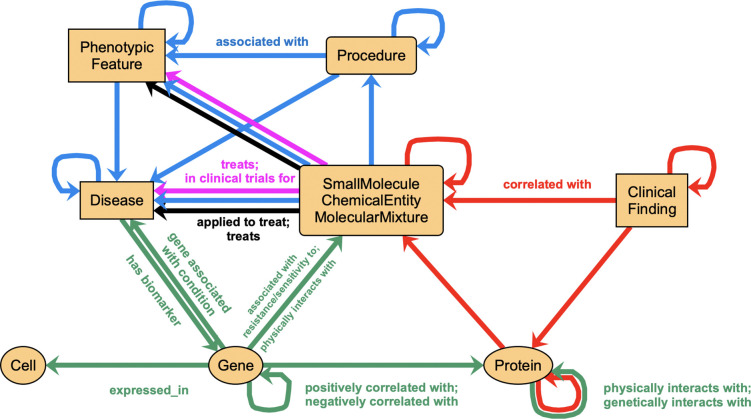
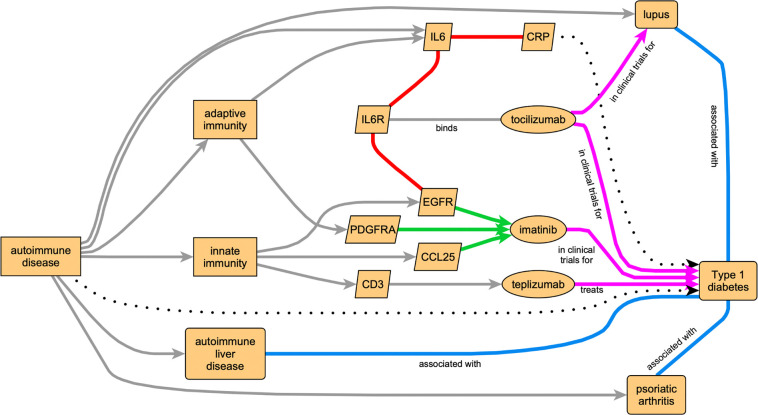
As large clinical and multiomics datasets and knowledge resources accumulate, they need to be transformed into computable and actionable information to support automated reasoning. These datasets range from laboratory experiment results to electronic health records (EHRs). Barriers to accessibility and sharing of such datasets include diversity of content, size and privacy. Effective transformation of data into information requires harmonization of stakeholder goals, implementation, enforcement of standards regarding quality and completeness, and availability of resources for maintenance and updates. Systems such as the Biomedical Data Translator leverage knowledge graphs (KGs), structured and machine learning readable knowledge representation, to encode knowledge extracted through inference. We focus here on the transformation of data from multiomics datasets and EHRs into compact knowledge, represented in a KG data structure. We demonstrate this data transformation in the context of the Translator ecosystem, including clinical trials, drug approvals, cancer, wellness, and EHR data. These transformations preserve individual privacy. We provide access to the five resulting KGs through the Translator framework. We show examples of biomedical research questions supported by our KGs, and discuss issues arising from extracting biomedical knowledge from multiomics data.
随着大型临床和多组学数据集以及知识资源的积累,需要将它们转化为可计算且可操作的信息,以支持自动化推理。这些数据集涵盖从实验室实验结果到电子健康记录(EHR)的范围。此类数据集在可访问性和共享方面的障碍包括内容的多样性、规模和隐私性。要有效地将数据转化为信息,需要协调利益相关者的目标、实施并执行有关质量和完整性的标准,以及提供用于维护和更新的资源。生物医学数据翻译器等系统利用知识图谱(KG),即结构化且机器可读的知识表示,来编码通过推理提取的知识。我们在此重点关注将来自多组学数据集和EHR的数据转化为以KG数据结构表示的紧凑知识。我们在翻译器生态系统的背景下展示这种数据转化,包括临床试验、药物批准、癌症、健康和EHR数据。这些转化保护个人隐私。我们通过翻译器框架提供对生成的五个KG的访问。我们展示了由我们的KG支持的生物医学研究问题的示例,并讨论了从多组学数据中提取生物医学知识时出现的问题。