Spear Jackie, Reid J Nick, Guitard Dominic, Jamieson Randall K
Department of Psychology, University of Manitoba, Winnipeg, Manitob, Canada.
Department of Psychology, University of Northern British Columbia, Canada.
Exp Psychol. 2024 Sep;71(5):278-297. doi: 10.1027/1618-3169/a000630. Epub 2024 Dec 11.
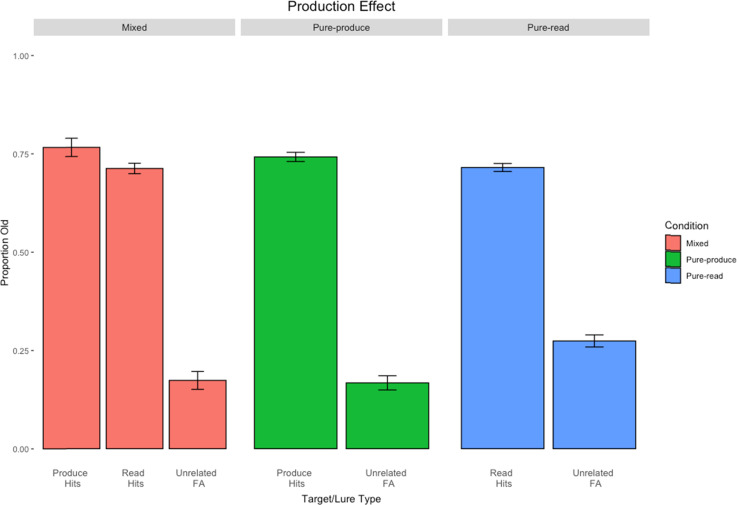
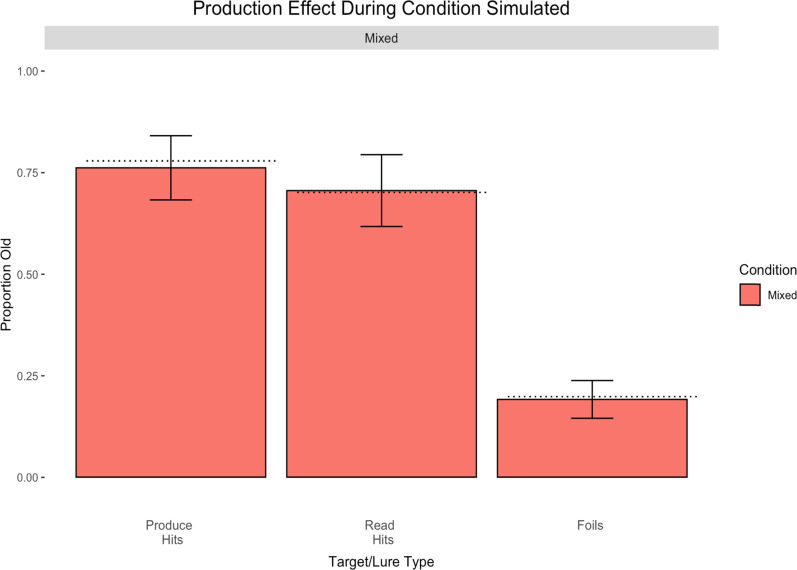
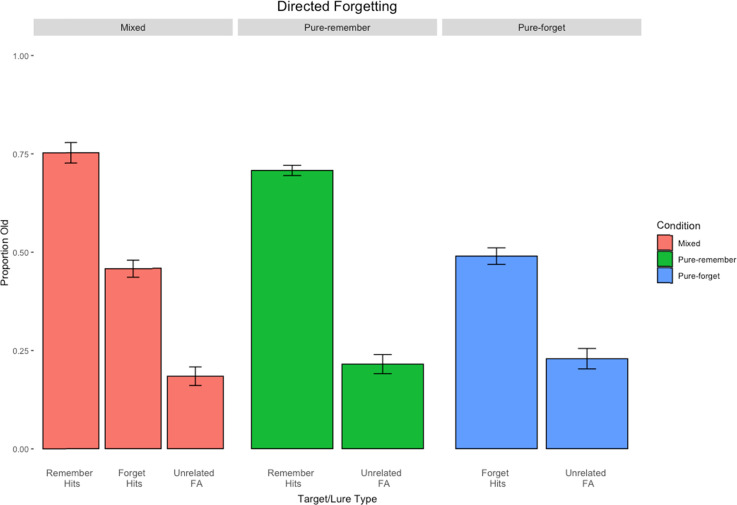
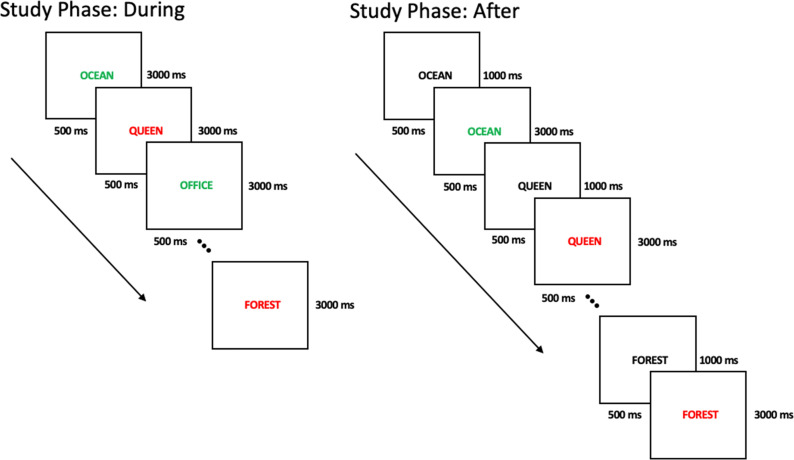
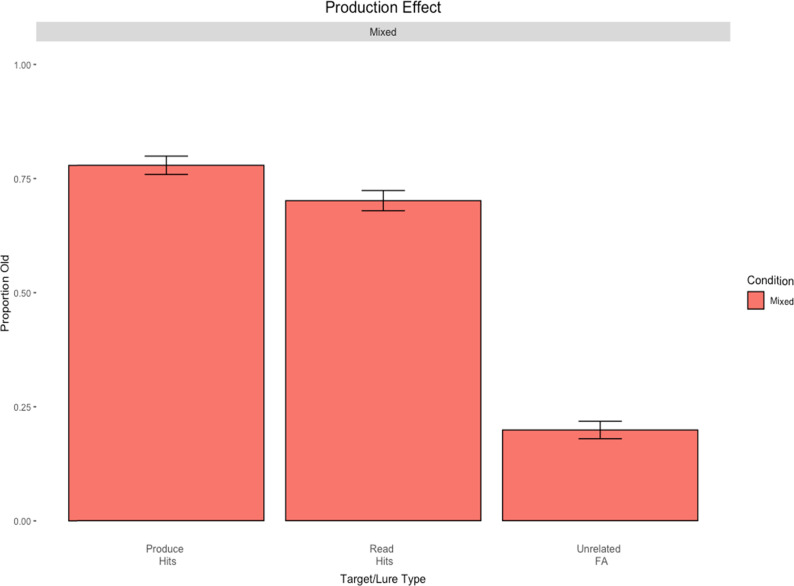
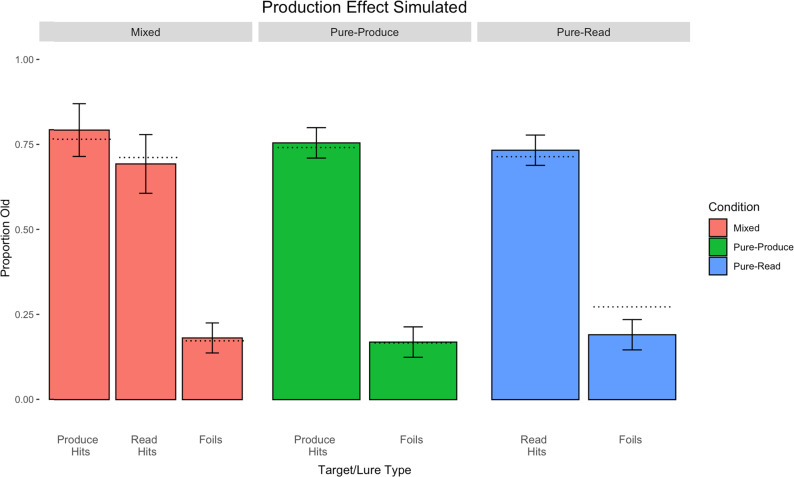
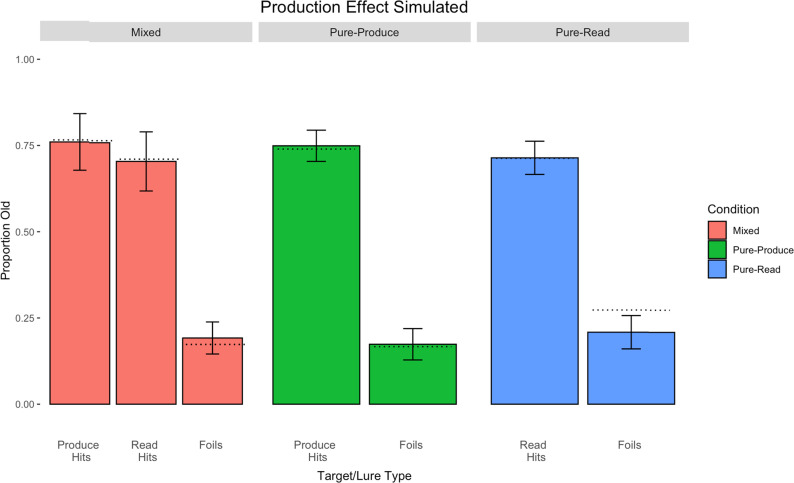
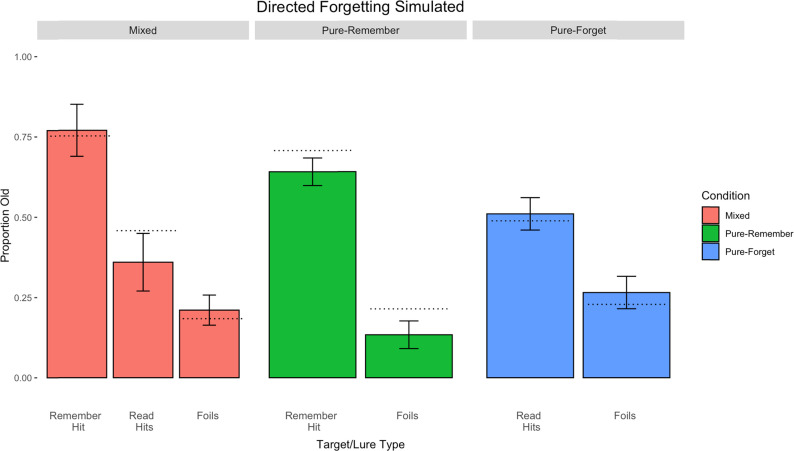
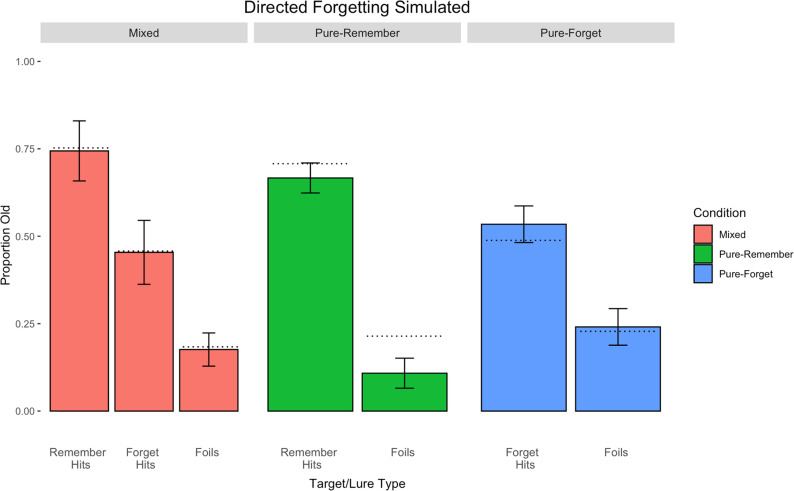
The item-based directed-forgetting effect is explained as a difference in how strongly people encode remember-cued over forget-cued targets. In contrast, the production effect is typically explained as a difference in the distinctiveness of the memory of produced over unproduced targets. The procedural alignment of the two effects - directing participants to remember or forget, produce or not - coupled with their different theoretical explanations (i.e., strength vs. distinctiveness) presents an opportunity to investigate common versus differential effects of elaborative encoding. This study aims to bridge the gap between these two well-established phenomena by comparing the differences in directed forgetting and the production effect in the context of recognition. Mixed- and pure-list designs were utilized to provide an index of each of these mechanisms in both procedures. Along with a standard production effect and directed forgetting effect in the mixed-list conditions, we found evidence for strength primarily driving results in both procedures. Results are explained using a global matching model of recognition memory, MINERVA 2, by assuming varying levels of encoding strength in relation to task demands. Critically, we obtain the best fit using a strength mechanism over a combined strength and distinctiveness mechanism for our data.
基于项目的定向遗忘效应被解释为人们对记忆线索提示的目标和遗忘线索提示的目标进行编码的强度差异。相比之下,生成效应通常被解释为对生成的目标和未生成的目标的记忆独特性差异。这两种效应的程序匹配——引导参与者记忆或遗忘、生成或不生成——再加上它们不同的理论解释(即强度与独特性),为研究精细化编码的共同效应和差异效应提供了契机。本研究旨在通过比较识别情境下定向遗忘和生成效应的差异,弥合这两个已被充分证实的现象之间的差距。混合列表设计和纯列表设计被用于为这两种程序中的每种机制提供指标。除了在混合列表条件下出现标准的生成效应和定向遗忘效应外,我们还发现证据表明强度在这两种程序中都是驱动结果的主要因素。通过假设与任务需求相关的不同编码强度水平,使用识别记忆的全局匹配模型MINERVA 2对结果进行了解释。至关重要的是,对于我们的数据,使用强度机制比使用强度和独特性相结合的机制能获得更好的拟合。