Tan Li, Mengshan Li, Yu Fu, Yelin Li, Jihong Zhu, Lixin Guan
College of Physics and Electronic Information, Gannan Normal University, Ganzhou, 341000, Jiangxi, China.
Ganzhou Power Supply Branch of State Grid Jiangxi Electric Power Co., Ltd, Ganzhou, 341000, Jiangxi, China.
BMC Genomics. 2024 Dec 28;25(1):1253. doi: 10.1186/s12864-024-11168-3.
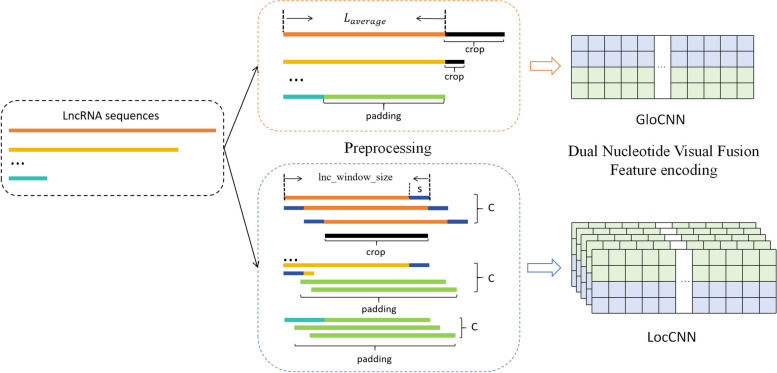
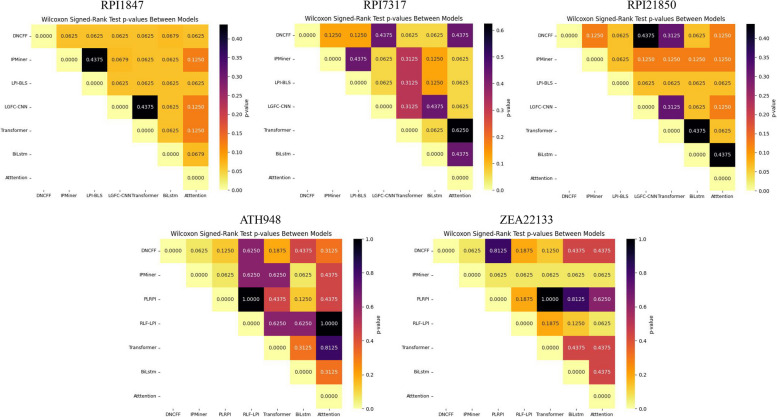
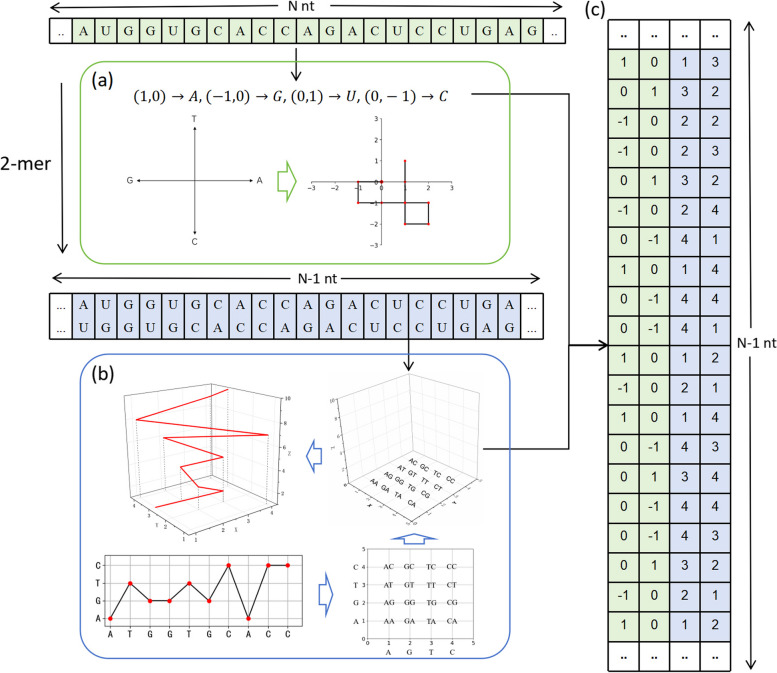
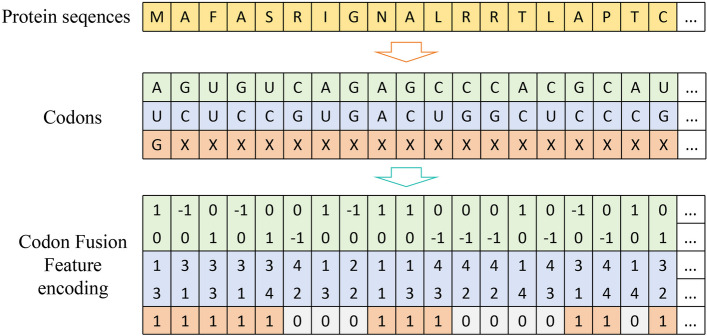
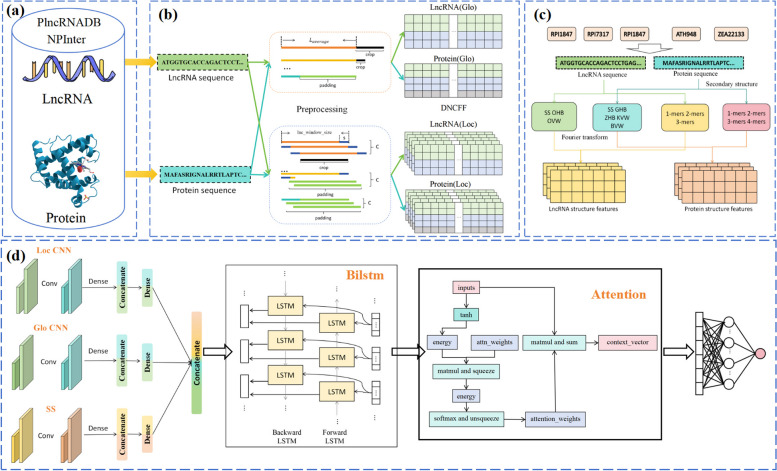
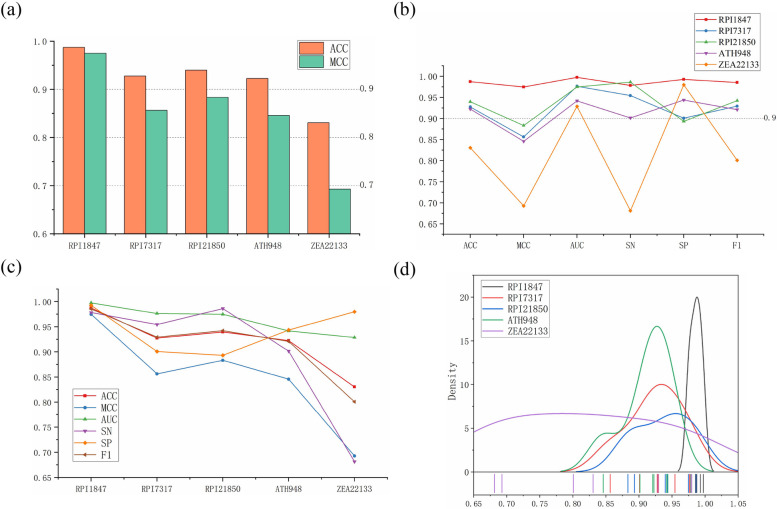
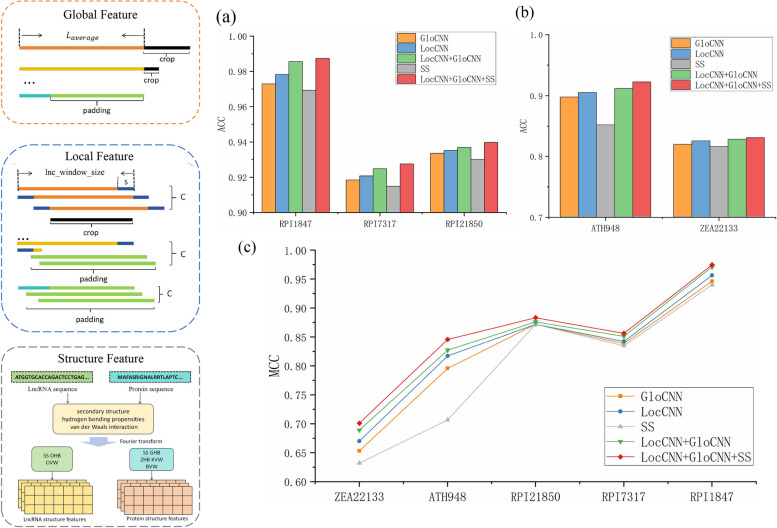
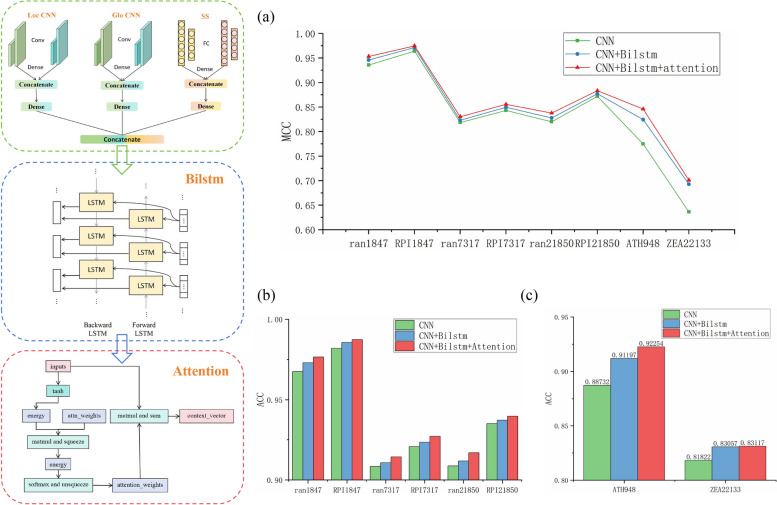
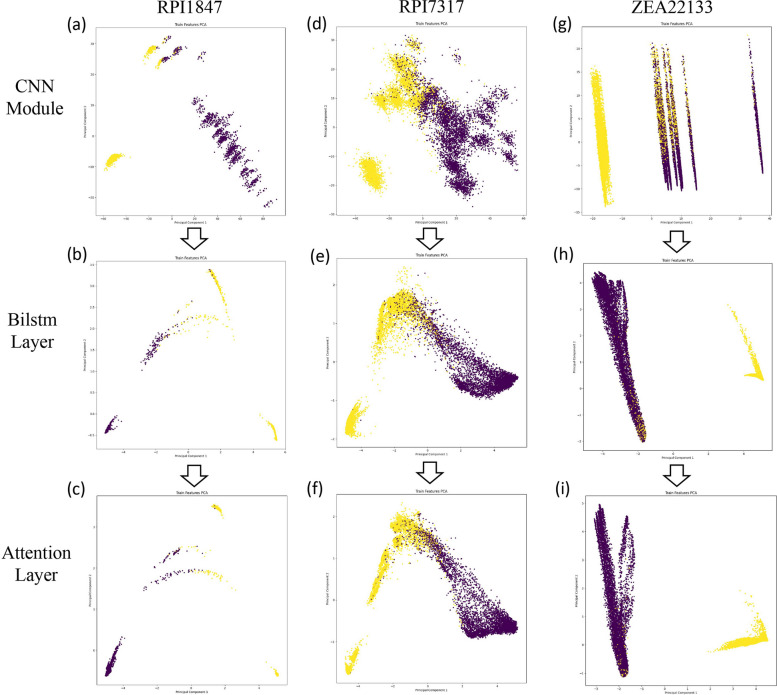
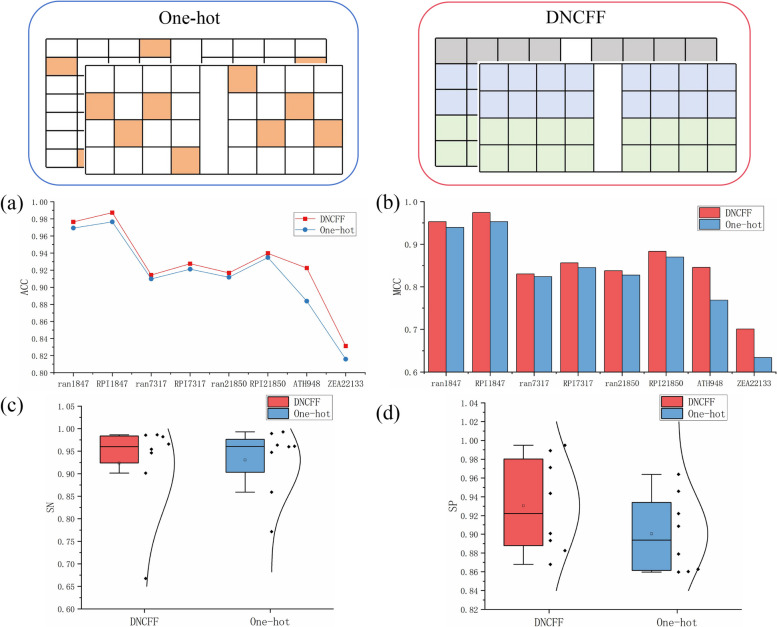
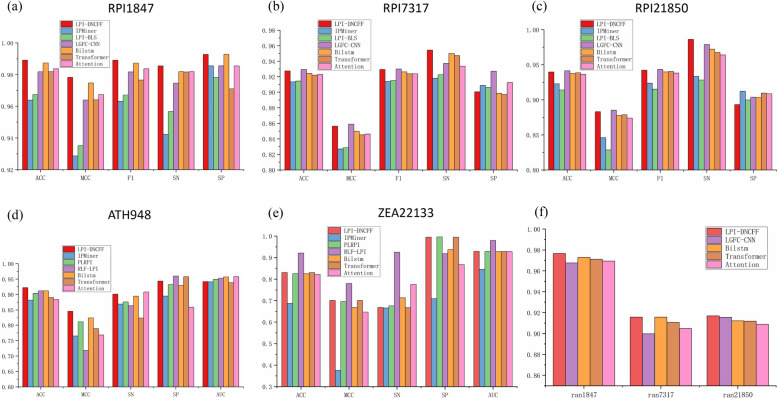
Long non-coding RNAs (lncRNAs) play crucial roles in numerous biological processes and are involved in complex human diseases through interactions with proteins. Accurate identification of lncRNA-protein interactions (LPI) can help elucidate the functional mechanisms of lncRNAs and provide scientific insights into the molecular mechanisms underlying related diseases. While many sequence-based methods have been developed to predict LPIs, efficiently extracting and effectively integrating potential feature information that reflects functional attributes from lncRNA and protein sequences remains a significant challenge. This paper proposes a Dinucleotide-Codon Fusion Feature encoding (DNCFF) and constructs an LPI prediction model based on deep learning, termed LPI-DNCFF. The Dual Nucleotide Visual Fusion Feature encoding (DNVFF) incorporates positional information of single nucleotides with subsequent nucleotide connections, while Codon Fusion Feature encoding (CFF) considers the specificity, molecular weight, and physicochemical properties of each amino acid. These encoding methods encapsulate rich and intuitive sequence information in limited encoding dimensions. The model comprehensively predicts LPIs by integrating global, local, and structural features, and inputs them into BiLSTM and attention layers to form a hybrid deep learning model. Experimental results demonstrate that LPI-DNCFF effectively predicts LPIs. The BiLSTM layer and attention mechanism can learn long-term dependencies and identify weighted key features, enhancing model performance. Compared to one-hot encoding, DNCFF more efficiently and thoroughly extracts potential sequence features. Compared to other existing methods, LPI-DNCFF achieved the best performance on the RPI1847 and ATH948 datasets, with MCC values of approximately 97.84% and 84.58%, respectively, outperforming the state-of-the-art method by about 1.44% and 3.48%.
长链非编码RNA(lncRNAs)在众多生物过程中发挥着关键作用,并通过与蛋白质相互作用参与复杂的人类疾病。准确识别lncRNA-蛋白质相互作用(LPI)有助于阐明lncRNAs的功能机制,并为相关疾病的分子机制提供科学见解。虽然已经开发了许多基于序列的方法来预测LPI,但从lncRNA和蛋白质序列中有效提取并有效整合反映功能属性的潜在特征信息仍然是一项重大挑战。本文提出了一种二核苷酸-密码子融合特征编码(DNCFF),并构建了一个基于深度学习的LPI预测模型,称为LPI-DNCFF。双核苷酸视觉融合特征编码(DNVFF)将单核苷酸的位置信息与后续核苷酸连接相结合,而密码子融合特征编码(CFF)则考虑了每个氨基酸的特异性、分子量和理化性质。这些编码方法在有限的编码维度中封装了丰富而直观的序列信息。该模型通过整合全局、局部和结构特征来全面预测LPI,并将其输入到双向长短期记忆网络(BiLSTM)和注意力层中,形成一个混合深度学习模型。实验结果表明,LPI-DNCFF能够有效地预测LPI。BiLSTM层和注意力机制可以学习长期依赖性并识别加权关键特征,从而提高模型性能。与独热编码相比,DNCFF能更高效、更全面地提取潜在序列特征。与其他现有方法相比,LPI-DNCFF在RPI1847和ATH948数据集上取得了最佳性能,马修斯相关系数(MCC)值分别约为97.84%和84.58%,比现有最先进的方法分别高出约1.44%和3.48%。