Galanty Maria, Luitse Dieuwertje, Noteboom Sijm H, Croon Philip, Vlaar Alexander P, Poell Thomas, Sanchez Clara I, Blanke Tobias, Išgum Ivana
Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands.
Department of Biomedical Engineering and Physics, Amsterdam UMC location University of Amsterdam, Amsterdam, The Netherlands.
Sci Rep. 2024 Dec 30;14(1):31846. doi: 10.1038/s41598-024-83218-5.
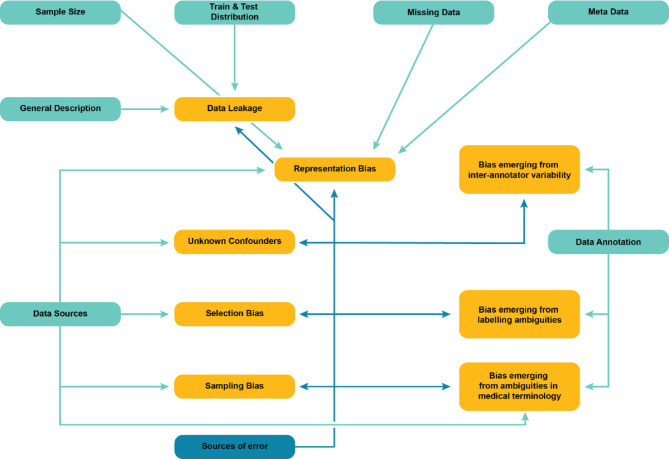
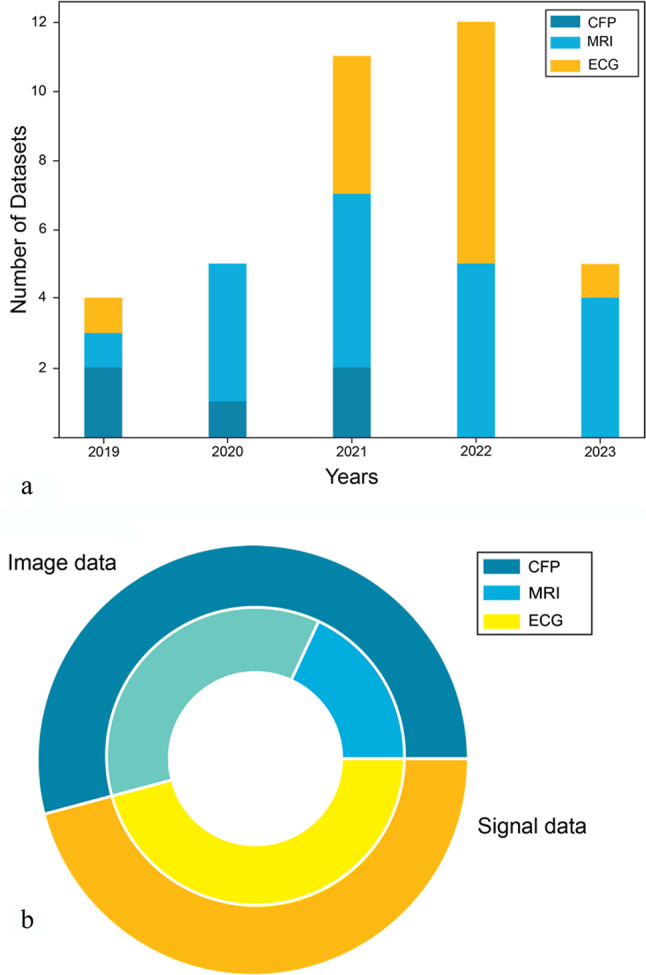
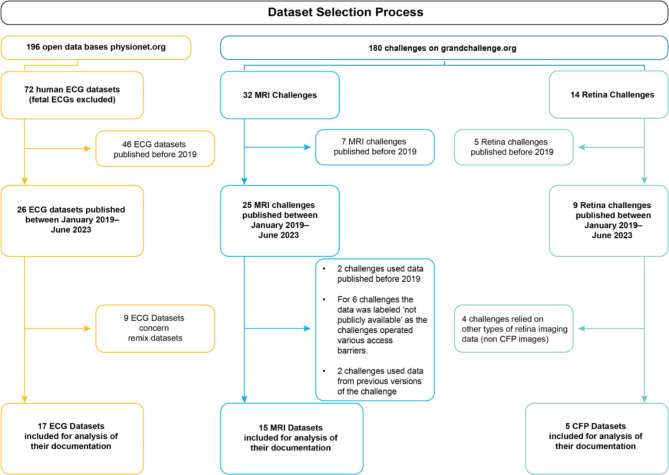
Medical datasets are vital for advancing Artificial Intelligence (AI) in healthcare. Yet biases in these datasets on which deep-learning models are trained can compromise reliability. This study investigates biases stemming from dataset-creation practices. Drawing on existing guidelines, we first developed a BEAMRAD tool to assess the documentation of public Magnetic Resonance Imaging (MRI); Color Fundus Photography (CFP), and Electrocardiogram (ECG) datasets. In doing so, we provide an overview of the biases that may emerge due to inadequate dataset documentation. Second, we examine the current state of documentation for public medical images and signal data. Our research reveals that there is substantial variance in the documentation of image and signal datasets, even though guidelines have been developed in medical imaging. This indicates that dataset documentation is subject to individual discretionary decisions. Furthermore, we find that aspects such as hardware and data acquisition details are commonly documented, while information regarding data annotation practices, annotation error quantification, or data limitations are not consistently reported. This risks having considerable implications for the abilities of data users to detect potential sources of bias through these respective aspects and develop reliable and robust models that can be adapted for clinical practice.
医学数据集对于推动医疗保健领域的人工智能(AI)至关重要。然而,用于训练深度学习模型的这些数据集中的偏差可能会损害可靠性。本研究调查了源自数据集创建实践的偏差。借鉴现有指南,我们首先开发了一种BEAMRAD工具,以评估公开的磁共振成像(MRI)、彩色眼底摄影(CFP)和心电图(ECG)数据集的文档记录。在此过程中,我们概述了由于数据集文档记录不足可能出现的偏差。其次,我们研究了公开医学图像和信号数据的文档记录现状。我们的研究表明,尽管医学成像领域已经制定了指南,但图像和信号数据集的文档记录仍存在很大差异。这表明数据集文档记录受个人自由裁量决定的影响。此外,我们发现硬件和数据采集细节等方面通常会被记录,而关于数据标注实践、标注误差量化或数据限制的信息并未得到一致报告。这可能会对数据用户通过这些方面检测潜在偏差来源以及开发适用于临床实践的可靠且强大模型的能力产生重大影响。