Van Kyujung, Lee Sungwoo, Mian M A Rouf, McHale Leah K
Department of Horticulture and Crop Science, The Ohio State University, Columbus, OH, 43210, USA.
Department of Crop Science, Chungnam National University, Daejeon, 34134, South Korea.
BMC Genomics. 2025 Jan 8;26(1):21. doi: 10.1186/s12864-024-11163-8.
Additional to total protein content, the amino acid (AA) profile is important to the nutritional value of soybean seed. The AA profile in soybean seed is a complex quantitative trait controlled by multiple interconnected genes and pathways controlling the accumulation of each AA. With a total of 621 soybean germplasm, we used three genome-wide association study (GWAS)-based approaches to investigate the genomic regions controlling the AA content and profile in soybean. Among those approaches, the GWAS network analysis we implemented takes advantage of the relationships between specific AAs to identify the genetic control of AA profile.
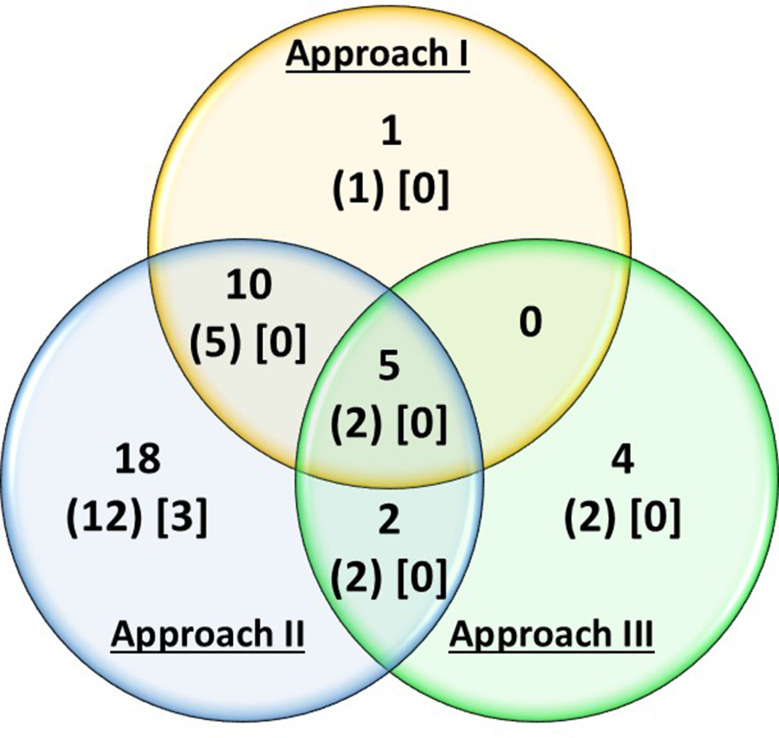
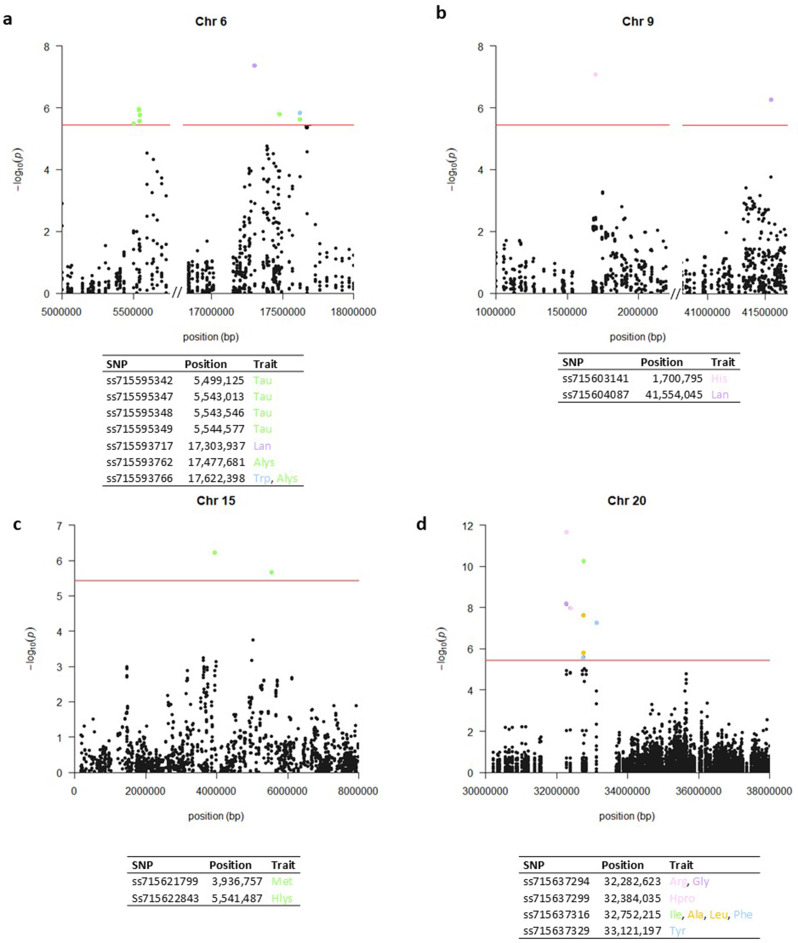
For Approach I, GWAS were performed for the content of 24 single AAs under all environments combined. Significant SNPs grouping into 16 linkage disequilibrium (LD) blocks from 18 traits were identified. For Approach II, the individual AAs were grouped by five families according to their metabolic pathways and were examined based on the sum, ratios, and interactions of AAs within the same biochemical family. Significant SNPs grouping into 35 LD blocks were identified, with SNPs associated with traits from the same biochemical family often positioned on the same LD blocks. Approach III, a correlation-based network analysis, was performed to assess the empirical relationships among AAs. Two groups were described by the network topology, Group 1: Ala, Gly, Lys, available Lys (Alys), and Thr and Group 2: Ile and Tyr. Significant SNPs associated with a ratio of connected AAs or a ratio of a single AA to its fully or partially connected metabolic groups were identified within 9 LD blocks for Group 1 and 2 LD blocks for Group 2. Among 40 identified QTL for AA or AA-derived traits, three genomic regions were novel in terms of seed composition traits (oil, protein, and AA content). An additional 24 regions had previously not been specifically associated with the AA content.
Our results confirmed loci identified from previous studies but also suggested that network approaches for studying AA contents in soybean seed are valuable. Three genomic regions (Chr 5: 41,754,397-41,893,109 bp, Chr 9: 1,537,829-1,806,586 bp, and Chr 20: 31,554,795-33,678,257 bp) were significantly identified by all three approaches. Yet, the majority of associations between a genomic region and an AA trait were approach- and/or environment-specific. Using a combination of approaches provides insights into the genetic control and pleiotropy among AA contents, which can be applied to mechanistic understanding of variation in AA content as well as tailored nutrition in cultivars developed from soybean breeding programs.
除了总蛋白含量外,氨基酸(AA)组成对大豆种子的营养价值也很重要。大豆种子中的氨基酸组成是一个复杂的数量性状,由多个相互关联的基因和控制每种氨基酸积累的途径所控制。我们利用621份大豆种质资源,采用三种基于全基因组关联研究(GWAS)的方法,研究控制大豆中氨基酸含量和组成的基因组区域。在这些方法中,我们实施的GWAS网络分析利用特定氨基酸之间的关系来确定氨基酸组成的遗传控制。
对于方法一,在所有环境组合下对24种单一氨基酸的含量进行了GWAS分析。从18个性状中鉴定出显著的单核苷酸多态性(SNP),它们被分组到16个连锁不平衡(LD)块中。对于方法二,根据代谢途径将单个氨基酸分为五个家族,并根据同一生化家族内氨基酸的总和、比例和相互作用进行检测。鉴定出分组到35个LD块中的显著SNP,来自同一生化家族的性状相关SNP通常位于同一LD块上。方法三,进行了基于相关性的网络分析,以评估氨基酸之间的经验关系。网络拓扑结构描述了两组,第1组:丙氨酸、甘氨酸、赖氨酸、有效赖氨酸(Alys)和苏氨酸;第2组:异亮氨酸和酪氨酸。在第1组的9个LD块和第2组的2个LD块中,鉴定出与连接氨基酸比例或单个氨基酸与其完全或部分连接的代谢组比例相关的显著SNP。在40个已鉴定的氨基酸或氨基酸衍生性状的数量性状位点(QTL)中,就种子组成性状(油、蛋白质和氨基酸含量)而言,有三个基因组区域是新发现的。另外24个区域以前没有与氨基酸含量特异性相关。
我们的结果证实了先前研究中鉴定出的位点,但也表明研究大豆种子中氨基酸含量的网络方法是有价值的。所有三种方法都显著鉴定出三个基因组区域(第5号染色体:41754397 - 41893109 bp,第9号染色体:1537829 - 1806586 bp,第20号染色体:31554795 - 33678257 bp)。然而,基因组区域与氨基酸性状之间的大多数关联是方法特异性和/或环境特异性的。结合多种方法可以深入了解氨基酸含量之间的遗传控制和多效性,这可应用于对氨基酸含量变异的机制理解以及大豆育种计划培育品种的定制营养。