Stoneman Hayley R, Price Adelle M, Trout Nikole Scribner, Lamont Riley, Tifour Souha, Pozdeyev Nikita, Crooks Kristy, Lin Meng, Rafaels Nicholas, Gignoux Christopher R, Marker Katie M, Hendricks Audrey E
Department of Biomedical Informatics, University of Colorado Anschutz Medical Campus, Aurora, CO 80045, USA; Human Medical Genetics and Genomics Program, University of Colorado Anschutz Medical Campus, Aurora, CO 80045, USA.
Department of Biomedical Informatics, University of Colorado Anschutz Medical Campus, Aurora, CO 80045, USA; Mathematical and Statistical Sciences, University of Colorado Denver, Denver, CO 80204, USA.
Am J Hum Genet. 2025 Feb 6;112(2):235-253. doi: 10.1016/j.ajhg.2024.12.007. Epub 2025 Jan 16.
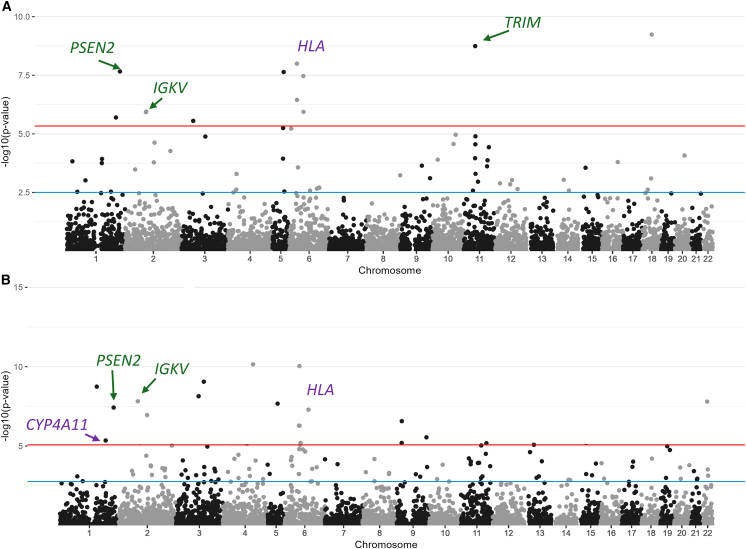
Genetic summary data are broadly accessible and highly useful, including for risk prediction, causal inference, fine mapping, and incorporation of external controls. However, collapsing individual-level data into summary data, such as allele frequencies, masks intra- and inter-sample heterogeneity, leading to confounding, reduced power, and bias. Ultimately, unaccounted-for substructure limits summary data usability, especially for understudied or admixed populations. There is a need for methods to enable the harmonization of summary data where the underlying substructure is matched between datasets. Here, we present Summix2, a comprehensive set of methods and software based on a computationally efficient mixture model to enable the harmonization of genetic summary data by estimating and adjusting for substructure. In extensive simulations and application to public data, we show that Summix2 characterizes finer-scale population structure, identifies ascertainment bias, and scans for potential regions of selection due to local substructure deviation. Summix2 increases the robust use of diverse, publicly available summary data, resulting in improved and more equitable research.
遗传汇总数据广泛可用且非常有用,包括用于风险预测、因果推断、精细定位以及纳入外部对照。然而,将个体水平的数据汇总为汇总数据,如等位基因频率,会掩盖样本内和样本间的异质性,导致混杂、功效降低和偏差。最终,未考虑的亚结构限制了汇总数据的可用性,特别是对于研究不足或混合人群。需要一些方法来实现汇总数据的协调,使数据集之间的潜在亚结构相匹配。在这里,我们提出了Summix2,这是一套基于计算效率高的混合模型的综合方法和软件,通过估计和调整亚结构来实现遗传汇总数据的协调。在广泛的模拟和对公共数据的应用中,我们表明Summix2能够刻画更精细尺度的群体结构,识别确定偏差,并扫描由于局部亚结构偏差导致的潜在选择区域。Summix2增加了对多样的、公开可用的汇总数据的稳健使用,从而带来更好且更公平的研究。