Rajagopal Nandhini, Choudhary Udit, Tsang Kenny, Martin Kyle P, Karadag Murat, Chen Hsin-Ting, Kwon Na-Young, Mozdzierz Joseph, Horspool Alexander M, Li Li, Tessier Peter M, Marlow Michael S, Nixon Andrew E, Kumar Sandeep
Biotherapeutics Molecule Discovery, Boehringer Ingelheim Pharmaceutical Inc., 900 Ridgebury Road, Ridgefield, CT 06877, United States.
Global Computational Biology and Digital Sciences, Boehringer Ingelheim Pharmaceutical Inc., 900 Ridgebury Road, Ridgefield, CT 06877, United States.
Brief Bioinform. 2024 Nov 22;26(1). doi: 10.1093/bib/bbaf023.
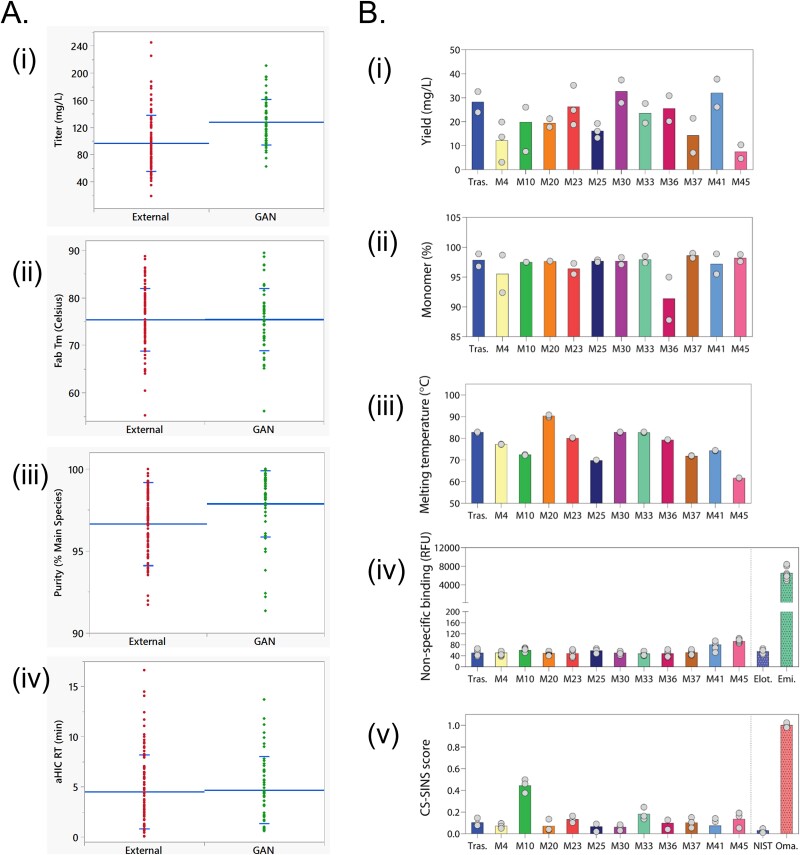
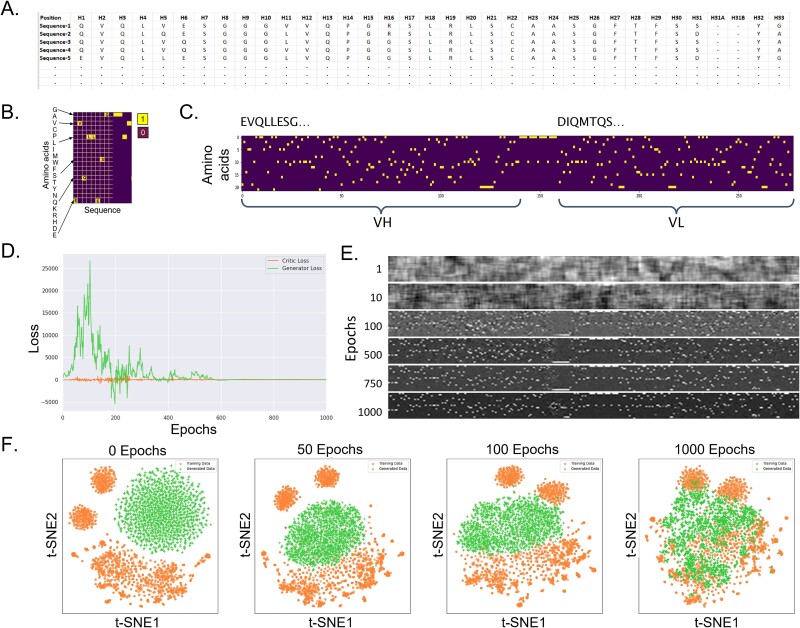
Antibody generation requires the use of one or more time-consuming methods, namely animal immunization, and in vitro display technologies. However, the recent availability of large amounts of antibody sequence and structural data in the public domain along with the advent of generative deep learning algorithms raises the possibility of computationally generating novel antibody sequences with desirable developability attributes. Here, we describe a deep learning model for computationally generating libraries of highly human antibody variable regions whose intrinsic physicochemical properties resemble those of the variable regions of the marketed antibody-based biotherapeutics (medicine-likeness). We generated 100000 variable region sequences of antigen-agnostic human antibodies belonging to the IGHV3-IGKV1 germline pair using a training dataset of 31416 human antibodies that satisfied our computational developability criteria. The in-silico generated antibodies recapitulate intrinsic sequence, structural, and physicochemical properties of the training antibodies, and compare favorably with the experimentally measured biophysical attributes of 100 variable regions of marketed and clinical stage antibody-based biotherapeutics. A sample of 51 highly diverse in-silico generated antibodies with >90th percentile medicine-likeness and > 90% humanness was evaluated by two independent experimental laboratories. Our data show the in-silico generated sequences exhibit high expression, monomer content, and thermal stability along with low hydrophobicity, self-association, and non-specific binding when produced as full-length monoclonal antibodies. The ability to computationally generate developable human antibody libraries is a first step towards enabling in-silico discovery of antibody-based biotherapeutics. These findings are expected to accelerate in-silico discovery of antibody-based biotherapeutics and expand the druggable antigen space to include targets refractory to conventional antibody discovery methods requiring in vitro antigen production.
抗体生成需要使用一种或多种耗时的方法,即动物免疫和体外展示技术。然而,随着公共领域中大量抗体序列和结构数据的出现以及生成式深度学习算法的问世,通过计算生成具有理想可开发性属性的新型抗体序列成为可能。在此,我们描述了一种深度学习模型,用于通过计算生成高度人源化抗体可变区文库,其内在物理化学性质类似于市售基于抗体的生物治疗药物(类药物性)的可变区。我们使用满足我们计算可开发性标准的31416个人源抗体训练数据集,生成了属于IGHV3 - IGKV1胚系对的100000个抗原非特异性人源抗体可变区序列。计算机模拟生成的抗体概括了训练抗体的内在序列、结构和物理化学性质,并且与市售和临床阶段基于抗体的生物治疗药物的100个可变区的实验测量生物物理属性相比具有优势。两个独立的实验实验室对51个具有>第90百分位数类药物性和>90%人源化的高度多样化计算机模拟生成抗体样本进行了评估。我们的数据表明,当作为全长单克隆抗体产生时,计算机模拟生成的序列表现出高表达、单体含量和热稳定性,同时具有低疏水性、自缔合性和非特异性结合。通过计算生成可开发人源抗体文库的能力是实现基于抗体的生物治疗药物计算机模拟发现的第一步。这些发现有望加速基于抗体的生物治疗药物的计算机模拟发现,并扩大可成药抗原空间,以包括对需要体外抗原生产的传统抗体发现方法具有抗性的靶点。