Kohandel Gargari Omid, Fathi Mobina, Rajai Firouzabadi Shahryar, Mohammadi Ida, Mahmoudi Mohammad Hossein, Sarmadi Mehran, Shafiee Arman
Alborz Artificial Intelligence Association, Alborz University of Medical Sciences, Karaj, Alborz, Iran.
Advanced Diagnostic and Interventional Radiology Research Center (ADIR), Tehran, Iran.
Sci Rep. 2025 Feb 6;15(1):4537. doi: 10.1038/s41598-025-88345-1.
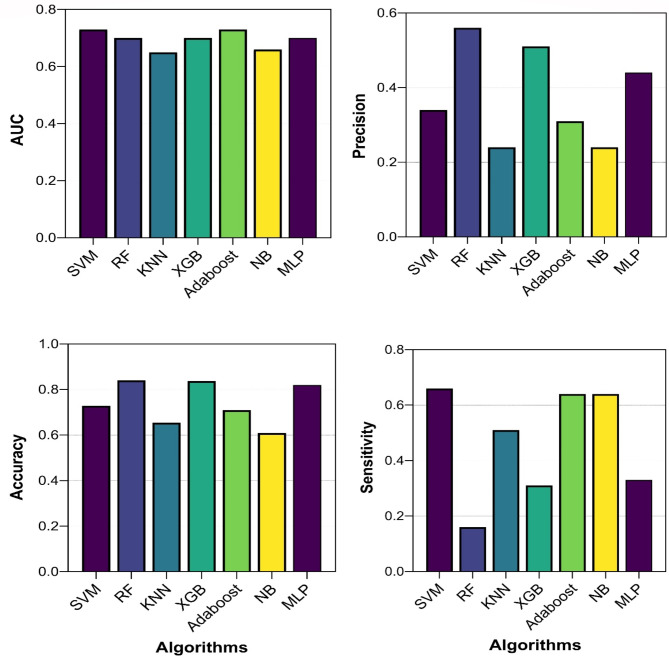
Asthma diagnosis poses challenges due to underreporting of symptoms, misdiagnoses, and limitations in existing diagnostic tests. Machine learning (ML) offers a promising avenue for addressing these challenges by leveraging demographic and clinical data. In this study, we aim to compare different ML diagnostic models and obtain the most valuable features for asthma diagnosis using data from the National Health and Nutrition Examination Survey (NHANES) dataset. A total of 8,888 participants with available asthma diagnosis data from the 2017-2018 NHANES survey were included. After careful selection of variables related to asthma, various ML algorithms including Support Vector Machine (SVM), Random Forest (RF), AdaBoost (ADA), XGBoost (XGB), K-Nearest Neighbors (KNN), Naive Bayes (NB), and Multi-Layer Perceptron (MLP) were evaluated. SVM and ADA emerged as top performers with the highest area under the curve (AUC) scores of 0.72 and 0.71, respectively. RF exhibited high accuracy but low precision. Feature interpretation using SHapley Additive exPlanations (SHAP) values identified significant predictors such as close relative asthma history, dietary fat intake, and chronic bronchitis. Feature reduction experiments showed promising results without significant loss in predictive performance. Our findings demonstrate the potential diagnosis ability of ML algorithms, particularly SVM and ADA, in asthma diagnosis by incorporating diverse clinical and demographic factors. In addition, close relative asthma history, dietary fat intake, and chronic bronchitis could be suggested as the valuable asthma diagnosis features. These outcomes can bring promising results in early diagnosis of asthma.
由于症状报告不足、误诊以及现有诊断测试的局限性,哮喘诊断面临诸多挑战。机器学习(ML)通过利用人口统计学和临床数据,为应对这些挑战提供了一条有前景的途径。在本研究中,我们旨在比较不同的ML诊断模型,并利用来自国家健康与营养检查调查(NHANES)数据集的数据,获取用于哮喘诊断的最有价值特征。总共纳入了8888名来自2017 - 2018年NHANES调查且有可用哮喘诊断数据的参与者。在仔细选择与哮喘相关的变量后,评估了各种ML算法,包括支持向量机(SVM)、随机森林(RF)、自适应增强(ADA)、极端梯度提升(XGB)、K近邻(KNN)、朴素贝叶斯(NB)和多层感知器(MLP)。SVM和ADA表现最佳,曲线下面积(AUC)得分分别最高,为0.72和0.71。RF显示出高准确率但低精确率。使用SHapley值加法解释(SHAP)进行特征解释,确定了诸如近亲哮喘病史、膳食脂肪摄入量和慢性支气管炎等重要预测因素。特征约简实验显示出有前景的结果,且预测性能没有显著损失。我们的研究结果表明,ML算法,特别是SVM和ADA,通过纳入多种临床和人口统计学因素,在哮喘诊断中具有潜在的诊断能力。此外,近亲哮喘病史、膳食脂肪摄入量和慢性支气管炎可被建议作为有价值的哮喘诊断特征。这些结果在哮喘早期诊断方面可能带来有前景的成果。