Ahmed Syed Rakin, Befano Brian, Egemen Didem, Rodriguez Ana Cecilia, Desai Kanan T, Jeronimo Jose, Ajenifuja Kayode O, Clark Christopher, Perkins Rebecca, Campos Nicole G, Inturrisi Federica, Wentzensen Nicolas, Han Paul, Guillen Diego, Norman Judy, Goldstein Andrew T, Madeleine Margaret M, Donastorg Yeycy, Schiffman Mark, de Sanjose Silvia, Kalpathy-Cramer Jayashree
Athinoula A. Martinos Center for Biomedical Imaging, Department of Radiology, Massachusetts General Hospital, Boston, MA, 02129, USA.
Harvard Graduate Program in Biophysics, Harvard Medical School, Harvard University, Cambridge, MA, 02115, USA.
Sci Rep. 2025 Feb 21;15(1):6312. doi: 10.1038/s41598-025-90024-0.
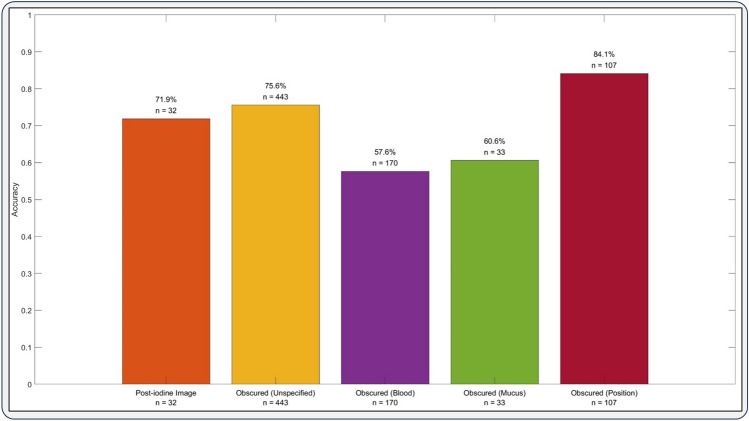
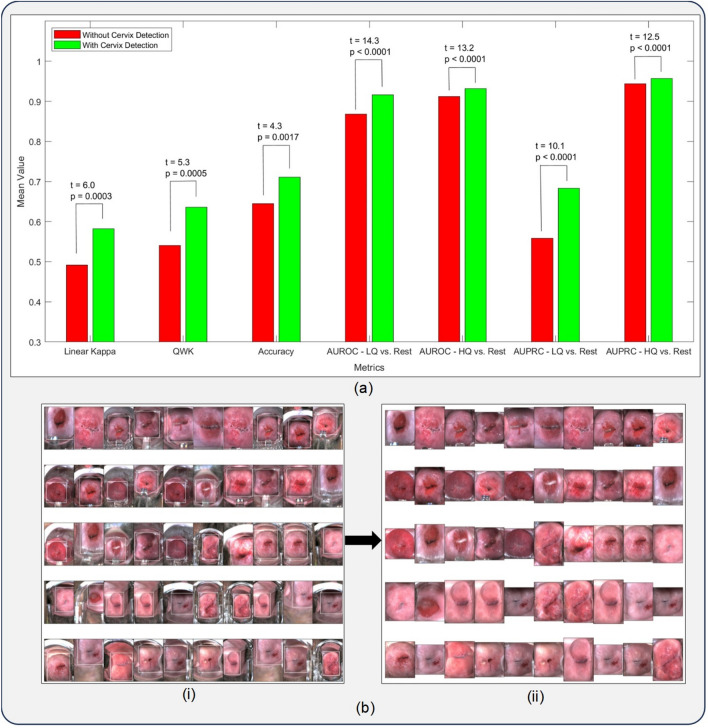
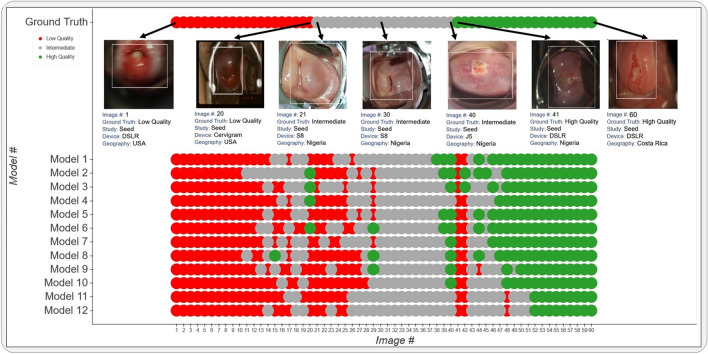
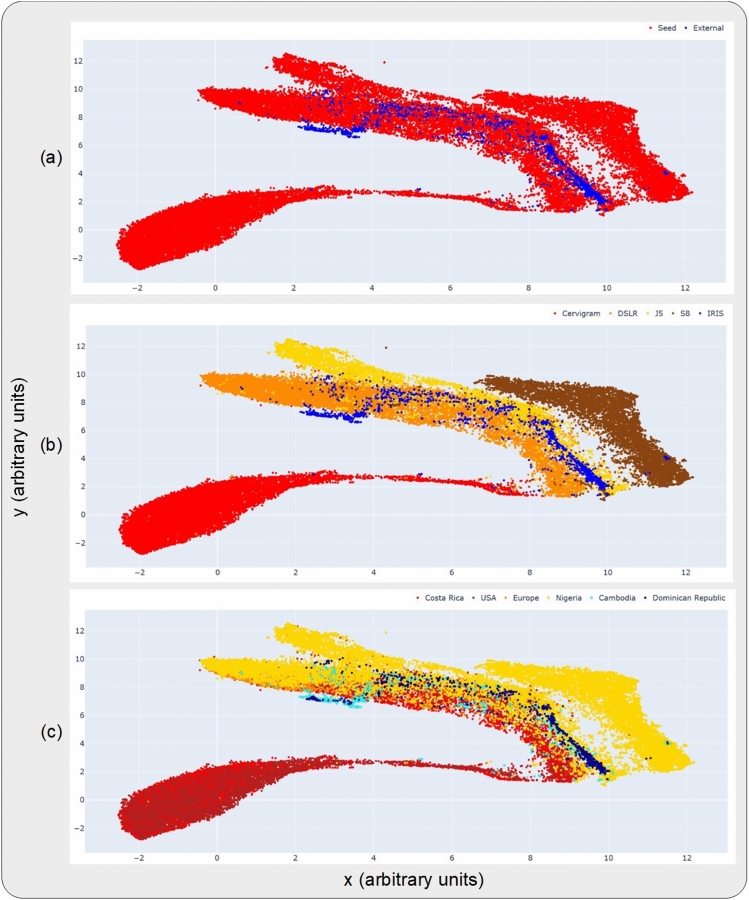
Successful translation of artificial intelligence (AI) models into clinical practice, across clinical domains, is frequently hindered by the lack of image quality control. Diagnostic models are often trained on images with no denotation of image quality in the training data; this, in turn, can lead to misclassifications by these models when implemented in the clinical setting. In the case of cervical images, quality classification is a crucial task to ensure accurate detection of precancerous lesions or cancer; this is true for both gynecologic-oncologists' (manual) and diagnostic AI models' (automated) predictions. Factors that impact the quality of a cervical image include but are not limited to blur, poor focus, poor light, noise, obscured view of the cervix due to mucus and/or blood, improper position, and over- and/or under-exposure. Utilizing a multi-level image quality ground truth denoted by providers, we generated an image quality classifier following a multi-stage model selection process that investigated several key design choices on a multi-heterogenous "SEED" dataset of 40,534 images. We subsequently validated the best model on an external dataset ("EXT"), comprising 1,340 images captured using a different device and acquired in different geographies from "SEED". We assessed the relative impact of various axes of data heterogeneity, including device, geography, and ground-truth rater on model performance. Our best performing model achieved an area under the receiver operating characteristics curve (AUROC) of 0.92 (low quality, LQ vs. rest) and 0.93 (high quality, HQ vs. rest), and a minimal total %extreme misclassification (%EM) of 2.8% on the internal validation set. Our model also generalized well externally, achieving corresponding AUROCs of 0.83 and 0.82, and %EM of 3.9% when tested out-of-the-box on the external validation ("EXT") set. Additionally, our model was geography agnostic with no meaningful difference in performance across geographies, did not exhibit catastrophic forgetting upon retraining with new data, and mimicked the overall/average ground truth rater behavior well. Our work represents one of the first efforts at generating and externally validating an image quality classifier across multiple axes of data heterogeneity to aid in visual diagnosis of cervical precancer and cancer. We hope that this will motivate the accompaniment of adequate guardrails for AI-based pipelines to account for image quality and generalizability concerns.
人工智能(AI)模型在临床实践中的成功应用,在各个临床领域,常常因缺乏图像质量控制而受阻。诊断模型通常是在训练数据中没有图像质量标注的图像上进行训练的;反过来,当这些模型应用于临床环境时,可能会导致错误分类。对于宫颈图像而言,质量分类是确保准确检测癌前病变或癌症的关键任务;这对于妇科肿瘤学家(手动)和诊断AI模型(自动)的预测都是如此。影响宫颈图像质量的因素包括但不限于模糊、对焦不佳、光线不足、噪声、因黏液和/或血液导致的宫颈视野模糊、位置不当以及曝光过度和/或曝光不足。利用提供者标注的多层次图像质量真值,我们在一个包含40,534张图像的多异质“SEED”数据集上,经过一个研究了几个关键设计选择的多阶段模型选择过程,生成了一个图像质量分类器。随后,我们在一个外部数据集(“EXT”)上验证了最佳模型,该数据集包含1,340张使用不同设备拍摄且在与“SEED”不同的地理位置获取的图像。我们评估了数据异质性的各个维度,包括设备、地理位置和真值评估者对模型性能的相对影响。我们表现最佳的模型在内部验证集上,受试者操作特征曲线下面积(AUROC)在低质量(LQ与其他)情况下为0.92,在高质量(HQ与其他)情况下为0.93,最小总极端错误分类率(%EM)为2.8%。我们的模型在外部也具有良好的泛化能力,在外部验证(“EXT”)集上开箱即用测试时,相应的AUROC为0.83和0.82,%EM为3.9%。此外,我们的模型与地理位置无关,在不同地理位置的性能没有显著差异,在用新数据重新训练时没有表现出灾难性遗忘,并且很好地模仿了总体/平均真值评估者的行为。我们的工作是在跨数据异质性的多个维度生成并外部验证图像质量分类器以辅助宫颈癌症前病变和癌症的视觉诊断方面的首批努力之一。我们希望这将促使为基于AI的流程配备适当的保障措施,以解决图像质量和泛化性问题。