Ahmed Syed Rakin, Egemen Didem, Befano Brian, Rodriguez Ana Cecilia, Jeronimo Jose, Desai Kanan, Teran Carolina, Alfaro Karla, Fokom-Domgue Joel, Charoenkwan Kittipat, Mungo Chemtai, Luckett Rebecca, Saidu Rakiya, Raiol Taina, Ribeiro Ana, Gage Julia C, de Sanjose Silvia, Kalpathy-Cramer Jayashree, Schiffman Mark
Athinoula A. Martinos Center for Biomedical Imaging, Department of Radiology, Massachusetts General Hospital, Boston, Massachusetts, United States of America.
Harvard Graduate Program in Biophysics, Harvard Medical School, Harvard University, Cambridge, Massachusetts, United States of America.
PLOS Digit Health. 2024 Oct 2;3(10):e0000364. doi: 10.1371/journal.pdig.0000364. eCollection 2024 Oct.
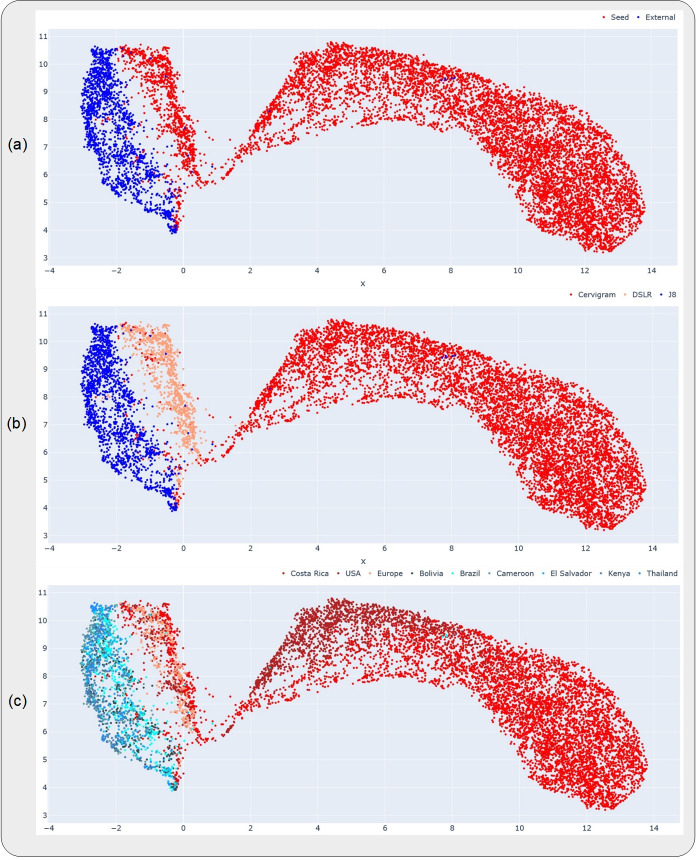
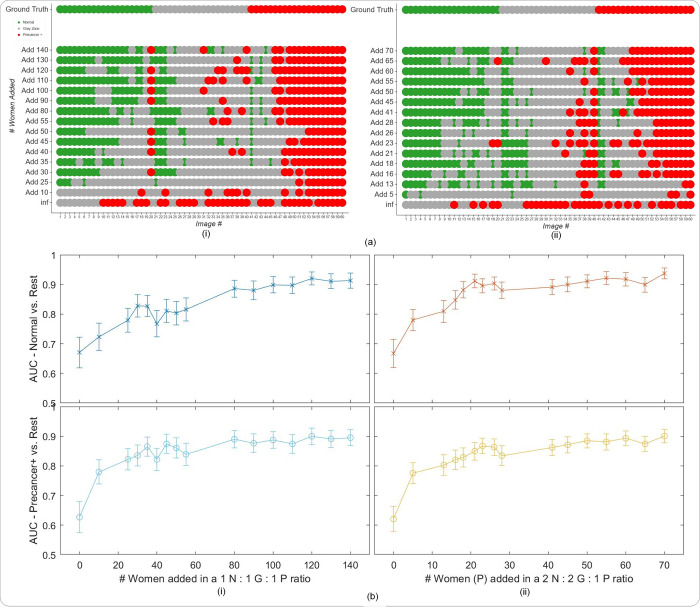
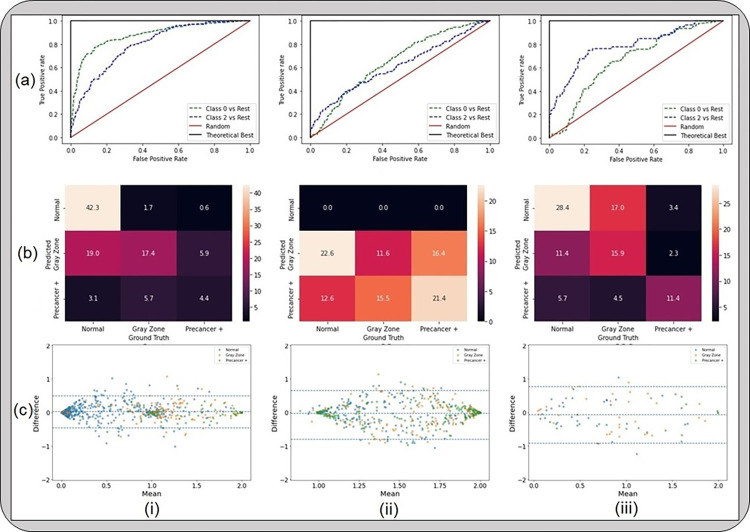
A number of challenges hinder artificial intelligence (AI) models from effective clinical translation. Foremost among these challenges is the lack of generalizability, which is defined as the ability of a model to perform well on datasets that have different characteristics from the training data. We recently investigated the development of an AI pipeline on digital images of the cervix, utilizing a multi-heterogeneous dataset of 9,462 women (17,013 images) and a multi-stage model selection and optimization approach, to generate a diagnostic classifier able to classify images of the cervix into "normal", "indeterminate" and "precancer/cancer" (denoted as "precancer+") categories. In this work, we investigate the performance of this multiclass classifier on external data not utilized in training and internal validation, to assess the generalizability of the classifier when moving to new settings. We assessed both the classification performance and repeatability of our classifier model across the two axes of heterogeneity present in our dataset: image capture device and geography, utilizing both out-of-the-box inference and retraining with external data. Our results demonstrate that device-level heterogeneity affects our model performance more than geography-level heterogeneity. Classification performance of our model is strong on images from a new geography without retraining, while incremental retraining with inclusion of images from a new device progressively improves classification performance on that device up to a point of saturation. Repeatability of our model is relatively unaffected by data heterogeneity and remains strong throughout. Our work supports the need for optimized retraining approaches that address data heterogeneity (e.g., when moving to a new device) to facilitate effective use of AI models in new settings.
一些挑战阻碍了人工智能(AI)模型在临床中的有效应用。这些挑战中最主要的是缺乏通用性,通用性被定义为模型在与训练数据具有不同特征的数据集上良好运行的能力。我们最近研究了一种针对子宫颈数字图像的AI流程开发,利用了一个包含9462名女性(17013张图像)的多异构数据集以及一种多阶段模型选择和优化方法,以生成一个能够将子宫颈图像分类为“正常”、“不确定”和“癌前病变/癌症”(表示为“癌前病变+”)类别的诊断分类器。在这项工作中,我们研究了这个多类分类器在训练和内部验证中未使用的外部数据上的性能,以评估该分类器在应用于新环境时的通用性。我们通过开箱即用的推理以及使用外部数据进行再训练,评估了分类器模型在数据集存在的两个异构轴(图像采集设备和地理位置)上的分类性能和可重复性。我们的结果表明,设备级异构性比地理级异构性对我们模型性能的影响更大。在不进行再训练的情况下,我们的模型在来自新地理位置的图像上分类性能很强,而通过纳入来自新设备的图像进行增量再训练,在该设备上的分类性能会逐步提高,直至达到饱和点。我们模型的可重复性相对不受数据异构性的影响,并且始终保持很强。我们的工作支持需要优化再训练方法来解决数据异构性(例如,当迁移到新设备时),以促进在新环境中有效使用AI模型。