Division of Cancer Epidemiology and Genetics, National Cancer Institute, National Institutes of Health, Rockville, MD, USA.
Department of Obstetrics and Gynecology, Boston Medical Center/Boston University School of Medicine, Boston, MA, USA.
J Natl Cancer Inst. 2024 Jan 10;116(1):26-33. doi: 10.1093/jnci/djad202.
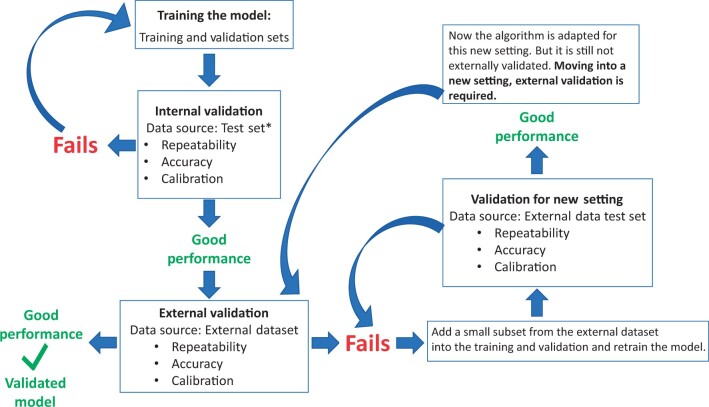
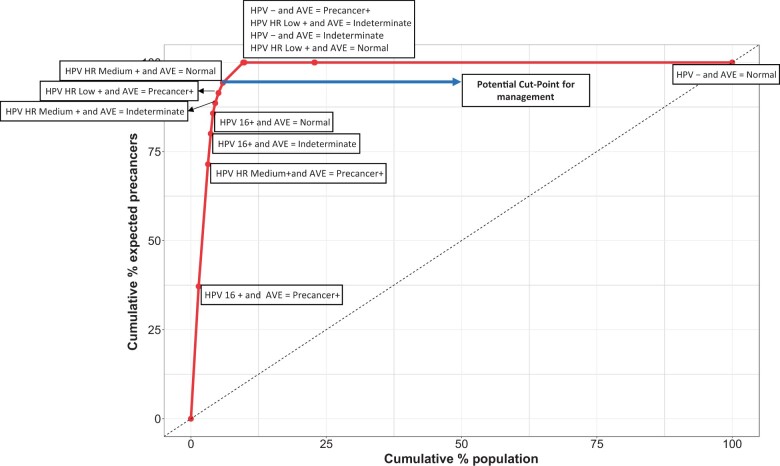
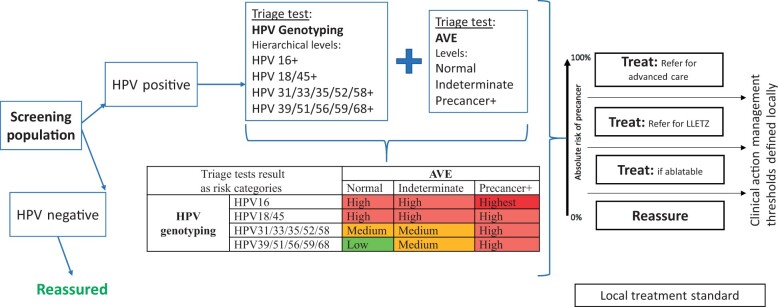
Novel screening and diagnostic tests based on artificial intelligence (AI) image recognition algorithms are proliferating. Some initial reports claim outstanding accuracy followed by disappointing lack of confirmation, including our own early work on cervical screening. This is a presentation of lessons learned, organized as a conceptual step-by-step approach to bridge the gap between the creation of an AI algorithm and clinical efficacy. The first fundamental principle is specifying rigorously what the algorithm is designed to identify and what the test is intended to measure (eg, screening, diagnostic, or prognostic). Second, designing the AI algorithm to minimize the most clinically important errors. For example, many equivocal cervical images cannot yet be labeled because the borderline between cases and controls is blurred. To avoid a misclassified case-control dichotomy, we have isolated the equivocal cases and formally included an intermediate, indeterminate class (severity order of classes: case>indeterminate>control). The third principle is evaluating AI algorithms like any other test, using clinical epidemiologic criteria. Repeatability of the algorithm at the borderline, for indeterminate images, has proven extremely informative. Distinguishing between internal and external validation is also essential. Linking the AI algorithm results to clinical risk estimation is the fourth principle. Absolute risk (not relative) is the critical metric for translating a test result into clinical use. Finally, generating risk-based guidelines for clinical use that match local resources and priorities is the last principle in our approach. We are particularly interested in applications to lower-resource settings to address health disparities. We note that similar principles apply to other domains of AI-based image analysis for medical diagnostic testing.
基于人工智能 (AI) 图像识别算法的新型筛查和诊断测试正在迅速普及。一些初步报告声称具有出色的准确性,但随后缺乏令人失望的确认,包括我们自己在宫颈癌筛查方面的早期工作。这是一个经验教训的总结,组织成一个概念性的逐步方法,以弥合 AI 算法的创建与临床疗效之间的差距。第一个基本原则是严格规定算法旨在识别的内容以及测试旨在测量的内容(例如,筛查、诊断或预后)。其次,设计 AI 算法以最小化最具临床意义的错误。例如,许多模棱两可的宫颈图像尚无法进行标记,因为病例和对照组之间的界限模糊。为了避免对病例-对照组的错误分类,我们已经将模棱两可的病例隔离出来,并正式纳入了一个中间的、不确定的类别(类别严重程度顺序:病例>不确定>对照)。第三个原则是像评估任何其他测试一样,使用临床流行病学标准来评估 AI 算法。在边界处对算法的可重复性进行评估,对于不确定的图像来说,这是非常有启发性的。区分内部验证和外部验证也是至关重要的。将 AI 算法结果与临床风险估计联系起来是第四个原则。将测试结果转化为临床应用的关键指标是绝对风险(而不是相对风险)。最后,根据临床使用生成基于风险的指南,这些指南与当地资源和优先事项相匹配,这是我们方法中的最后一个原则。我们特别关注将其应用于资源较少的环境,以解决健康差异问题。我们注意到,类似的原则适用于医学诊断测试中基于人工智能的图像分析的其他领域。