Akbasli Izzet Turkalp, Birbilen Ahmet Ziya, Teksam Ozlem
Division of Pediatric Emergency, Department of Pediatrics, Faculty of Medicine, Hacettepe University, Ankara, Turkey.
Life Support Center, Digital Health and Artificial Intelligence on Critical Care, Hacettepe University, Ankara, Turkey.
BMC Med Inform Decis Mak. 2025 Mar 31;25(1):154. doi: 10.1186/s12911-025-02871-6.
The integration of big data and artificial intelligence (AI) in healthcare, particularly through the analysis of electronic health records (EHR), presents significant opportunities for improving diagnostic accuracy and patient outcomes. However, the challenge of processing and accurately labeling vast amounts of unstructured data remains a critical bottleneck, necessitating efficient and reliable solutions. This study investigates the ability of domain specific, fine-tuned large language models (LLMs) to classify unstructured EHR texts with typographical errors through named entity recognition tasks, aiming to improve the efficiency and reliability of supervised learning AI models in healthcare.
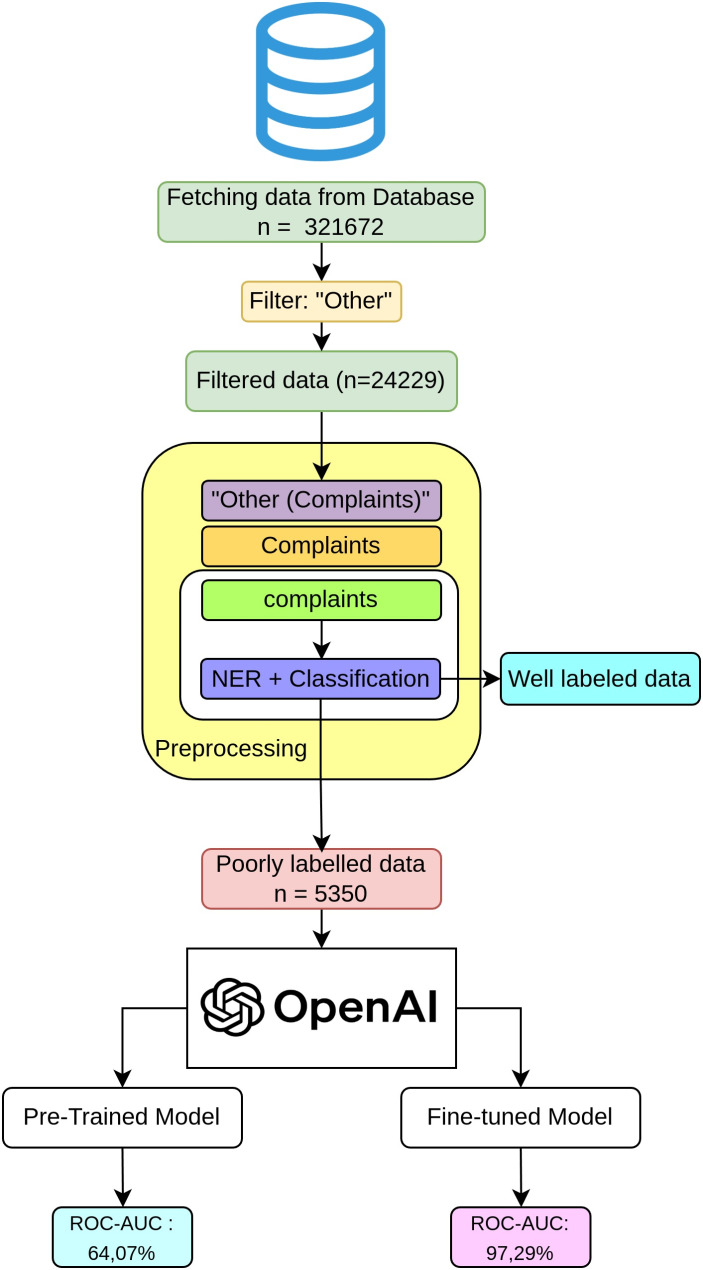
Turkish clinical notes from pediatric emergency room admissions at Hacettepe University İhsan Doğramacı Children's Hospital from 2018 to 2023 were analyzed. The data were preprocessed with open source Python libraries and categorized using a pretrained GPT-3 model, "text-davinci-003," before and after fine-tuning with domain-specific data on respiratory tract infections (RTI). The model's predictions were compared against ground truth labels established by pediatric specialists.
Out of 24,229 patient records classified as poorly labeled, 18,879 were identified without typographical errors and confirmed for RTI through filtering methods. The fine-tuned model achieved a 99.88% accuracy, significantly outperforming the pretrained model's 78.54% accuracy in identifying RTI cases among the remaining records. The fine-tuned model demonstrated superior performance metrics across all evaluated aspects compared to the pretrained model.
Fine-tuned LLMs can categorize unstructured EHR data with high accuracy, closely approximating the performance of domain experts. This approach significantly reduces the time and costs associated with manual data labeling, demonstrating the potential to streamline the processing of large-scale healthcare data for AI applications.
大数据和人工智能(AI)在医疗保健领域的整合,特别是通过电子健康记录(EHR)分析,为提高诊断准确性和患者治疗效果带来了重大机遇。然而,处理和准确标记大量非结构化数据的挑战仍然是一个关键瓶颈,需要高效且可靠的解决方案。本研究调查特定领域的微调大语言模型(LLMs)通过命名实体识别任务对存在排版错误的非结构化EHR文本进行分类的能力,旨在提高医疗保健中监督学习AI模型的效率和可靠性。
对2018年至2023年在哈杰泰佩大学伊赫桑·多格拉马西儿童医院儿科急诊室入院的土耳其语临床记录进行分析。使用开源Python库对数据进行预处理,并在使用呼吸道感染(RTI)的特定领域数据进行微调之前和之后,使用预训练的GPT-3模型“text-davinci-003”进行分类。将模型的预测结果与儿科专家确定的真实标签进行比较。
在24229份分类为标签不佳的患者记录中,有18879份被确定没有排版错误,并通过过滤方法确认为RTI。微调后的模型准确率达到99.88%,在识别其余记录中的RTI病例方面显著优于预训练模型的78.54%准确率。与预训练模型相比,微调后的模型在所有评估方面都表现出卓越的性能指标。
微调后的LLMs可以高精度地对非结构化EHR数据进行分类,性能与领域专家相近。这种方法显著减少了与人工数据标记相关的时间和成本,显示出为AI应用简化大规模医疗保健数据处理的潜力。