Mondal Agnibho, Naskar Arindam, Roy Choudhury Bhaskar, Chakraborty Sambudhya, Biswas Tanmay, Sinha Sumanta, Roy Sasmit
Department of Infectious Diseases and Advanced Microbiology, School of Tropical Medicine, Kolkata, IND.
Department of Endocrinology, Nutrition and Metabolic Diseases, School of Tropical Medicine, Kolkata, IND.
Cureus. 2025 Mar 17;17(3):e80737. doi: 10.7759/cureus.80737. eCollection 2025 Mar.
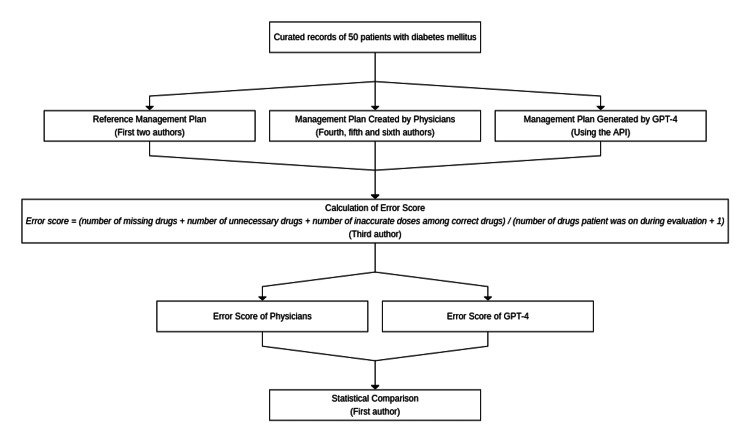
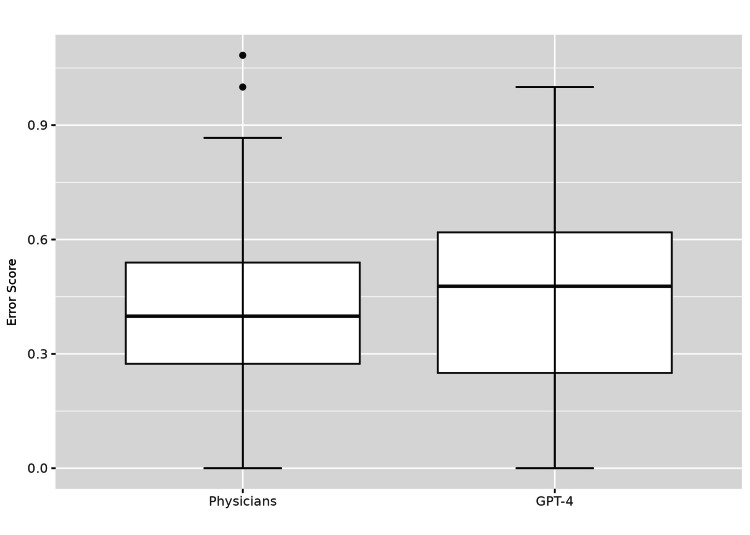
Background The integration of large language models (LLMs) such as GPT-4 into healthcare presents potential benefits and challenges. While LLMs show promise in applications ranging from scientific writing to personalized medicine, their practical utility and safety in clinical settings remain under scrutiny. Concerns about accuracy, ethical considerations, and bias necessitate rigorous evaluation of these technologies against established medical standards. Methods This study involved a comparative analysis using anonymized patient records from a healthcare setting in the state of West Bengal, India. Management plans for 50 patients with type 2 diabetes mellitus were generated by GPT-4 and three physicians, who were blinded to each other's responses. These plans were evaluated against a reference management plan based on American Diabetes Society guidelines. Completeness, necessity, and dosage accuracy were quantified and a Prescribing Error Score was devised to assess the quality of the generated management plans. The safety of the management plans generated by GPT-4 was also assessed. Results Results indicated that physicians' management plans had fewer missing medications compared to those generated by GPT-4 (p=0.008). However, GPT-4-generated management plans included fewer unnecessary medications (p=0.003). No significant difference was observed in the accuracy of drug dosages (p=0.975). The overall error scores were comparable between physicians and GPT-4 (p=0.301). Safety issues were noted in 16% of the plans generated by GPT-4, highlighting potential risks associated with AI-generated management plans. Conclusion The study demonstrates that while GPT-4 can effectively reduce unnecessary drug prescriptions, it does not yet match the performance of physicians in terms of plan completeness. The findings support the use of LLMs as supplementary tools in healthcare, highlighting the need for enhanced algorithms and continuous human oversight to ensure the efficacy and safety of artificial intelligence in clinical settings.
背景 将GPT-4等大语言模型(LLMs)整合到医疗保健领域既带来了潜在益处,也带来了挑战。虽然大语言模型在从科学写作到个性化医疗等一系列应用中展现出了前景,但其在临床环境中的实际效用和安全性仍在接受审查。对准确性、伦理考量和偏差的担忧使得必须根据既定的医学标准对这些技术进行严格评估。方法 本研究采用来自印度西孟加拉邦一家医疗机构的匿名患者记录进行比较分析。GPT-4和三位医生分别生成了50例2型糖尿病患者的管理计划,他们彼此不知道对方的回复。这些计划根据美国糖尿病协会指南与一份参考管理计划进行评估。对完整性、必要性和剂量准确性进行了量化,并设计了一个处方错误评分来评估生成的管理计划的质量。还评估了GPT-4生成的管理计划的安全性。结果 结果表明,与GPT-4生成的管理计划相比,医生的管理计划中遗漏的药物较少(p = 0.008)。然而,GPT-4生成的管理计划中不必要的药物较少(p = 0.003)。在药物剂量准确性方面未观察到显著差异(p = 0.975)。医生和GPT-4的总体错误评分相当(p = 0.301)。在GPT-4生成的计划中有16%被指出存在安全问题,凸显了与人工智能生成的管理计划相关的潜在风险。结论 该研究表明,虽然GPT-4可以有效减少不必要的药物处方,但在计划完整性方面尚未达到医生的表现。这些发现支持将大语言模型用作医疗保健中的辅助工具,强调需要改进算法并持续进行人工监督,以确保人工智能在临床环境中的有效性和安全性。