Leung Yuk Yee, Lee Wan-Ping, Kuzma Amanda B, Nicaretta Heather, Valladares Otto, Gangadharan Prabhakaran, Qu Liming, Zhao Yi, Ren Youli, Cheng Po-Liang, Kuksa Pavel P, Wang Hui, White Heather, Katanic Zivadin, Bass Lauren, Saravanan Naveen, Greenfest-Allen Emily, Kirsch Maureen, Cantwell Laura, Iqbal Taha, Wheeler Nicholas R, Farrell John J, Zhu Congcong, Turner Shannon L, Gunasekaran Tamil I, Mena Pedro R, Jin Yumi, Carter Luke, Zhang Xiaoling, Vardarajan Badri N, Toga Arthur, Cuccaro Michael, Hohman Timothy J, Bush William S, Naj Adam C, Martin Eden, Dalgard Clifton L, Kunkle Brian W, Farrer Lindsay A, Mayeux Richard P, Haines Jonathan L, Pericak-Vance Margaret A, Schellenberg Gerard D, Wang Li-San
Department of Pathology and Laboratory Medicine, Perelman School of Medicine, University of Pennsylvania, Philadelphia, Pennsylvania, USA.
Penn Neurodegeneration Genomics Center, Department of Pathology and Laboratory Medicine, Perelman School of Medicine, University of Pennsylvania, Philadelphia, Pennsylvania, USA.
Alzheimers Dement. 2025 May;21(5):e70237. doi: 10.1002/alz.70237.
The Alzheimer's Disease Sequencing Project (ADSP) is a national initiative to understand the genetic architecture of Alzheimer's disease and related dementias (ADRD) by integrating whole genome sequencing (WGS) with other genetic, phenotypic, and harmonized datasets from diverse populations.
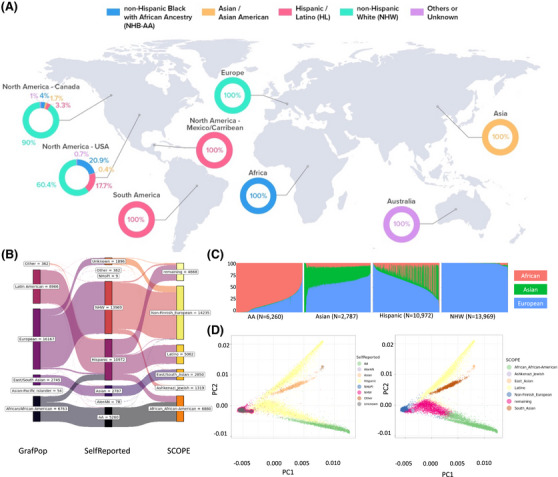
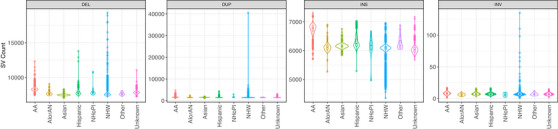
The Genome Center for Alzheimer's Disease (GCAD) uniformly processed WGS from 36,361 ADSP samples, including 35,014 genetically unique participants of which 45% are from non-European ancestry, across 17 cohorts in 14 countries in this fourth release (R4).
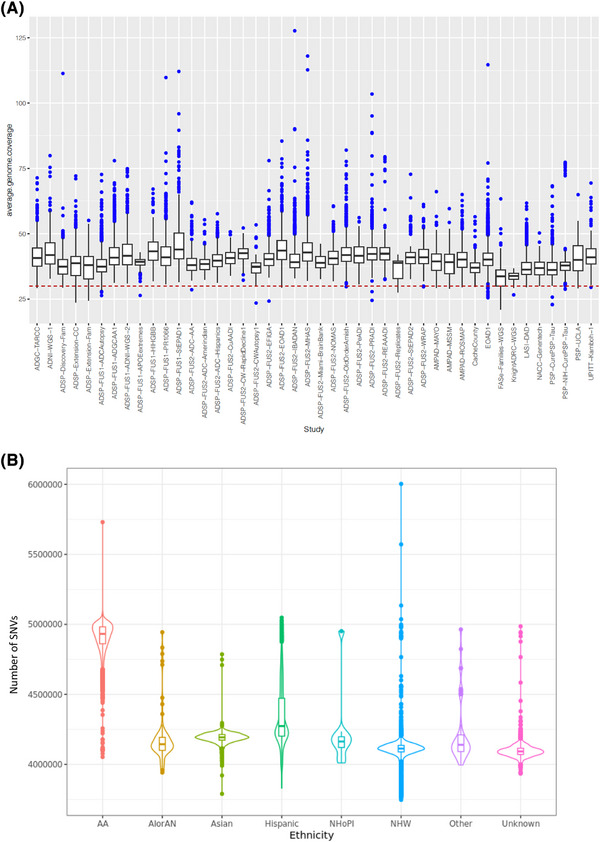
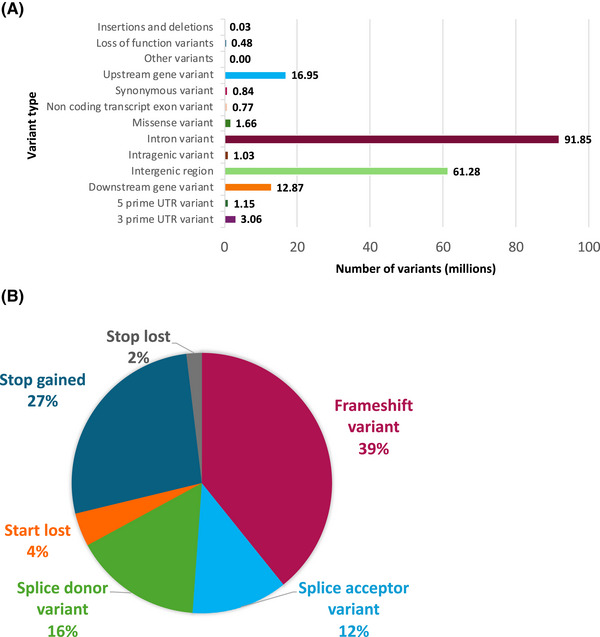
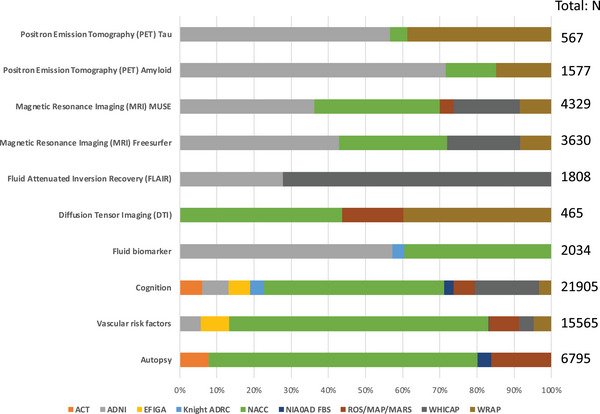
This sequencing effort identified 387 million bi-allelic variants, 42 million short insertions/deletions, and 6.8 million structural variants. Annotations and quality control data are available for all variants and samples. Additionally, detailed phenotypes from 15,927 participants across 10 domains are also provided. A linkage disequilibrium panel was created using unrelated AD cases and controls.
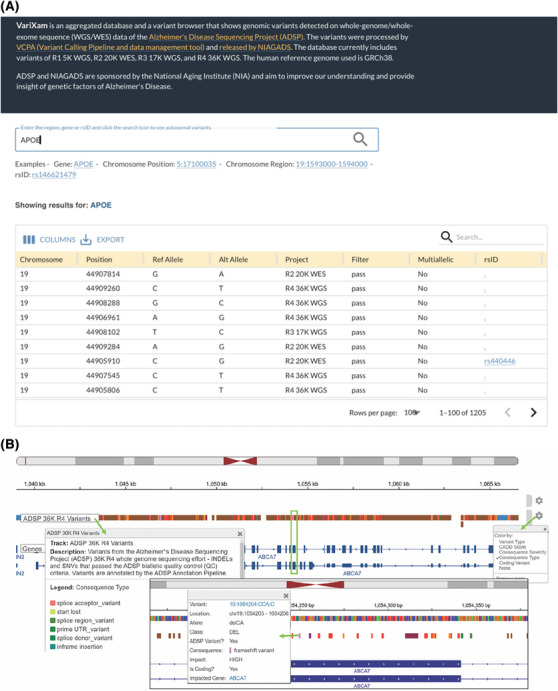
Researchers can access and analyze the genetic data via the National Institute on Aging Genetics of Alzheimer's Disease Data Storage Site (NIAGADS) Data Sharing Service, the VariXam, or NIAGADS GenomicsDB.
We detailed the genetic architecture and quality of the Alzheimer's Disease Sequencing Project release 4 whole genome sequences. We identified 435 million single nucleotide polymorphisms, insertions and deletions, and structural variants from diverse genomes. We harmonized extensive phenotypes, linkage disequilibrium reference panel on subset of samples. Data is publicly available at NIAGADS Data Storage Site, variants and annotations are browsable on two different websites.
阿尔茨海默病测序项目(ADSP)是一项全国性计划,旨在通过整合全基因组测序(WGS)与来自不同人群的其他遗传、表型和协调数据集,来了解阿尔茨海默病及相关痴呆症(ADRD)的遗传结构。
阿尔茨海默病基因组中心(GCAD)对来自36361个ADSP样本的WGS进行了统一处理,其中包括35014名具有遗传独特性的参与者,其中45%来自非欧洲血统,涵盖了14个国家的17个队列,这是第四次发布(R4)。
此次测序工作共识别出3.87亿个双等位基因变异、4200万个短插入/缺失和680万个结构变异。所有变异和样本都有注释和质量控制数据。此外,还提供了来自10个领域的15927名参与者的详细表型。利用不相关的AD病例和对照创建了一个连锁不平衡面板。
研究人员可以通过美国国立衰老研究所阿尔茨海默病遗传学数据存储站点(NIAGADS)数据共享服务、VariXam或NIAGADS GenomicsDB访问和分析遗传数据。
我们详细介绍了阿尔茨海默病测序项目第4版全基因组序列的遗传结构和质量。我们从不同基因组中识别出4.35亿个单核苷酸多态性、插入和缺失以及结构变异。我们对广泛的表型、样本子集上的连锁不平衡参考面板进行了协调。数据可在NIAGADS数据存储站点公开获取,变异和注释可在两个不同网站上浏览。