Rust Paul, Frings Julian, Meister Sven, Fehring Leonard
Faculty of Health, School of Medicine, Witten/Herdecke University, Alfred-Herrhausen-Strasse 50, 58455, Witten, Germany.
Health Care Informatics, Faculty of Health, School of Medicine, Witten/Herdecke University, Pferdebachstrasse 11, 58455, Witten, Germany.
Commun Med (Lond). 2025 May 29;5(1):208. doi: 10.1038/s43856-025-00927-2.
Hospital discharge summaries are essential for the continuity of care. However, medical jargon, abbreviations, and technical language often make them too complex for patients to understand, and they frequently omit lifestyle recommendations important for self-management. This study explored using a large language model (LLM) to enhance discharge summary readability and augment it with lifestyle recommendations.
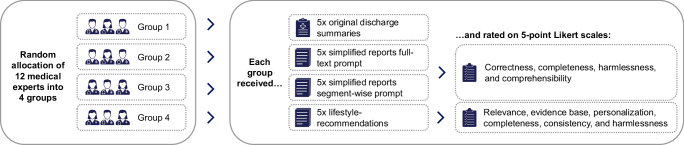
We collected 20 anonymized cardiology discharge summaries. GPT-4o was prompted using full-text and segment-wise approaches to simplify each summary and generate lifestyle recommendations. Readability was measured via three standardized metrics (modified Flesch-Reading-Ease, Vienna Non-fiction Text Formula, Lesbarkeitsindex), and multiple quality dimensions were evaluated by 12 medical experts.
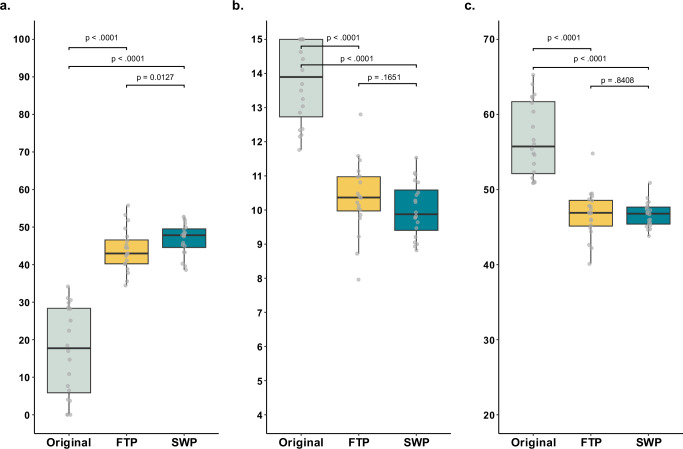
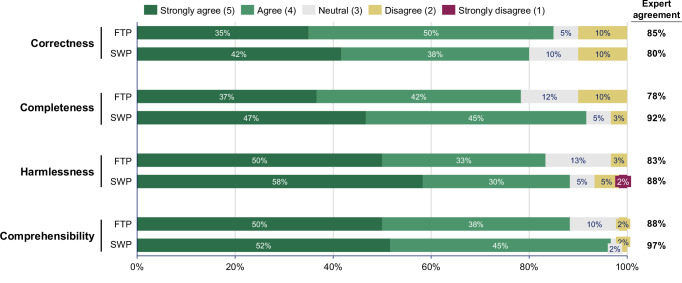
LLM-generated summaries from both prompting approaches are significantly more readable compared to the original summaries across all metrics (p < 0.0001). Based on 60 expert ratings for the full-text approach and 60 for the segment-wise approach, experts '(strongly) agree' that LLM-summaries are correct (full-text: 85%; segment-wise: 80%), complete (78%; 92%), harmless (83%; 88%), and comprehensible for patients (88%; 97%). Experts '(strongly) agree' that LLM-generated recommendations are relevant in 92%, evidence-based in 88%, personalized in 70%, complete in 88%, consistent in 93%, and harmless in 88% of 60 ratings.
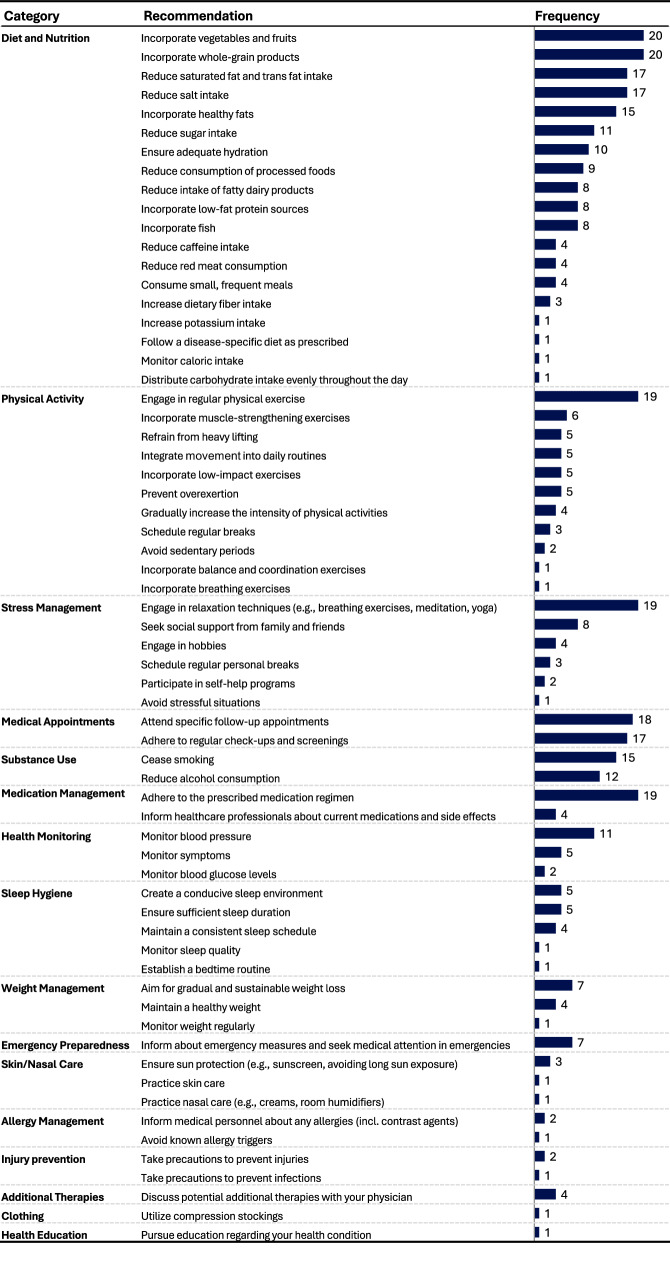
LLM-generated summaries achieve a 10th-grade readability level and high-quality ratings. While LLM-generated lifestyle recommendations are generally of high quality, personalization is limited. These findings suggest that LLMs could help create more patient-centric discharge summaries. Further research is needed to confirm clinical utility and address quality assurance, regulatory compliance, and clinical integration challenges.
出院小结对于医疗护理的连续性至关重要。然而,医学术语、缩写和专业语言常常使其过于复杂,患者难以理解,而且它们经常遗漏对自我管理很重要的生活方式建议。本研究探讨了使用大语言模型(LLM)来提高出院小结的可读性,并补充生活方式建议。
我们收集了20份匿名的心脏病学出院小结。使用全文和逐段方法提示GPT-4o,以简化每份小结并生成生活方式建议。通过三个标准化指标(修改后的弗莱什易读性、维也纳非虚构文本公式、易读性指数)测量可读性,并由12名医学专家评估多个质量维度。
与原始小结相比,两种提示方法生成的LLM小结在所有指标上的可读性均显著提高(p < 0.0001)。基于对全文方法的60次专家评分和对逐段方法的60次专家评分,专家们“(强烈)同意”LLM小结是正确的(全文:85%;逐段:80%)、完整的(78%;92%)、无害的(83%;88%),并且对患者来说是可理解的(88%;97%)。在60次评分中,专家们“(强烈)同意”LLM生成的建议在92%的情况下是相关的、在88%的情况下是基于证据的、在70%的情况下是个性化的、在88%的情况下是完整的、在93%的情况下是一致的、在88%的情况下是无害的。
LLM生成的小结达到了十年级的可读性水平和高质量评分。虽然LLM生成的生活方式建议总体质量较高,但个性化程度有限。这些发现表明,LLMs可以帮助创建更以患者为中心的出院小结。需要进一步研究来确认临床效用,并应对质量保证、法规遵从性和临床整合方面的挑战。