Schweighofer N, Shishida K, Han C E, Okamoto Y, Tanaka S C, Yamawaki S, Doya K
Biokinesiology and Physical Therapy, University of Southern California, Los Angeles, United States of America.
PLoS Comput Biol. 2006 Nov 10;2(11):e152. doi: 10.1371/journal.pcbi.0020152. Epub 2006 Oct 4.
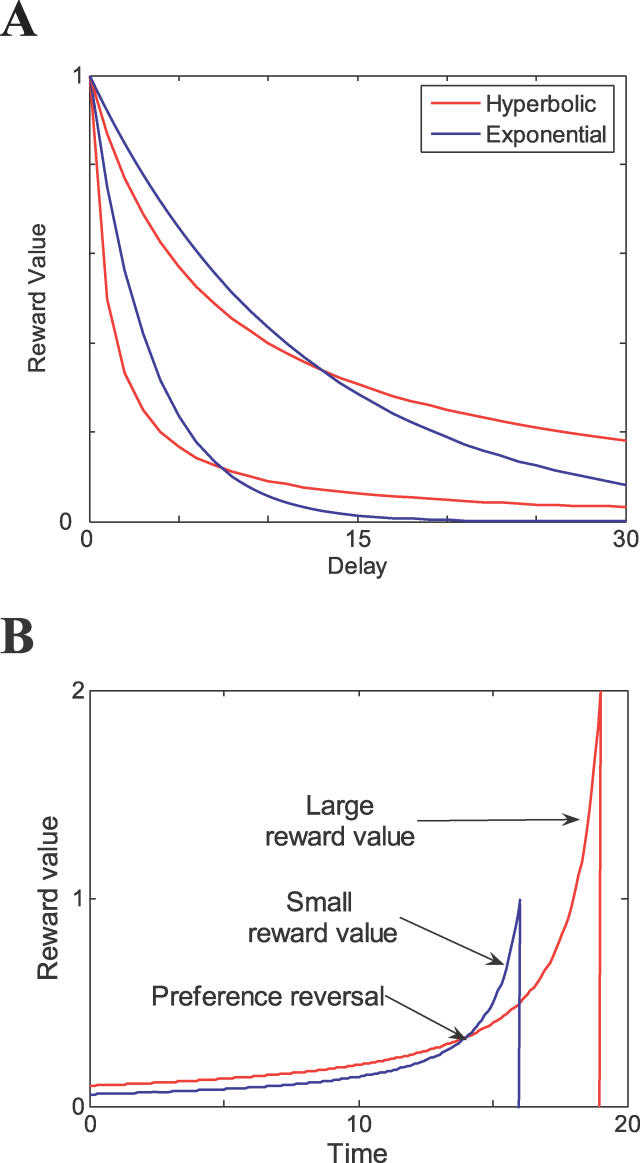
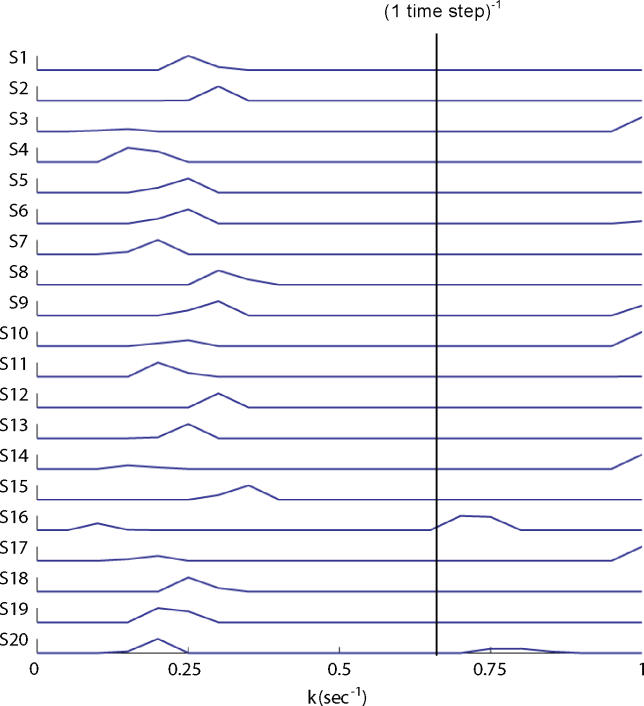
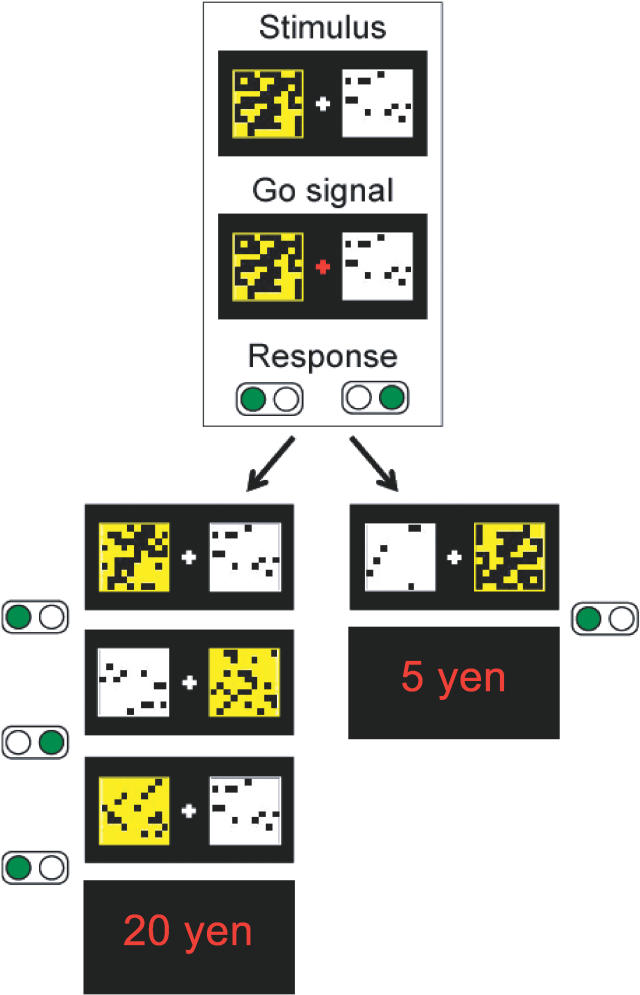
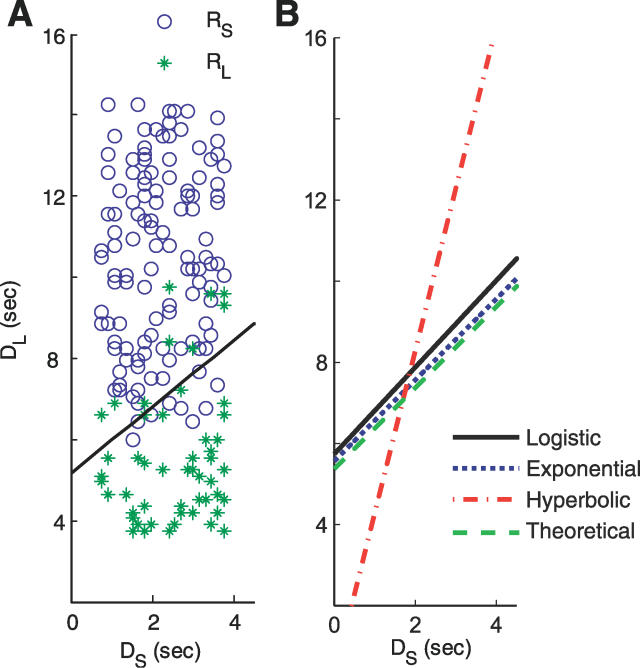
Critical to our many daily choices between larger delayed rewards, and smaller more immediate rewards, are the shape and the steepness of the function that discounts rewards with time. Although research in artificial intelligence favors exponential discounting in uncertain environments, studies with humans and animals have consistently shown hyperbolic discounting. We investigated how humans perform in a reward decision task with temporal constraints, in which each choice affects the time remaining for later trials, and in which the delays vary at each trial. We demonstrated that most of our subjects adopted exponential discounting in this experiment. Further, we confirmed analytically that exponential discounting, with a decay rate comparable to that used by our subjects, maximized the total reward gain in our task. Our results suggest that the particular shape and steepness of temporal discounting is determined by the task that the subject is facing, and question the notion of hyperbolic reward discounting as a universal principle.
在我们每天面临的众多选择中,即在较大的延迟奖励和较小的即时奖励之间做出抉择时,随着时间推移对奖励进行折扣的函数的形状和陡峭程度至关重要。尽管人工智能领域的研究在不确定环境中倾向于指数折扣,但对人类和动物的研究一直表明是双曲线折扣。我们研究了人类在有时间限制的奖励决策任务中的表现,在该任务中,每次选择都会影响后续试验剩余的时间,并且每次试验的延迟都不同。我们证明,在这个实验中,我们的大多数受试者采用了指数折扣。此外,我们通过分析证实,具有与我们的受试者所使用的衰减率相当的指数折扣,在我们的任务中使总奖励收益最大化。我们的结果表明,时间折扣的特定形状和陡峭程度由受试者所面临的任务决定,并对双曲线奖励折扣作为普遍原则的观点提出了质疑。