Parker Brian J, Günter Simon, Bedo Justin
Statistical Machine Learning Group, NICTA, Canberra, Australia.
BMC Bioinformatics. 2007 Sep 2;8:326. doi: 10.1186/1471-2105-8-326.
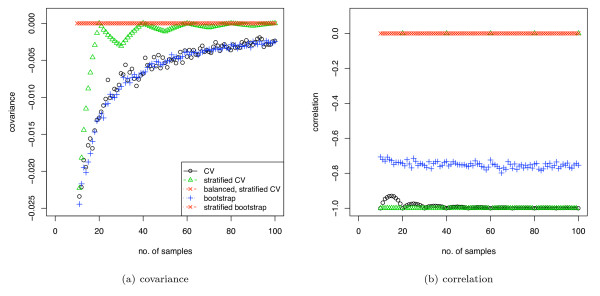
When analysing microarray and other small sample size biological datasets, care is needed to avoid various biases. We analyse a form of bias, stratification bias, that can substantially affect analyses using sample-reuse validation techniques and lead to inaccurate results. This bias is due to imperfect stratification of samples in the training and test sets and the dependency between these stratification errors, i.e. the variations in class proportions in the training and test sets are negatively correlated.
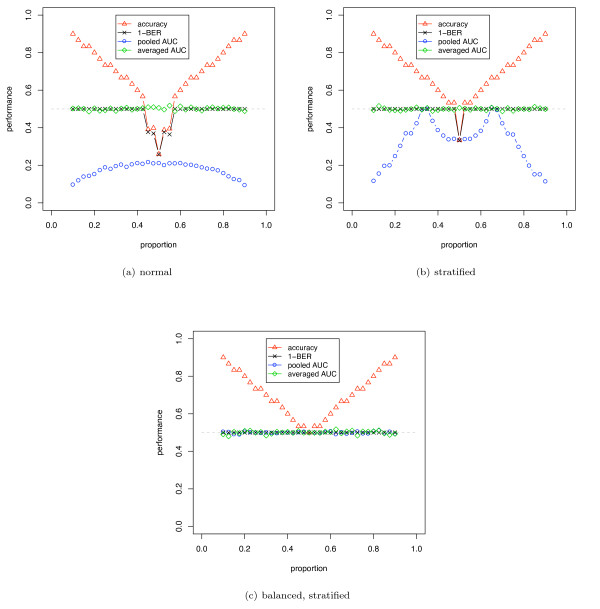
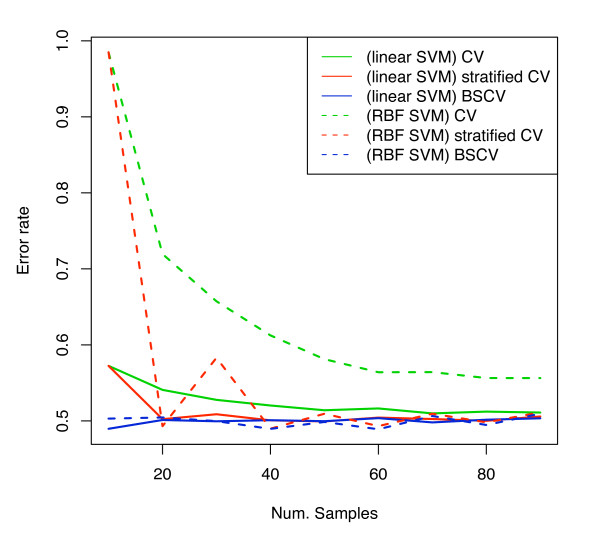
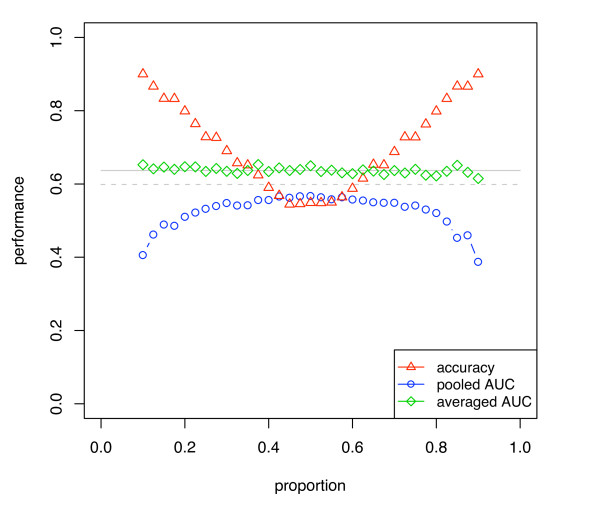
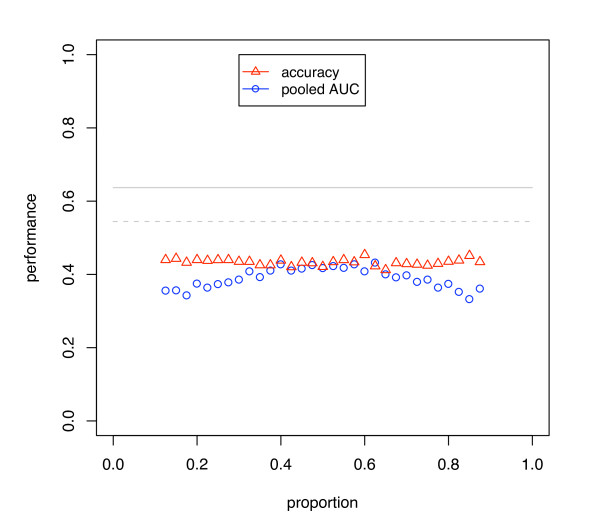
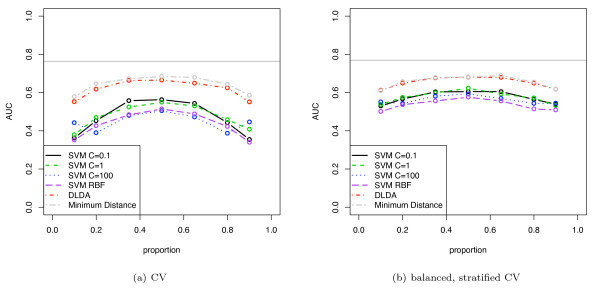
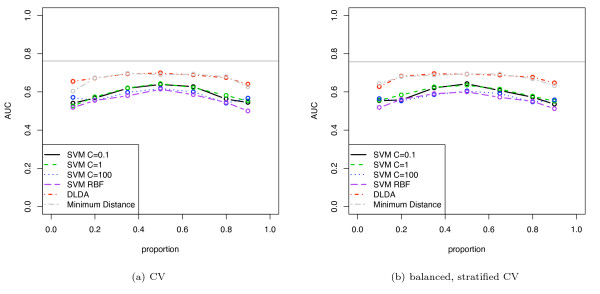
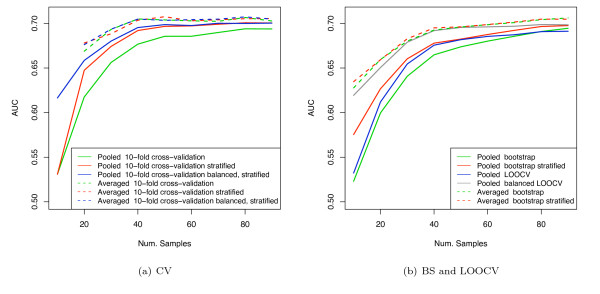
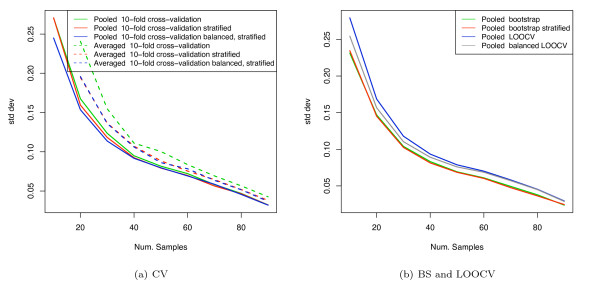
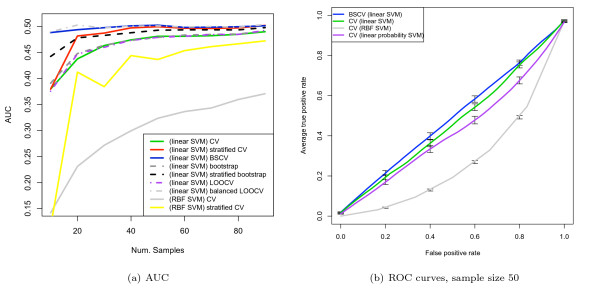
We show that when estimating the performance of classifiers on low signal datasets (i.e. those which are difficult to classify), which are typical of many prognostic microarray studies, commonly used performance measures can suffer from a substantial negative bias. For error rate this bias is only severe in quite restricted situations, but can be much larger and more frequent when using ranking measures such as the receiver operating characteristic (ROC) curve and area under the ROC (AUC). Substantial biases are shown in simulations and on the van 't Veer breast cancer dataset. The classification error rate can have large negative biases for balanced datasets, whereas the AUC shows substantial pessimistic biases even for imbalanced datasets. In simulation studies using 10-fold cross-validation, AUC values of less than 0.3 can be observed on random datasets rather than the expected 0.5. Further experiments on the van 't Veer breast cancer dataset show these biases exist in practice.
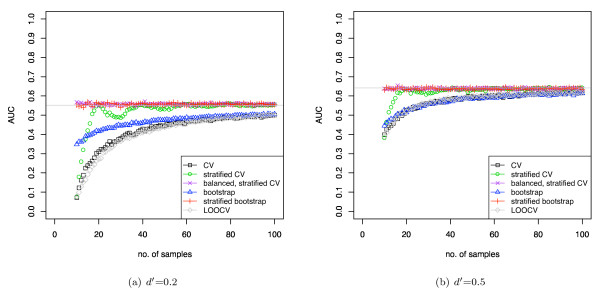
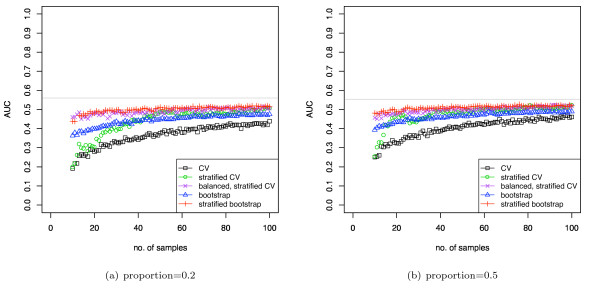
Stratification bias can substantially affect several performance measures. In computing the AUC, the strategy of pooling the test samples from the various folds of cross-validation can lead to large biases; computing it as the average of per-fold estimates avoids this bias and is thus the recommended approach. As a more general solution applicable to other performance measures, we show that stratified repeated holdout and a modified version of k-fold cross-validation, balanced, stratified cross-validation and balanced leave-one-out cross-validation, avoids the bias. Therefore for model selection and evaluation of microarray and other small biological datasets, these methods should be used and unstratified versions avoided. In particular, the commonly used (unbalanced) leave-one-out cross-validation should not be used to estimate AUC for small datasets.
在分析微阵列及其他小样本量生物数据集时,需要注意避免各种偏差。我们分析了一种偏差形式,即分层偏差,它会严重影响使用样本重复验证技术的分析,并导致结果不准确。这种偏差是由于训练集和测试集中样本的分层不完善以及这些分层误差之间的相关性所致,即训练集和测试集中类别比例的变化呈负相关。
我们表明,在估计分类器在低信号数据集(即难以分类的数据集)上的性能时,这在许多预后微阵列研究中很常见,常用的性能指标可能会遭受严重的负偏差。对于错误率,这种偏差仅在相当有限的情况下很严重,但在使用诸如接收者操作特征(ROC)曲线和ROC曲线下面积(AUC)等排序指标时,偏差可能更大且更频繁。在模拟和范特维尔乳腺癌数据集上均显示出严重的偏差。对于平衡数据集,分类错误率可能存在较大的负偏差,而即使对于不平衡数据集,AUC也显示出严重的悲观偏差。在使用10折交叉验证的模拟研究中,在随机数据集上可以观察到AUC值小于0.3,而不是预期的0.5。在范特维尔乳腺癌数据集上的进一步实验表明,这些偏差在实际中确实存在。
分层偏差会严重影响多种性能指标。在计算AUC时,将交叉验证各折中的测试样本合并的策略可能会导致较大偏差;将其计算为每折估计值的平均值可避免这种偏差,因此是推荐的方法。作为适用于其他性能指标的更通用解决方案,我们表明分层重复留出法以及k折交叉验证的修改版本,即平衡分层交叉验证和平衡留一法交叉验证,可避免偏差。因此,对于微阵列和其他小生物数据集的模型选择和评估,应使用这些方法并避免使用未分层的版本。特别是,常用的(不平衡的)留一法交叉验证不应用于估计小数据集的AUC。