Zhang Yi, Ding Chris, Li Tao
School of Computer Science, Florida International University, 11200 SW 8th Street, Miami, FL 33199, USA.
BMC Genomics. 2008 Sep 16;9 Suppl 2(Suppl 2):S27. doi: 10.1186/1471-2164-9-S2-S27.
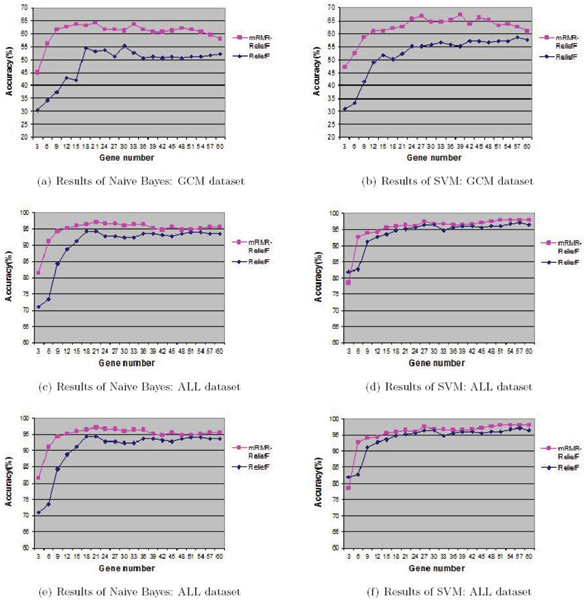
Gene expression data usually contains a large number of genes, but a small number of samples. Feature selection for gene expression data aims at finding a set of genes that best discriminate biological samples of different types. In this paper, we present a two-stage selection algorithm by combining ReliefF and mRMR: In the first stage, ReliefF is applied to find a candidate gene set; In the second stage, mRMR method is applied to directly and explicitly reduce redundancy for selecting a compact yet effective gene subset from the candidate set.
We perform comprehensive experiments to compare the mRMR-ReliefF selection algorithm with ReliefF, mRMR and other feature selection methods using two classifiers as SVM and Naive Bayes, on seven different datasets. And we also provide all source codes and datasets for sharing with others.
The experimental results show that the mRMR-ReliefF gene selection algorithm is very effective.
基因表达数据通常包含大量基因,但样本数量较少。基因表达数据的特征选择旨在找到一组能最佳区分不同类型生物样本的基因。在本文中,我们提出了一种结合ReliefF和mRMR的两阶段选择算法:在第一阶段,应用ReliefF找到候选基因集;在第二阶段,应用mRMR方法直接且明确地减少冗余,以便从候选集中选择一个紧凑而有效的基因子集。
我们进行了全面的实验,使用支持向量机(SVM)和朴素贝叶斯这两种分类器,在七个不同数据集上,将mRMR-ReliefF选择算法与ReliefF、mRMR及其他特征选择方法进行比较。并且我们还提供所有源代码和数据集以供他人共享。
实验结果表明,mRMR-ReliefF基因选择算法非常有效。