Lee Sang Hong, van der Werf Julius H J, Hayes Ben J, Goddard Michael E, Visscher Peter M
School of Environmental and Rural Science, University of New England, Armidale, NSW, Australia.
PLoS Genet. 2008 Oct;4(10):e1000231. doi: 10.1371/journal.pgen.1000231. Epub 2008 Oct 24.
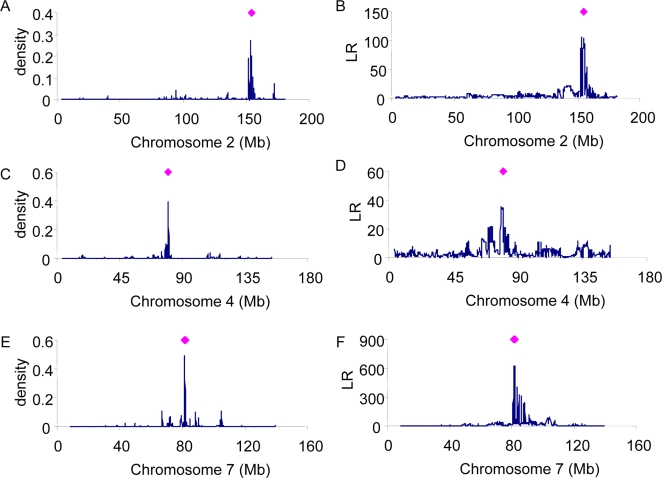
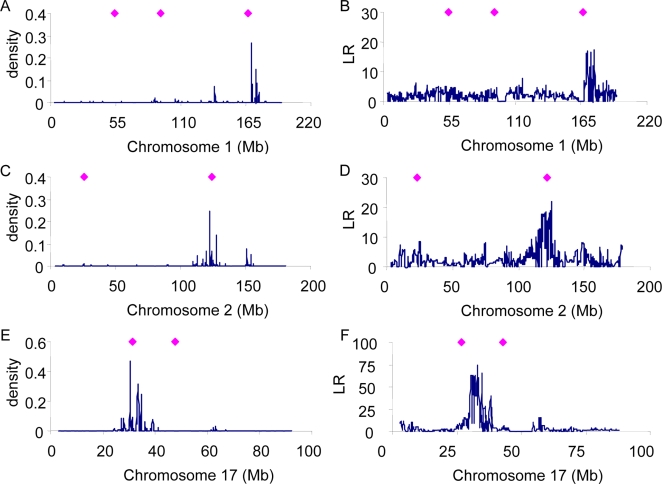
Genome-wide association studies (GWAS) for quantitative traits and disease in humans and other species have shown that there are many loci that contribute to the observed resemblance between relatives. GWAS to date have mostly focussed on discovery of genes or regulatory regions habouring causative polymorphisms, using single SNP analyses and setting stringent type-I error rates. Genome-wide marker data can also be used to predict genetic values and therefore predict phenotypes. Here, we propose a Bayesian method that utilises all marker data simultaneously to predict phenotypes. We apply the method to three traits: coat colour, %CD8 cells, and mean cell haemoglobin, measured in a heterogeneous stock mouse population. We find that a model that contains both additive and dominance effects, estimated from genome-wide marker data, is successful in predicting unobserved phenotypes and is significantly better than a prediction based upon the phenotypes of close relatives. Correlations between predicted and actual phenotypes were in the range of 0.4 to 0.9 when half of the number of families was used to estimate effects and the other half for prediction. Posterior probabilities of SNPs being associated with coat colour were high for regions that are known to contain loci for this trait. The prediction of phenotypes using large samples, high-density SNP data, and appropriate statistical methodology is feasible and can be applied in human medicine, forensics, or artificial selection programs.
针对人类和其他物种的数量性状及疾病开展的全基因组关联研究(GWAS)表明,存在许多位点对亲属间观察到的相似性有贡献。迄今为止,GWAS大多聚焦于利用单核苷酸多态性(SNP)分析以及设定严格的I型错误率来发现含有致病多态性的基因或调控区域。全基因组标记数据也可用于预测遗传值,进而预测表型。在此,我们提出一种贝叶斯方法,该方法同时利用所有标记数据来预测表型。我们将该方法应用于在一个遗传异质小鼠群体中测量的三个性状:毛色、CD8细胞百分比和平均细胞血红蛋白含量。我们发现,一个包含从全基因组标记数据估计出的加性效应和显性效应的模型,能够成功预测未观察到的表型,并且显著优于基于近亲表型的预测。当用一半的家系数量来估计效应,另一半用于预测时,预测表型与实际表型之间的相关性在0.4到0.9之间。对于已知包含该性状位点的区域,SNP与毛色相关的后验概率很高。利用大样本、高密度SNP数据以及适当的统计方法来预测表型是可行的,并且可应用于人类医学、法医学或人工选择计划。