Cochrane Guy, Akhtar Ruth, Bonfield James, Bower Lawrence, Demiralp Fehmi, Faruque Nadeem, Gibson Richard, Hoad Gemma, Hubbard Tim, Hunter Christopher, Jang Mikyung, Juhos Szilveszter, Leinonen Rasko, Leonard Steven, Lin Quan, Lopez Rodrigo, Lorenc Dariusz, McWilliam Hamish, Mukherjee Gaurab, Plaister Sheila, Radhakrishnan Rajesh, Robinson Stephen, Sobhany Siamak, Hoopen Petra Ten, Vaughan Robert, Zalunin Vadim, Birney Ewan
EMBL-European Bioinformatics Institute, Wellcome Trust Genome Campus, Hinxton, Cambridge CB10 1SD, UK.
Nucleic Acids Res. 2009 Jan;37(Database issue):D19-25. doi: 10.1093/nar/gkn765. Epub 2008 Oct 31.
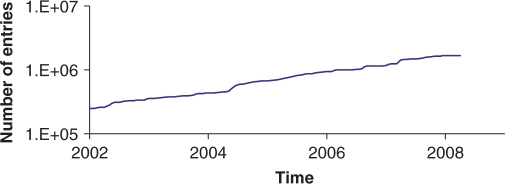
Dramatic increases in the throughput of nucleotide sequencing machines, and the promise of ever greater performance, have thrust bioinformatics into the era of petabyte-scale data sets. Sequence repositories, which provide the feed for these data sets into the worldwide computational infrastructure, are challenged by the impact of these data volumes. The European Nucleotide Archive (ENA; http://www.ebi.ac.uk/embl), comprising the EMBL Nucleotide Sequence Database and the Ensembl Trace Archive, has identified challenges in the storage, movement, analysis, interpretation and visualization of petabyte-scale data sets. We present here our new repository for next generation sequence data, a brief summary of contents of the ENA and provide details of major developments to submission pipelines, high-throughput rule-based validation infrastructure and data integration approaches.
核苷酸测序仪通量的急剧增加以及性能不断提升的前景,已将生物信息学推进到了千万亿字节规模数据集的时代。为全球计算基础设施提供这些数据集数据来源的序列数据库,正受到这些数据量的影响而面临挑战。由欧洲分子生物学实验室核苷酸序列数据库(EMBL Nucleotide Sequence Database)和Ensembl序列追踪数据库(Ensembl Trace Archive)组成的欧洲核苷酸档案库(ENA;http://www.ebi.ac.uk/embl),已明确了在千万亿字节规模数据集的存储、传输、分析、解读及可视化方面所面临的挑战。我们在此展示我们新的下一代序列数据存档库,简要概述ENA的内容,并详细介绍提交管道、基于规则的高通量验证基础设施及数据整合方法的主要进展。