Wilson J Adam, Williams Justin C
Department of Biomedical Engineering, University of Wisconsin-Madison Madison, WI, USA.
Front Neuroeng. 2009 Jul 14;2:11. doi: 10.3389/neuro.16.011.2009. eCollection 2009.
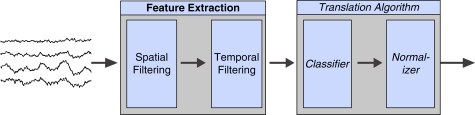
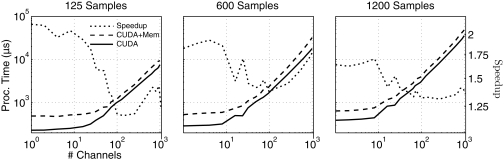
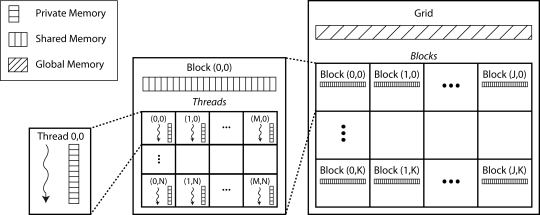
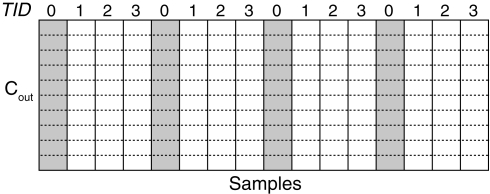
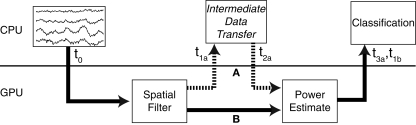
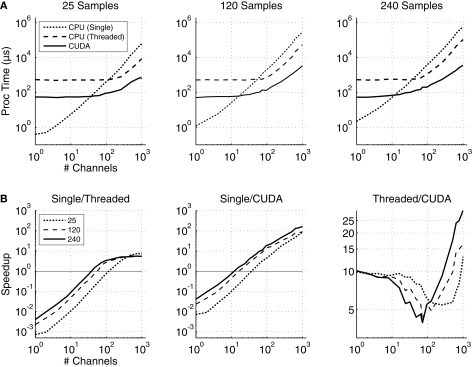
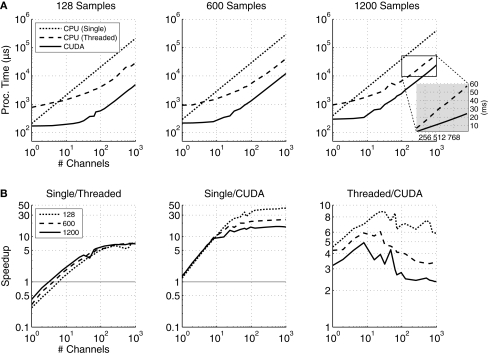
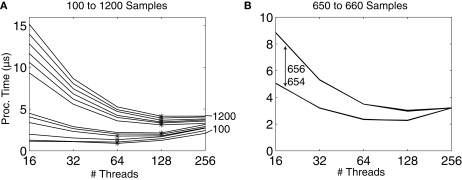
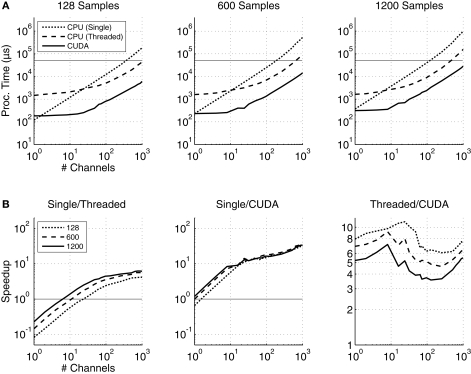
The clock speeds of modern computer processors have nearly plateaued in the past 5 years. Consequently, neural prosthetic systems that rely on processing large quantities of data in a short period of time face a bottleneck, in that it may not be possible to process all of the data recorded from an electrode array with high channel counts and bandwidth, such as electrocorticographic grids or other implantable systems. Therefore, in this study a method of using the processing capabilities of a graphics card [graphics processing unit (GPU)] was developed for real-time neural signal processing of a brain-computer interface (BCI). The NVIDIA CUDA system was used to offload processing to the GPU, which is capable of running many operations in parallel, potentially greatly increasing the speed of existing algorithms. The BCI system records many channels of data, which are processed and translated into a control signal, such as the movement of a computer cursor. This signal processing chain involves computing a matrix-matrix multiplication (i.e., a spatial filter), followed by calculating the power spectral density on every channel using an auto-regressive method, and finally classifying appropriate features for control. In this study, the first two computationally intensive steps were implemented on the GPU, and the speed was compared to both the current implementation and a central processing unit-based implementation that uses multi-threading. Significant performance gains were obtained with GPU processing: the current implementation processed 1000 channels of 250 ms in 933 ms, while the new GPU method took only 27 ms, an improvement of nearly 35 times.
在过去五年中,现代计算机处理器的时钟速度几乎已趋于平稳。因此,依赖于在短时间内处理大量数据的神经假体系统面临着一个瓶颈,即可能无法处理从具有高通道数和带宽的电极阵列(如脑皮层电图网格或其他可植入系统)记录的所有数据。因此,在本研究中,开发了一种利用图形卡[图形处理单元(GPU)]处理能力的方法,用于脑机接口(BCI)的实时神经信号处理。NVIDIA CUDA系统被用于将处理任务卸载到GPU上,该GPU能够并行运行许多操作,有可能极大地提高现有算法的速度。BCI系统记录多个通道的数据,这些数据经过处理后被转换为控制信号,例如计算机光标的移动。这个信号处理链包括计算矩阵-矩阵乘法(即空间滤波器),然后使用自回归方法计算每个通道上的功率谱密度,最后对用于控制的适当特征进行分类。在本研究中,前两个计算密集型步骤在GPU上实现,并将速度与当前实现方式以及使用多线程的基于中央处理器的实现方式进行了比较。使用GPU处理获得了显著的性能提升:当前实现方式处理1000个通道、250毫秒的数据需要933毫秒,而新的GPU方法仅需27毫秒,提高了近35倍。