Barnickel Thorsten, Weston Jason, Collobert Ronan, Mewes Hans-Werner, Stümpflen Volker
Helmholtz Zentrum München, Institute of Bioinformatics and Systems Biology (MIPS), Neuherberg, Germany.
PLoS One. 2009 Jul 28;4(7):e6393. doi: 10.1371/journal.pone.0006393.
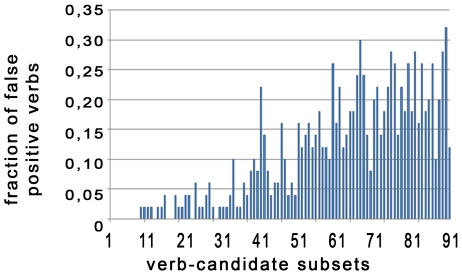
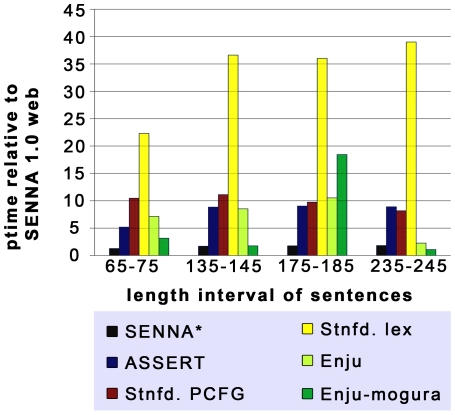
To reduce the increasing amount of time spent on literature search in the life sciences, several methods for automated knowledge extraction have been developed. Co-occurrence based approaches can deal with large text corpora like MEDLINE in an acceptable time but are not able to extract any specific type of semantic relation. Semantic relation extraction methods based on syntax trees, on the other hand, are computationally expensive and the interpretation of the generated trees is difficult. Several natural language processing (NLP) approaches for the biomedical domain exist focusing specifically on the detection of a limited set of relation types. For systems biology, generic approaches for the detection of a multitude of relation types which in addition are able to process large text corpora are needed but the number of systems meeting both requirements is very limited. We introduce the use of SENNA ("Semantic Extraction using a Neural Network Architecture"), a fast and accurate neural network based Semantic Role Labeling (SRL) program, for the large scale extraction of semantic relations from the biomedical literature. A comparison of processing times of SENNA and other SRL systems or syntactical parsers used in the biomedical domain revealed that SENNA is the fastest Proposition Bank (PropBank) conforming SRL program currently available. 89 million biomedical sentences were tagged with SENNA on a 100 node cluster within three days. The accuracy of the presented relation extraction approach was evaluated on two test sets of annotated sentences resulting in precision/recall values of 0.71/0.43. We show that the accuracy as well as processing speed of the proposed semantic relation extraction approach is sufficient for its large scale application on biomedical text. The proposed approach is highly generalizable regarding the supported relation types and appears to be especially suited for general-purpose, broad-scale text mining systems. The presented approach bridges the gap between fast, co-occurrence-based approaches lacking semantic relations and highly specialized and computationally demanding NLP approaches.
为减少生命科学领域文献检索所花费的时间不断增加的问题,已开发出几种自动知识提取方法。基于共现的方法能够在可接受的时间内处理像MEDLINE这样的大型文本语料库,但无法提取任何特定类型的语义关系。另一方面,基于句法树的语义关系提取方法计算成本高昂,且对生成的树进行解释也很困难。存在几种针对生物医学领域的自然语言处理(NLP)方法,专门侧重于检测有限的一组关系类型。对于系统生物学而言,需要能够检测多种关系类型且还能处理大型文本语料库的通用方法,但同时满足这两个要求的系统数量非常有限。我们引入使用SENNA(“使用神经网络架构进行语义提取”),这是一个基于快速且准确的神经网络的语义角色标注(SRL)程序,用于从生物医学文献中大规模提取语义关系。对SENNA与生物医学领域中使用的其他SRL系统或句法解析器的处理时间进行比较后发现,SENNA是目前可用的最快的符合命题库(PropBank)的SRL程序。在一个100节点的集群上,三天内用SENNA对8900万个生物医学句子进行了标注。在所呈现的关系提取方法的准确性在两个带注释句子的测试集上进行了评估,精确率/召回率值为0.71/0.43。我们表明,所提出的语义关系提取方法的准确性和处理速度足以使其在生物医学文本上进行大规模应用。所提出的方法在支持的关系类型方面具有高度的通用性,并且似乎特别适合通用的、大规模的文本挖掘系统。所呈现的方法弥合了缺乏语义关系的基于快速共现的方法与高度专业化且计算要求高的NLP方法之间的差距。