Institute of Genetics and Biotechnology, Faculty of Agricultural Sciences, Aarhus University, Aarhus, Denmark.
BMC Bioinformatics. 2010 Jan 11;11:18. doi: 10.1186/1471-2105-11-18.
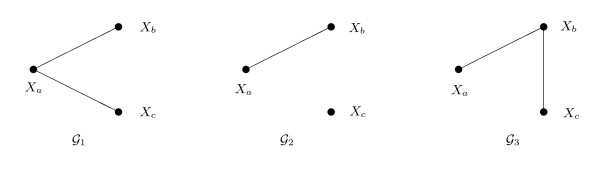
Chow and Liu showed that the maximum likelihood tree for multivariate discrete distributions may be found using a maximum weight spanning tree algorithm, for example Kruskal's algorithm. The efficiency of the algorithm makes it tractable for high-dimensional problems.
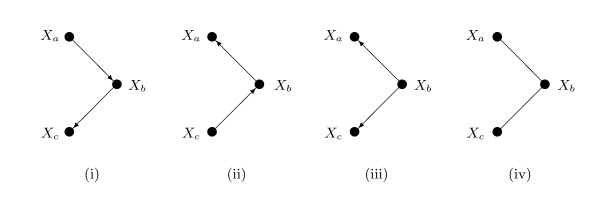
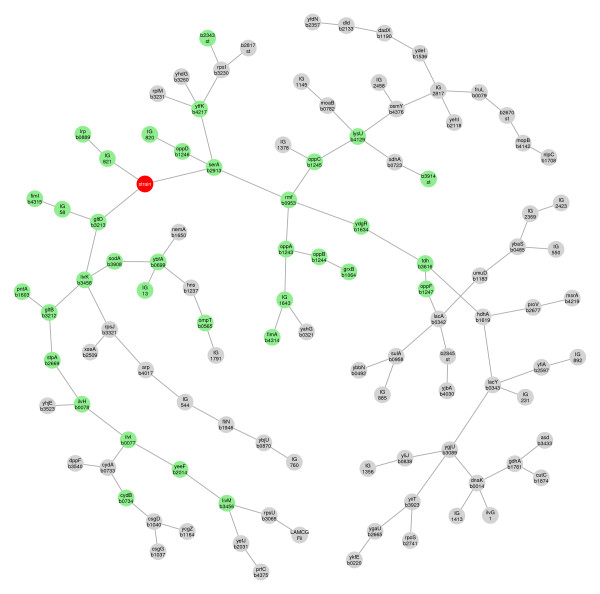
We extend Chow and Liu's approach in two ways: first, to find the forest optimizing a penalized likelihood criterion, for example AIC or BIC, and second, to handle data with both discrete and Gaussian variables. We apply the approach to three datasets: two from gene expression studies and the third from a genetics of gene expression study. The minimal BIC forest supplements a conventional analysis of differential expression by providing a tentative network for the differentially expressed genes. In the genetics of gene expression context the method identifies a network approximating the joint distribution of the DNA markers and the gene expression levels.
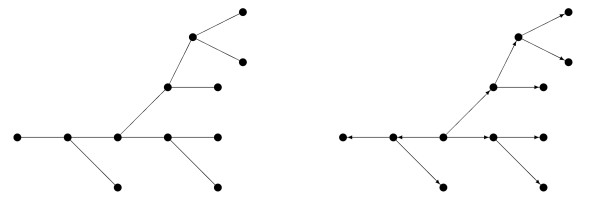
The approach is generally useful as a preliminary step towards understanding the overall dependence structure of high-dimensional discrete and/or continuous data. Trees and forests are unrealistically simple models for biological systems, but can provide useful insights. Uses include the following: identification of distinct connected components, which can be analysed separately (dimension reduction); identification of neighbourhoods for more detailed analyses; as initial models for search algorithms with a larger search space, for example decomposable models or Bayesian networks; and identification of interesting features, such as hub nodes.
Chow 和 Liu 表明,对于多元离散分布,可以使用最大权重生成树算法(例如 Kruskal 算法)找到最大似然树。该算法的效率使其适用于高维问题。
我们以两种方式扩展了 Chow 和 Liu 的方法:首先,找到优化惩罚似然准则(例如 AIC 或 BIC)的森林,其次,处理同时具有离散和高斯变量的数据。我们将该方法应用于三个数据集:两个来自基因表达研究,第三个来自基因表达遗传学研究。最小 BIC 森林通过为差异表达基因提供一个暂定网络,补充了传统的差异表达分析。在基因表达遗传学背景下,该方法识别出一个近似于 DNA 标记和基因表达水平联合分布的网络。
该方法通常可作为理解高维离散和/或连续数据整体依赖结构的初步步骤。树和森林对于生物系统来说是不切实际的简单模型,但可以提供有用的见解。用途包括以下几个方面:识别不同的连接组件,可以分别进行分析(降维);识别更详细分析的邻域;作为更大搜索空间的搜索算法的初始模型,例如可分解模型或贝叶斯网络;以及识别有趣的特征,如枢纽节点。