Key Laboratory of Animal Genetics and Breeding of the Ministry of Agriculture, College of Animal Science and Technology, China Agricultural University, Beijing, China.
PLoS One. 2010 Sep 9;5(9):e12648. doi: 10.1371/journal.pone.0012648.
With the availability of high density whole-genome single nucleotide polymorphism chips, genomic selection has become a promising method to estimate genetic merit with potentially high accuracy for animal, plant and aquaculture species of economic importance. With markers covering the entire genome, genetic merit of genotyped individuals can be predicted directly within the framework of mixed model equations, by using a matrix of relationships among individuals that is derived from the markers. Here we extend that approach by deriving a marker-based relationship matrix specifically for the trait of interest.
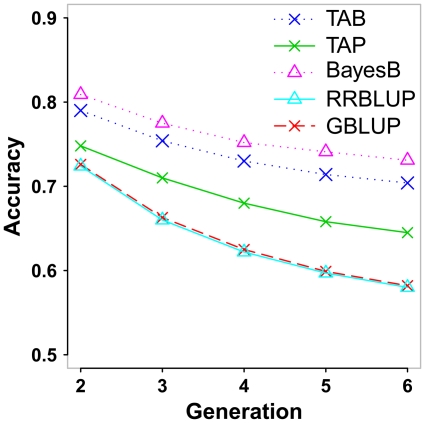
METHODOLOGY/PRINCIPAL FINDINGS: In the framework of mixed model equations, a new best linear unbiased prediction (BLUP) method including a trait-specific relationship matrix (TA) was presented and termed TABLUP. The TA matrix was constructed on the basis of marker genotypes and their weights in relation to the trait of interest. A simulation study with 1,000 individuals as the training population and five successive generations as candidate population was carried out to validate the proposed method. The proposed TABLUP method outperformed the ridge regression BLUP (RRBLUP) and BLUP with realized relationship matrix (GBLUP). It performed slightly worse than BayesB with an accuracy of 0.79 in the standard scenario.
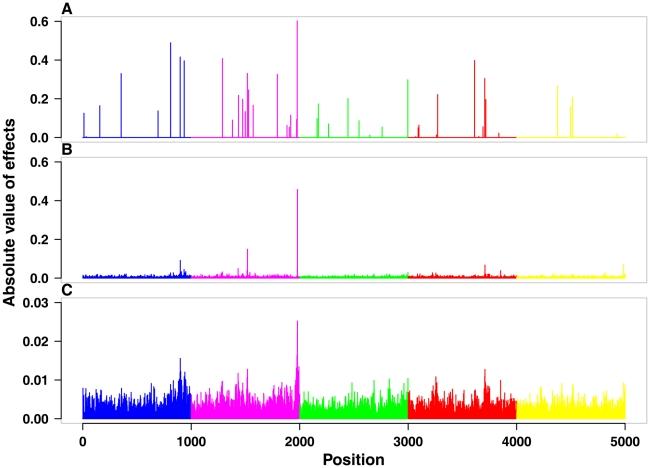
CONCLUSIONS/SIGNIFICANCE: The proposed TABLUP method is an improvement of the RRBLUP and GBLUP method. It might be equivalent to the BayesB method but it has additional benefits like the calculation of accuracies for individual breeding values. The results also showed that the TA-matrix performs better in predicting ability than the classical numerator relationship matrix and the realized relationship matrix which are derived solely from pedigree or markers without regard to the trait. This is because the TA-matrix not only accounts for the Mendelian sampling term, but also puts the greater emphasis on those markers that explain more of the genetic variance in the trait.
随着高密度全基因组单核苷酸多态性芯片的出现,基因组选择已成为一种很有前途的方法,可以对具有重要经济价值的动物、植物和水产养殖物种进行遗传评估,其潜在精度很高。利用覆盖整个基因组的标记,可以直接在混合模型方程框架内,通过使用基于标记的个体间关系矩阵来预测个体的遗传优势。在这里,我们通过为感兴趣的性状推导基于标记的关系矩阵来扩展该方法。
方法/主要发现:在混合模型方程框架内,提出了一种新的最佳线性无偏预测(BLUP)方法,包括一个特定于性状的关系矩阵(TA),并将其命名为 TABLUP。TA 矩阵是基于标记基因型及其与感兴趣性状的权重构建的。通过对 1000 个个体作为训练群体和 5 个连续世代作为候选群体的模拟研究,验证了该方法的有效性。与岭回归 BLUP(RRBLUP)和基于实现关系矩阵的 BLUP(GBLUP)相比,所提出的 TABLUP 方法表现更好。在标准情况下,其准确性为 0.79,略低于 BayesB。
结论/意义:所提出的 TABLUP 方法是 RRBLUP 和 GBLUP 方法的改进。它可能与 BayesB 方法等效,但具有额外的优势,例如可以计算个体育种值的准确性。结果还表明,TA 矩阵在预测能力方面优于经典的分子关系矩阵和仅基于系谱或标记而不考虑性状的实现关系矩阵。这是因为 TA 矩阵不仅考虑了 Mendelian 抽样项,而且更注重那些能解释性状中更多遗传方差的标记。