Blankers Matthijs, Koeter Maarten W J, Schippers Gerard M
Arkin Academy, Amsterdam, The Netherlands.
J Med Internet Res. 2010 Dec 19;12(5):e54. doi: 10.2196/jmir.1448.
Missing data is a common nuisance in eHealth research: it is hard to prevent and may invalidate research findings.
In this paper several statistical approaches to data "missingness" are discussed and tested in a simulation study. Basic approaches (complete case analysis, mean imputation, and last observation carried forward) and advanced methods (expectation maximization, regression imputation, and multiple imputation) are included in this analysis, and strengths and weaknesses are discussed.
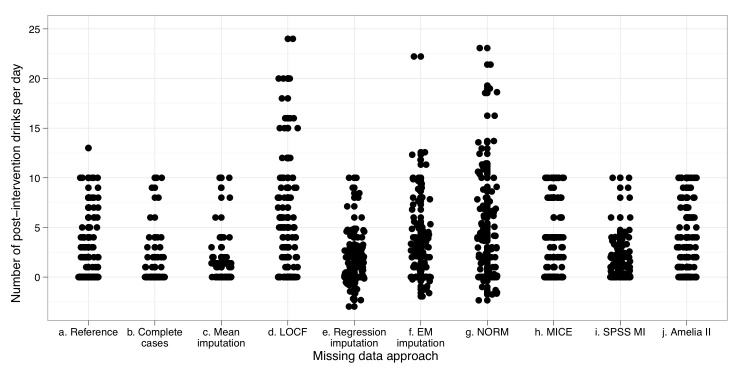
The dataset used for the simulation was obtained from a prospective cohort study following participants in an online self-help program for problem drinkers. It contained 124 nonnormally distributed endpoints, that is, daily alcohol consumption counts of the study respondents. Missingness at random (MAR) was induced in a selected variable for 50% of the cases. Validity, reliability, and coverage of the estimates obtained using the different imputation methods were calculated by performing a bootstrapping simulation study.
In the performed simulation study, the use of multiple imputation techniques led to accurate results. Differences were found between the 4 tested multiple imputation programs: NORM, MICE, Amelia II, and SPSS MI. Among the tested approaches, Amelia II outperformed the others, led to the smallest deviation from the reference value (Cohen's d = 0.06), and had the largest coverage percentage of the reference confidence interval (96%).
The use of multiple imputation improves the validity of the results when analyzing datasets with missing observations. Some of the often-used approaches (LOCF, complete cases analysis) did not perform well, and, hence, we recommend not using these. Accumulating support for the analysis of multiple imputed datasets is seen in more recent versions of some of the widely used statistical software programs making the use of multiple imputation more readily available to less mathematically inclined researchers.
缺失数据是电子健康研究中常见的麻烦事:难以预防,且可能使研究结果无效。
本文在一项模拟研究中讨论并测试了几种处理数据“缺失”的统计方法。该分析纳入了基本方法(完全病例分析、均值插补和末次观察结转)和先进方法(期望最大化、回归插补和多重插补),并讨论了其优缺点。
用于模拟的数据集来自一项前瞻性队列研究,该研究跟踪参与针对问题饮酒者的在线自助项目的参与者。它包含124个非正态分布的终点指标,即研究对象的每日饮酒量。在50%的病例中,对一个选定变量人为制造随机缺失(MAR)。通过进行自抽样模拟研究,计算使用不同插补方法获得的估计值的有效性、可靠性和覆盖范围。
在进行的模拟研究中,使用多重插补技术得出了准确的结果。在4个测试的多重插补程序(NORM、MICE、Amelia II和SPSS MI)之间发现了差异。在测试的方法中,Amelia II表现优于其他方法,与参考值的偏差最小(科恩d值 = 0.06),参考置信区间的覆盖百分比最大(96%)。
在分析存在缺失观察值的数据集时,使用多重插补可提高结果的有效性。一些常用方法(末次观察结转、完全病例分析)表现不佳,因此,我们建议不要使用这些方法。在一些广泛使用的统计软件的最新版本中,可以看到对多重插补数据集分析的支持不断增加,这使得数学能力稍弱的研究人员更容易使用多重插补。