National Institute of Biomedical Innovation, Saito-Asagi, Ibaraki, Osaka, Japan.
PLoS One. 2011 Mar 8;6(3):e17844. doi: 10.1371/journal.pone.0017844.
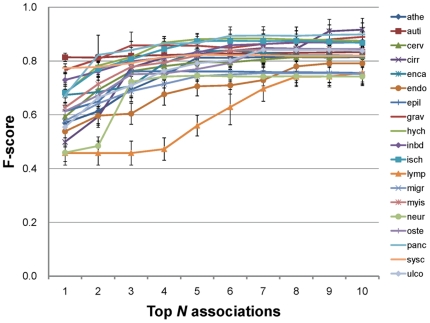
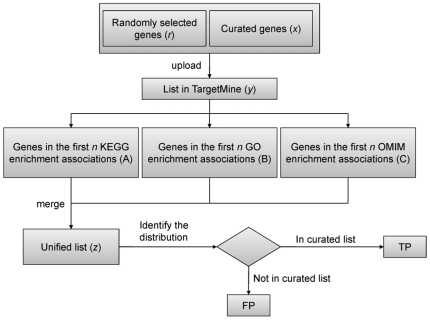
Prioritising candidate genes for further experimental characterisation is a non-trivial challenge in drug discovery and biomedical research in general. An integrated approach that combines results from multiple data types is best suited for optimal target selection. We developed TargetMine, a data warehouse for efficient target prioritisation. TargetMine utilises the InterMine framework, with new data models such as protein-DNA interactions integrated in a novel way. It enables complicated searches that are difficult to perform with existing tools and it also offers integration of custom annotations and in-house experimental data. We proposed an objective protocol for target prioritisation using TargetMine and set up a benchmarking procedure to evaluate its performance. The results show that the protocol can identify known disease-associated genes with high precision and coverage. A demonstration version of TargetMine is available at http://targetmine.nibio.go.jp/.
在药物发现和一般的生物医学研究中,优先考虑候选基因进行进一步的实验表征是一项具有挑战性的任务。一种整合多种数据类型的结果的综合方法最适合于最佳目标选择。我们开发了 TargetMine,这是一个用于有效目标优先级排序的数据仓库。TargetMine 利用 InterMine 框架,以新的方式集成了蛋白质-DNA 相互作用等新的数据模型。它支持现有的工具难以执行的复杂搜索,并且还提供了自定义注释和内部实验数据的集成。我们提出了使用 TargetMine 进行目标优先级排序的客观方案,并建立了基准测试程序来评估其性能。结果表明,该方案可以高精度和高覆盖率地识别已知的与疾病相关的基因。TargetMine 的演示版本可在 http://targetmine.nibio.go.jp/ 获得。