Astrophysics Group, Cavendish Laboratory, Cambridge, United Kingdom.
PLoS One. 2011 May 12;6(5):e14802. doi: 10.1371/journal.pone.0014802.
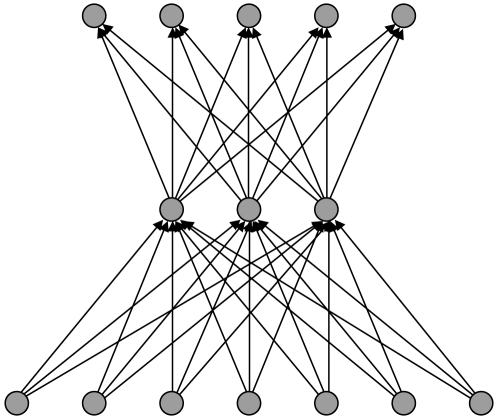
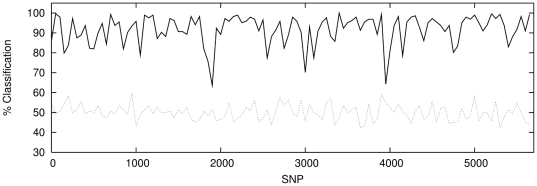
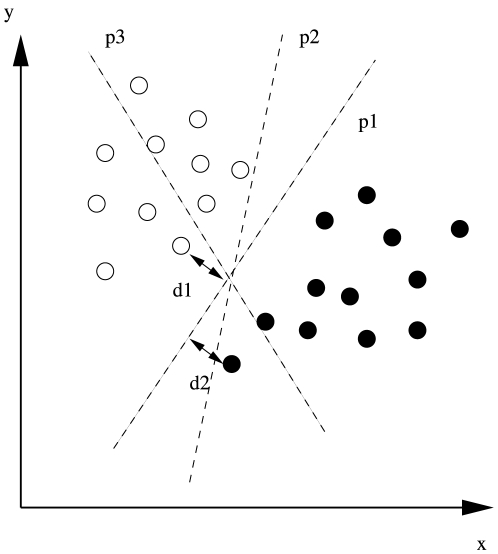
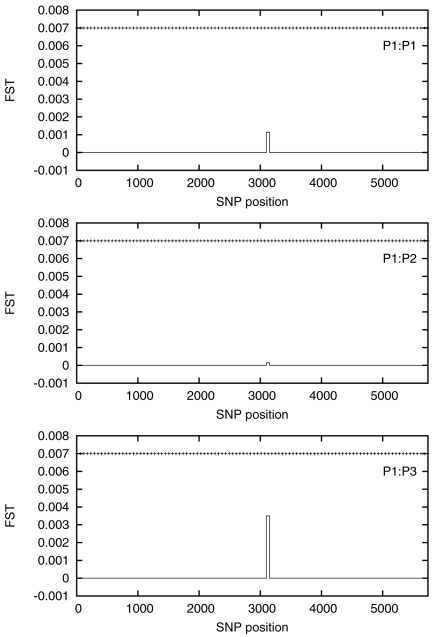
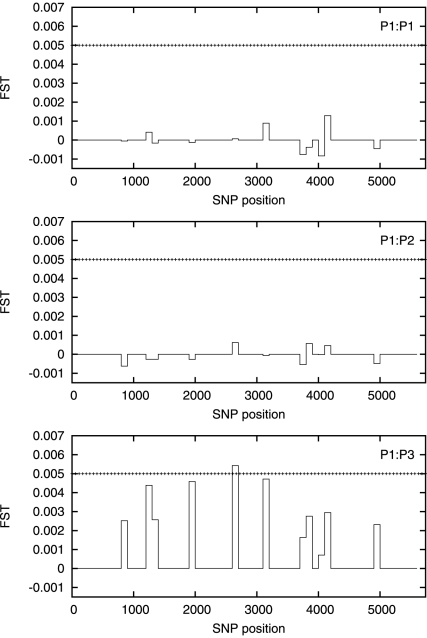
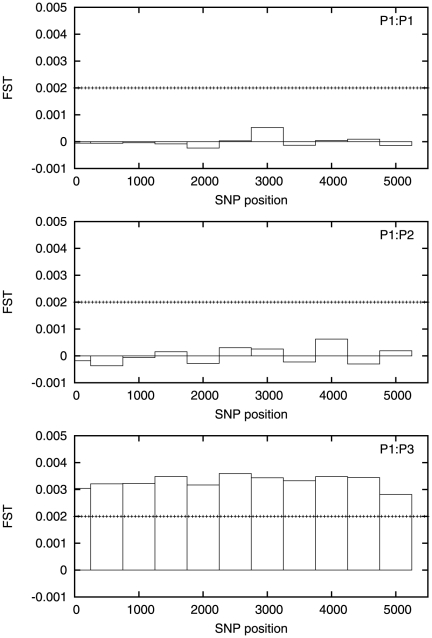
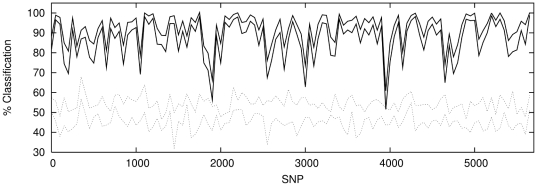
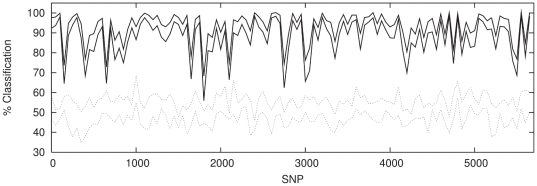
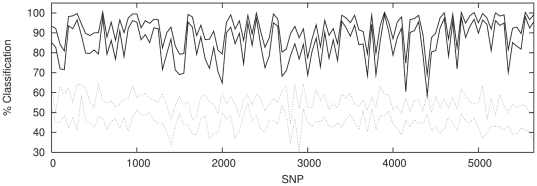
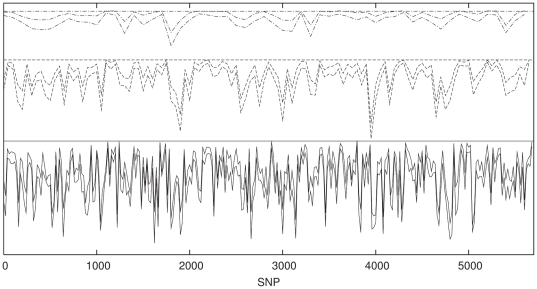
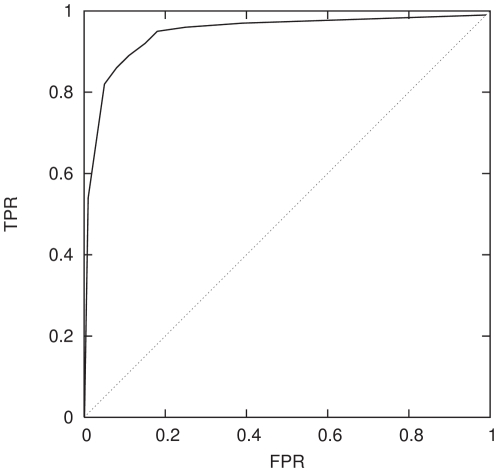
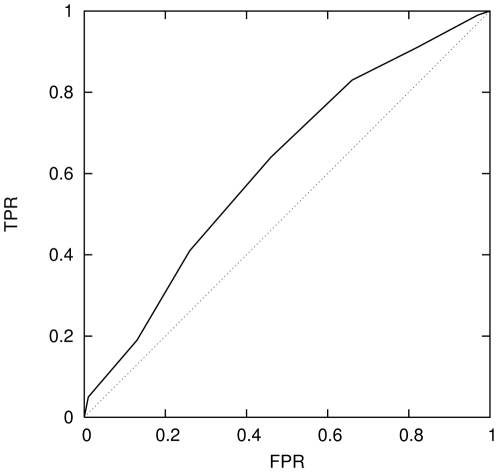
There are many instances in genetics in which we wish to determine whether two candidate populations are distinguishable on the basis of their genetic structure. Examples include populations which are geographically separated, case-control studies and quality control (when participants in a study have been genotyped at different laboratories). This latter application is of particular importance in the era of large scale genome wide association studies, when collections of individuals genotyped at different locations are being merged to provide increased power. The traditional method for detecting structure within a population is some form of exploratory technique such as principal components analysis. Such methods, which do not utilise our prior knowledge of the membership of the candidate populations. are termed unsupervised. Supervised methods, on the other hand are able to utilise this prior knowledge when it is available.In this paper we demonstrate that in such cases modern supervised approaches are a more appropriate tool for detecting genetic differences between populations. We apply two such methods, (neural networks and support vector machines) to the classification of three populations (two from Scotland and one from Bulgaria). The sensitivity exhibited by both these methods is considerably higher than that attained by principal components analysis and in fact comfortably exceeds a recently conjectured theoretical limit on the sensitivity of unsupervised methods. In particular, our methods can distinguish between the two Scottish populations, where principal components analysis cannot. We suggest, on the basis of our results that a supervised learning approach should be the method of choice when classifying individuals into pre-defined populations, particularly in quality control for large scale genome wide association studies.
在遗传学中,有许多情况下我们希望根据候选群体的遗传结构来确定它们是否可以区分。例如,地理上分离的群体、病例对照研究和质量控制(当研究中的参与者在不同的实验室进行基因分型时)。后一种应用在大规模全基因组关联研究时代尤为重要,当时来自不同地点的个体的基因分型集合被合并以提供更大的功率。在群体中检测结构的传统方法是某种形式的探索性技术,如主成分分析。这些方法不利用我们对候选群体成员身份的先验知识,因此被称为无监督。另一方面,有监督的方法在可用时能够利用这种先验知识。在本文中,我们证明在这种情况下,现代有监督的方法是检测群体之间遗传差异的更合适的工具。我们将两种这样的方法(神经网络和支持向量机)应用于三个群体(两个来自苏格兰,一个来自保加利亚)的分类。这两种方法的灵敏度都明显高于主成分分析所达到的灵敏度,实际上远远超过了最近对无监督方法灵敏度的理论猜测。特别是,我们的方法可以区分两个苏格兰群体,而主成分分析则不能。根据我们的结果,我们建议在将个体分类到预定义群体时,应选择有监督的学习方法,特别是在大规模全基因组关联研究的质量控制中。