Arizona State University, Tempe, Arizona, USA.
Ear Hear. 2012 Jan-Feb;33(1):112-7. doi: 10.1097/AUD.0b013e31822c2549.
The goal of this study was to create and validate a new set of sentence lists that could be used to evaluate the speech perception abilities of hearing-impaired listeners and cochlear implant (CI) users. Our intention was to generate a large number of sentence lists with an equivalent level of difficulty for the evaluation of performance over time and across conditions.
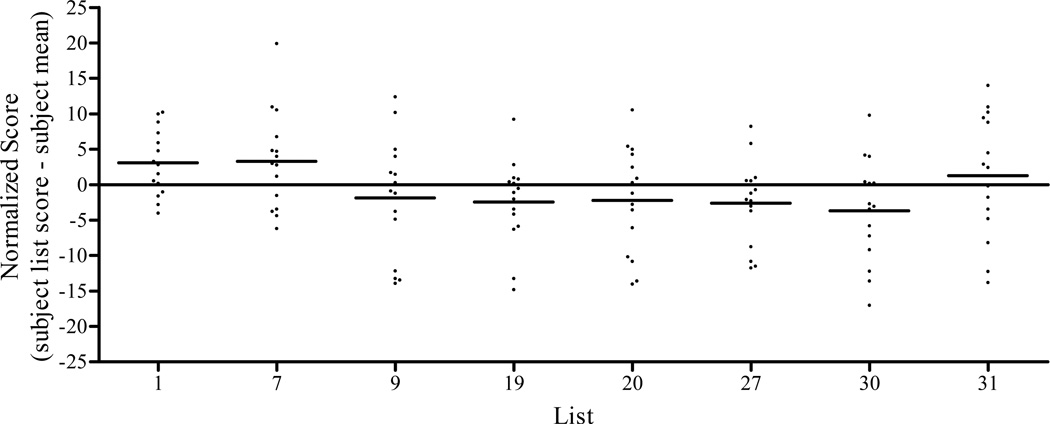
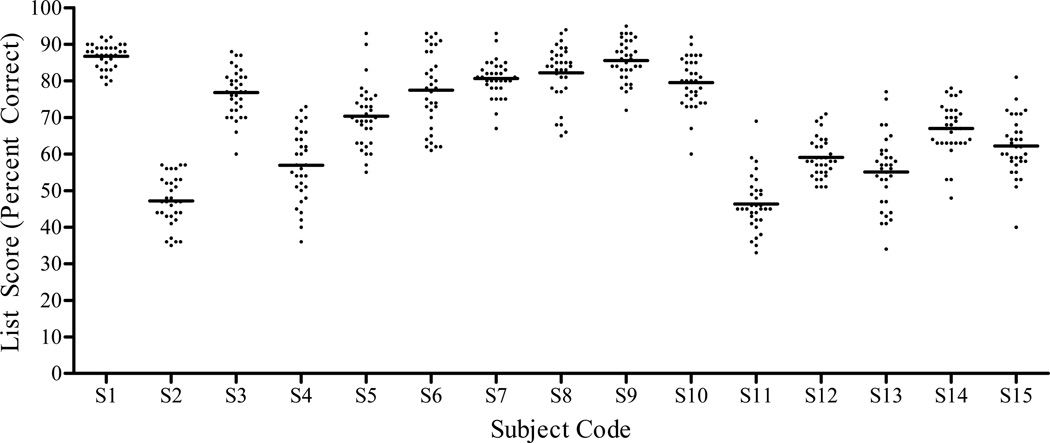
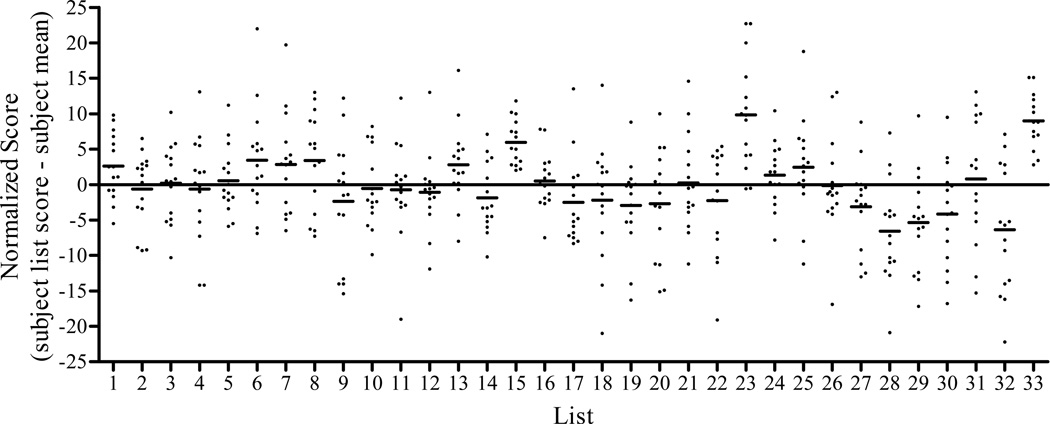
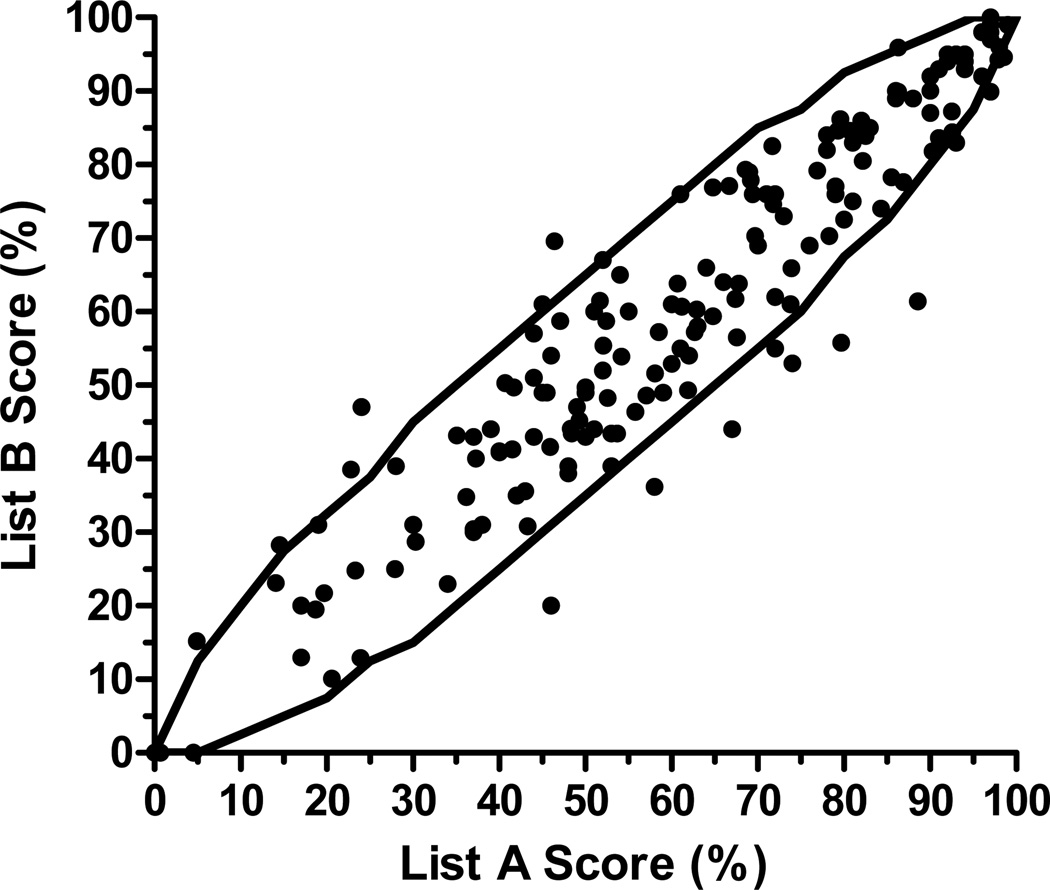
The AzBio sentence corpus includes 1000 sentences recorded from two female and two male talkers. The mean intelligibility of each sentence was estimated by processing each sentence through a five-channel CI simulation and calculating the mean percent correct score achieved by 15 normal-hearing listeners. Sentences from each talker were sorted by percent correct score, and 165 sentences were selected from each talker and were then sequentially assigned to 33 lists, each containing 20 sentences (5 sentences from each talker). List equivalency was validated by presenting all lists, in random order, to 15 CI users.
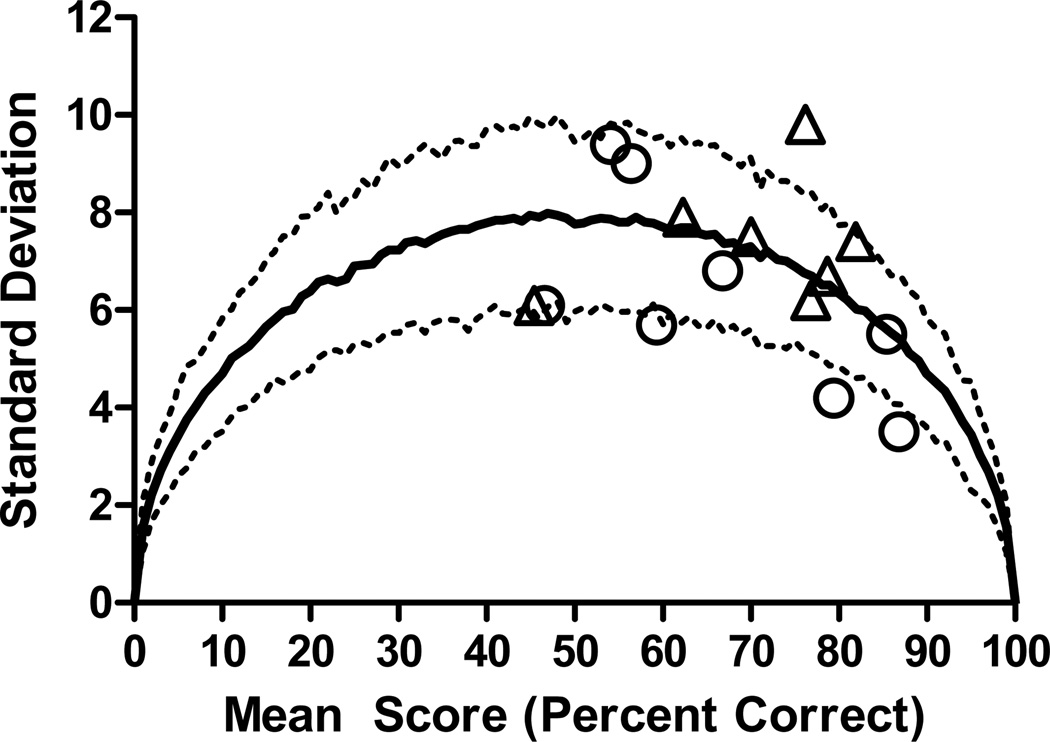
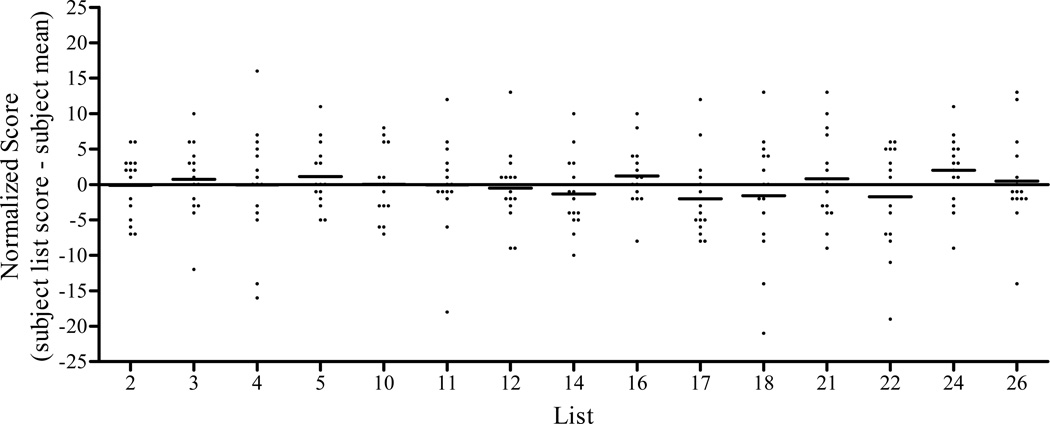
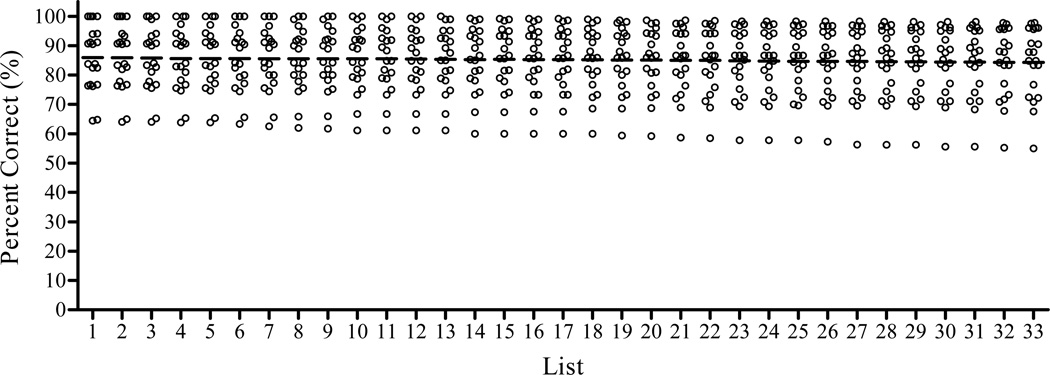
Using sentence scores from the CI simulation study produced 33 lists of sentences with a mean score of 85% correct. The results of the validation study with CI users revealed no significant differences in percent correct scores for 29 of the 33 sentence lists. However, individual listeners demonstrated considerable variability in performance on the 29 lists. The binomial distribution model was used to account for the inherent variability observed in the lists. This model was also used to generate 95% confidence intervals for one and two list comparisons. A retrospective analysis of 172 instances where research subjects had been tested on two lists within a single condition revealed that 94% of results were accurately contained within these confidence intervals.
The use of a five-channel CI simulation to estimate the intelligibility of individual sentences allowed for the creation of a large number of sentence lists with an equivalent level of difficulty. The results of the validation procedure with CI users found that 29 of 33 lists allowed scores that were not statistically different. However, individual listeners demonstrated considerable variability in performance across lists. This variability was accurately described by the binomial distribution model and was used to estimate the magnitude of change required to achieve statistical significance when comparing scores from one and two lists per condition. Fifteen sentence lists have been included in the AzBio Sentence Test for use in the clinical evaluation of hearing-impaired listeners and CI users. An additional eight sentence lists have been included in the Minimum Speech Test Battery to be distributed by the CI manufacturers for the evaluation of CI candidates.
本研究的目的是创建和验证一套新的句子列表,用于评估听力障碍者和人工耳蜗(CI)使用者的言语感知能力。我们的意图是生成大量具有同等难度的句子列表,以便随着时间的推移和条件的变化评估性能。
AzBio 句子语料库包含来自两名女性和两名男性说话者录制的 1000 个句子。通过对每个句子进行五通道 CI 模拟处理,并计算 15 名正常听力听众的平均正确百分比分数,估计每个句子的可理解度。根据正确百分比分数对每个说话者的句子进行排序,然后从每个说话者中选择 165 个句子,然后顺序分配给 33 个列表,每个列表包含 20 个句子(每个说话者 5 个句子)。通过向 15 名 CI 用户随机呈现所有列表来验证列表的等效性。
使用 CI 模拟研究中的句子分数生成了 33 个句子列表,平均正确分数为 85%。使用 CI 用户进行的验证研究结果显示,33 个句子列表中的 29 个列表的正确百分比分数没有显著差异。然而,个别听众在 29 个列表上的表现差异很大。二项分布模型用于解释列表中观察到的固有可变性。该模型还用于生成一个和两个列表比较的 95%置信区间。对 172 个研究对象在单个条件下接受两个列表测试的实例进行的回顾性分析表明,94%的结果准确地包含在这些置信区间内。
使用五通道 CI 模拟来估计单个句子的可理解度,可以创建具有同等难度的大量句子列表。使用 CI 用户进行的验证程序的结果发现,33 个列表中的 29 个列表的得分没有统计学差异。然而,个别听众在列表之间的表现差异很大。这种可变性可以通过二项分布模型准确描述,并用于估计在比较每个条件下的一个和两个列表的分数时需要达到统计显著性的变化量。15 个句子列表已包含在 AzBio 句子测试中,用于听力障碍者和 CI 用户的临床评估。另外 8 个句子列表包含在最小语音测试电池中,由 CI 制造商分发,用于评估 CI 候选人。