Department of Mathematics, Logistical Engineering University, Chongqing, China.
PLoS One. 2011;6(9):e24306. doi: 10.1371/journal.pone.0024306. Epub 2011 Sep 2.
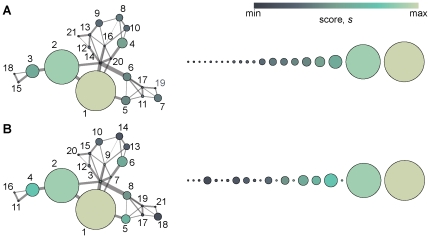
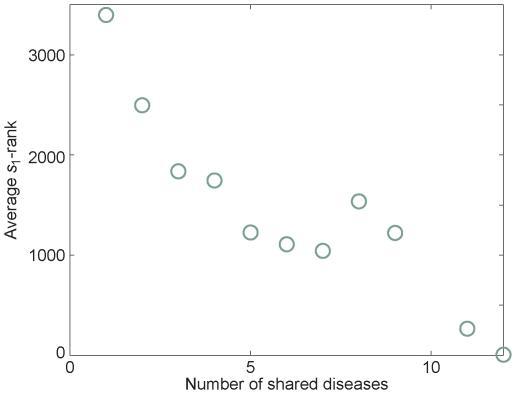
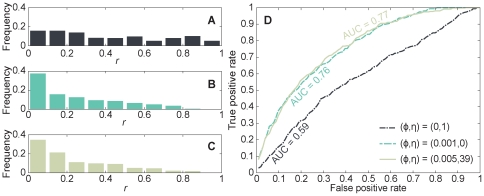
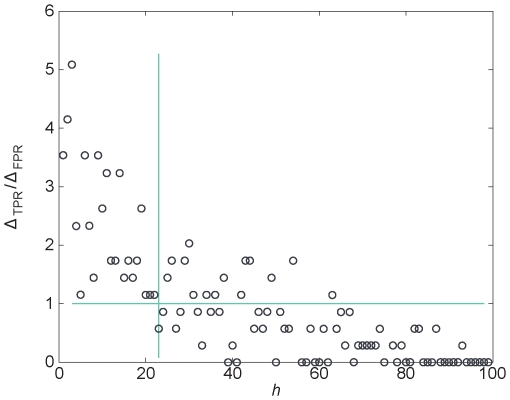
Many diseases have complex genetic causes, where a set of alleles can affect the propensity of getting the disease. The identification of such disease genes is important to understand the mechanistic and evolutionary aspects of pathogenesis, improve diagnosis and treatment of the disease, and aid in drug discovery. Current genetic studies typically identify chromosomal regions associated specific diseases. But picking out an unknown disease gene from hundreds of candidates located on the same genomic interval is still challenging. In this study, we propose an approach to prioritize candidate genes by integrating data of gene expression level, protein-protein interaction strength and known disease genes. Our method is based only on two, simple, biologically motivated assumptions--that a gene is a good disease-gene candidate if it is differentially expressed in cases and controls, or that it is close to other disease-gene candidates in its protein interaction network. We tested our method on 40 diseases in 58 gene expression datasets of the NCBI Gene Expression Omnibus database. On these datasets our method is able to predict unknown disease genes as well as identifying pleiotropic genes involved in the physiological cellular processes of many diseases. Our study not only provides an effective algorithm for prioritizing candidate disease genes but is also a way to discover phenotypic interdependency, cooccurrence and shared pathophysiology between different disorders.
许多疾病的病因都很复杂,其中一组等位基因可能会影响患病的倾向。识别这些疾病基因对于理解发病机制的机制和进化方面、改善疾病的诊断和治疗以及辅助药物发现都很重要。目前的遗传研究通常会识别与特定疾病相关的染色体区域。但是,要从位于同一基因组间隔内的数百个候选者中挑选出未知的疾病基因仍然具有挑战性。在这项研究中,我们提出了一种通过整合基因表达水平、蛋白质-蛋白质相互作用强度和已知疾病基因的数据来优先考虑候选基因的方法。我们的方法仅基于两个简单的、基于生物学的假设——如果一个基因在病例和对照中差异表达,或者在其蛋白质相互作用网络中与其他疾病基因候选者接近,那么它就是一个很好的疾病基因候选者。我们在 NCBI Gene Expression Omnibus 数据库的 58 个基因表达数据集的 40 种疾病上测试了我们的方法。在这些数据集中,我们的方法能够预测未知的疾病基因,并确定涉及许多疾病生理细胞过程的多效性基因。我们的研究不仅提供了一种有效的算法来优先考虑候选疾病基因,而且还可以发现不同疾病之间表型的相互依存性、共现和共同的病理生理学。