Department of Biostatistics, Indiana University, 410 West 10th Street, Indianapolis, IN 46202, USA.
BMC Bioinformatics. 2011 Oct 10;12:392. doi: 10.1186/1471-2105-12-392.
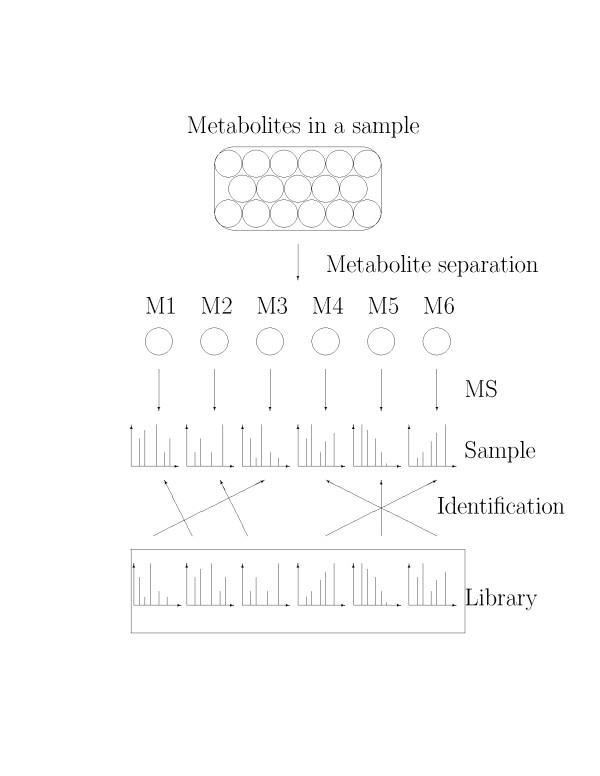
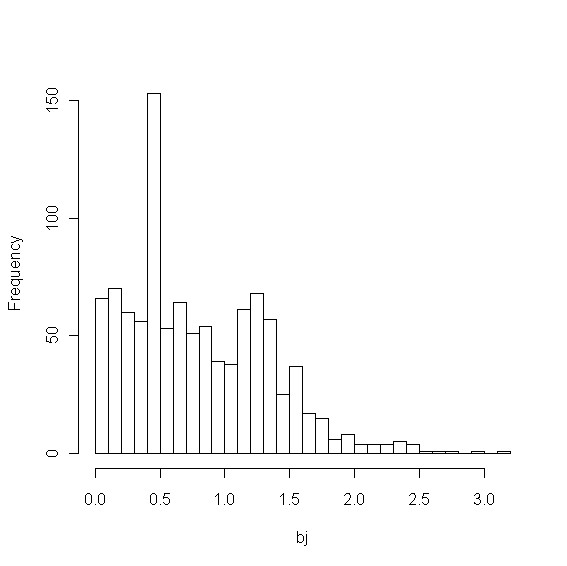
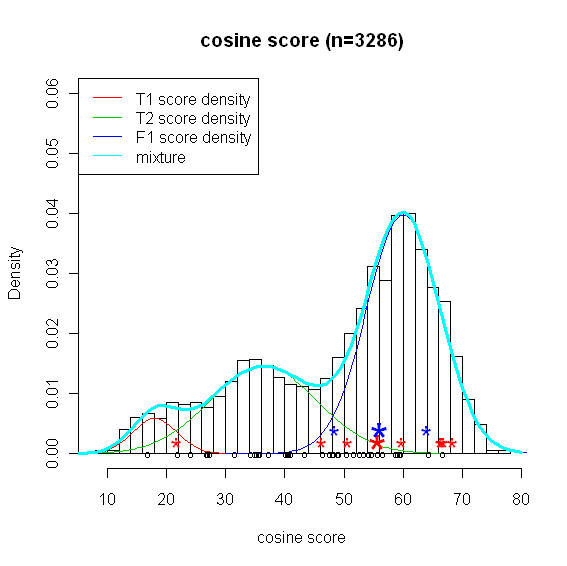
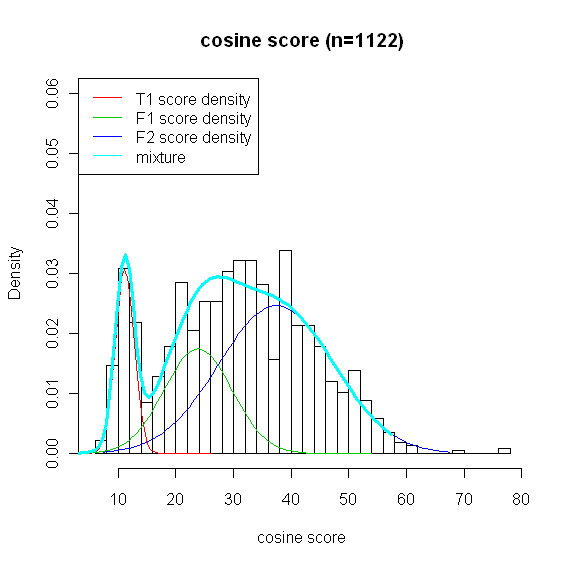
Mass spectrometry (MS) based metabolite profiling has been increasingly popular for scientific and biomedical studies, primarily due to recent technological development such as comprehensive two-dimensional gas chromatography time-of-flight mass spectrometry (GCxGC/TOF-MS). Nevertheless, the identifications of metabolites from complex samples are subject to errors. Statistical/computational approaches to improve the accuracy of the identifications and false positive estimate are in great need. We propose an empirical Bayes model which accounts for a competing score in addition to the similarity score to tackle this problem. The competition score characterizes the propensity of a candidate metabolite of being matched to some spectrum based on the metabolite's similarity score with other spectra in the library searched against. The competition score allows the model to properly assess the evidence on the presence/absence status of a metabolite based on whether or not the metabolite is matched to some sample spectrum.
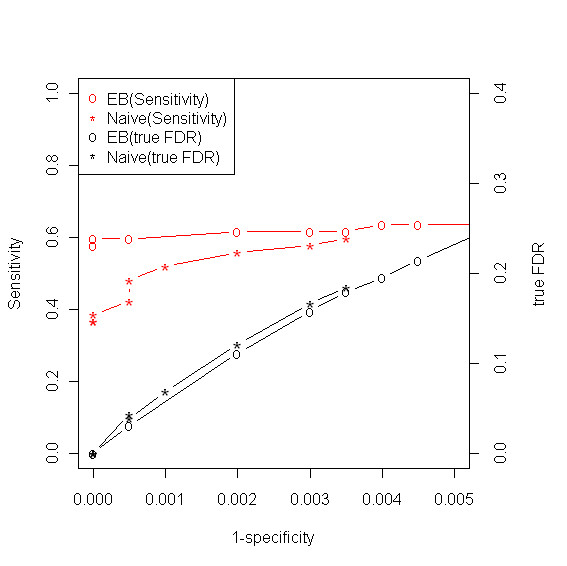
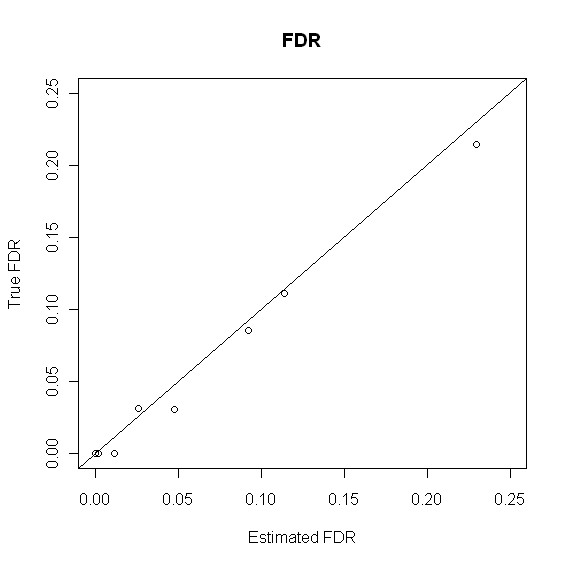
With a mixture of metabolite standards, we demonstrated that our method has better identification accuracy than other four existing methods. Moreover, our method has reliable false discovery rate estimate. We also applied our method to the data collected from the plasma of a rat and identified some metabolites from the plasma under the control of false discovery rate.
We developed an empirical Bayes model for metabolite identification and validated the method through a mixture of metabolite standards and rat plasma. The results show that our hierarchical model improves identification accuracy as compared with methods that do not structurally model the involved variables. The improvement in identification accuracy is likely to facilitate downstream analysis such as peak alignment and biomarker identification. Raw data and result matrices can be found at http://www.biostat.iupui.edu/~ChangyuShen/index.htm.
2123938128573429.
基于质谱(MS)的代谢物分析已越来越受到科学和生物医学研究的欢迎,主要是由于最近的技术发展,如全面二维气相色谱飞行时间质谱(GCxGC/TOF-MS)。然而,从复杂样品中鉴定代谢物仍存在误差。需要统计/计算方法来提高鉴定的准确性和假阳性估计。我们提出了一种经验贝叶斯模型,该模型除了相似性得分外,还考虑了竞争得分,以解决这个问题。竞争得分描述了候选代谢物根据其与库中搜索的其他光谱的相似性得分与某些光谱匹配的可能性。竞争得分允许模型根据代谢物是否与某些样品光谱匹配,正确评估代谢物存在/不存在状态的证据。
我们用混合代谢物标准品进行了演示,结果表明我们的方法比其他四种现有方法具有更高的鉴定准确性。此外,我们的方法具有可靠的假发现率估计。我们还将我们的方法应用于从大鼠血浆中收集的数据,并根据假发现率鉴定了一些来自血浆的代谢物。
我们开发了一种代谢物鉴定的经验贝叶斯模型,并通过混合代谢物标准品和大鼠血浆对该方法进行了验证。结果表明,与不结构建模所涉及变量的方法相比,我们的层次模型提高了鉴定准确性。鉴定准确性的提高可能有助于下游分析,如峰对齐和生物标志物鉴定。原始数据和结果矩阵可在 http://www.biostat.iupui.edu/~ChangyuShen/index.htm 上找到。
2123938128573429。