Department of Psychology, University of North Carolina at Chapel Hill 27599-3270, USA.
Psychol Methods. 2011 Dec;16(4):373-90. doi: 10.1037/a0025813. Epub 2011 Oct 31.
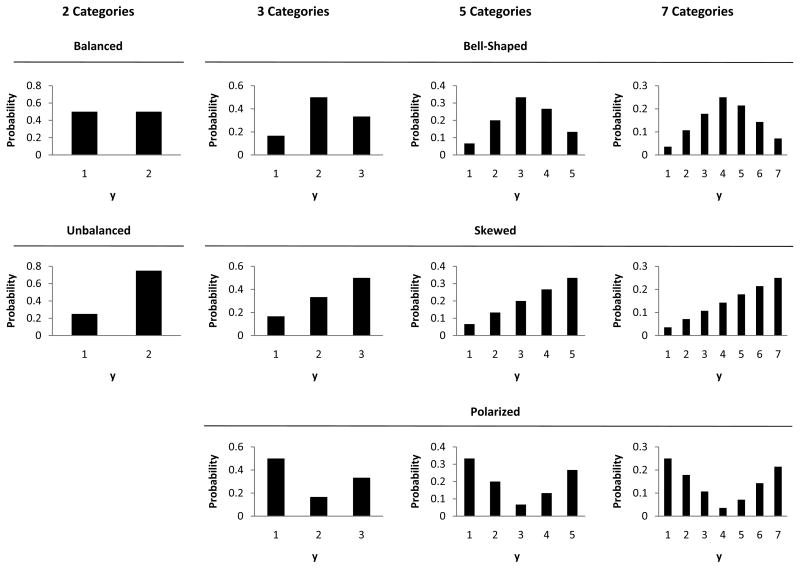
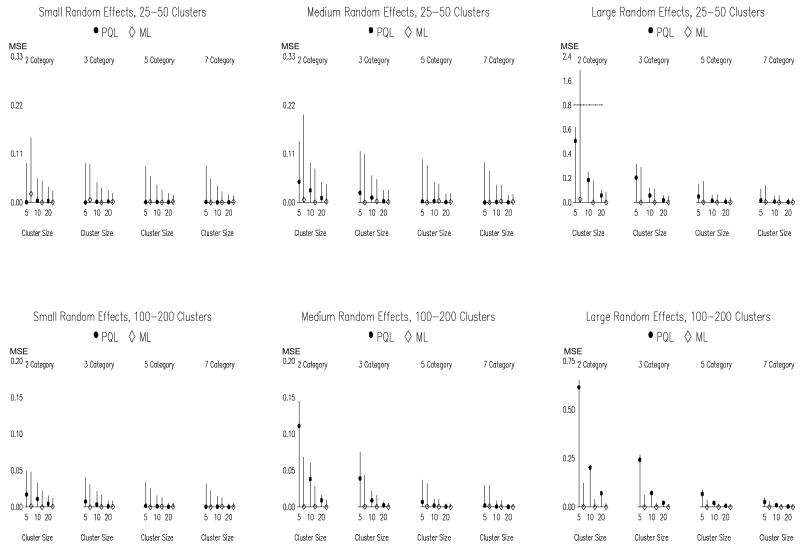
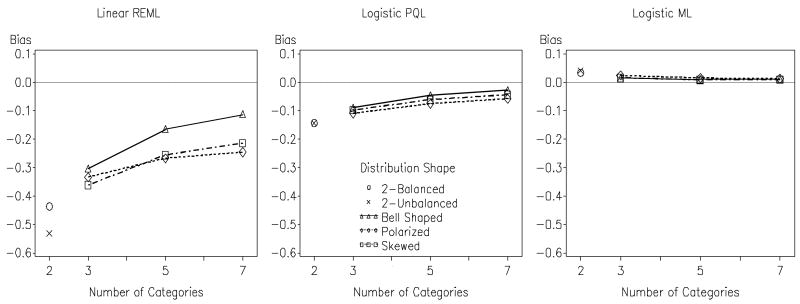
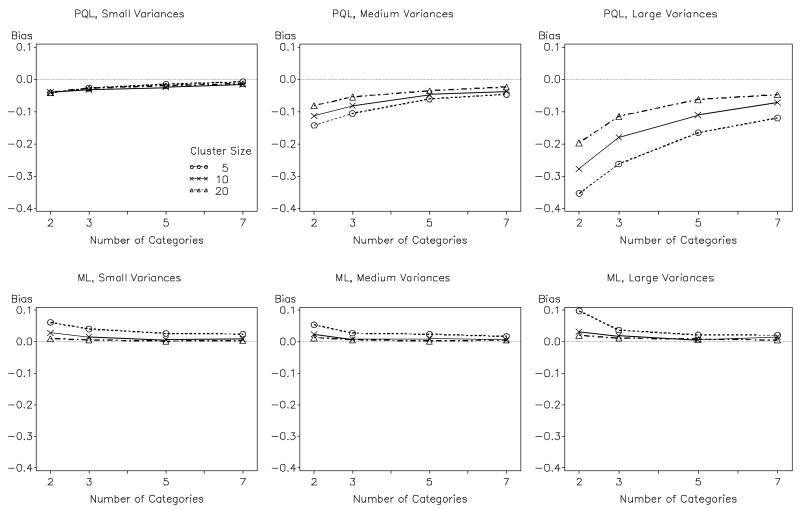
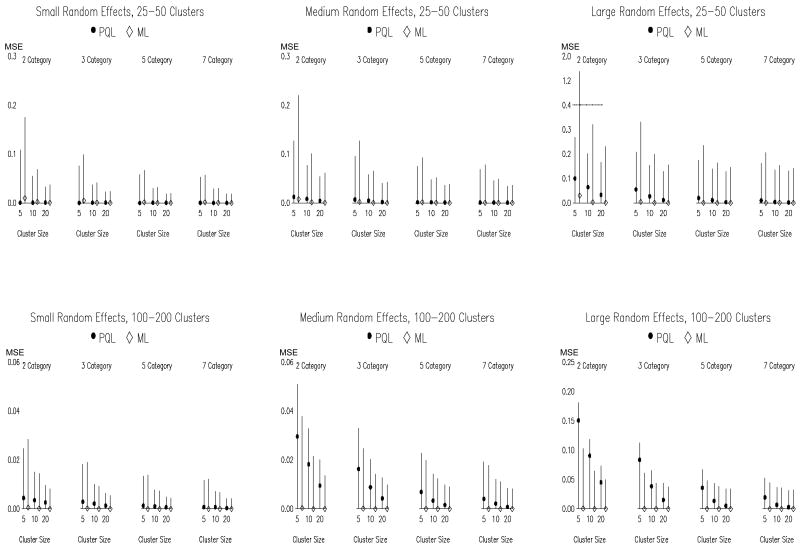
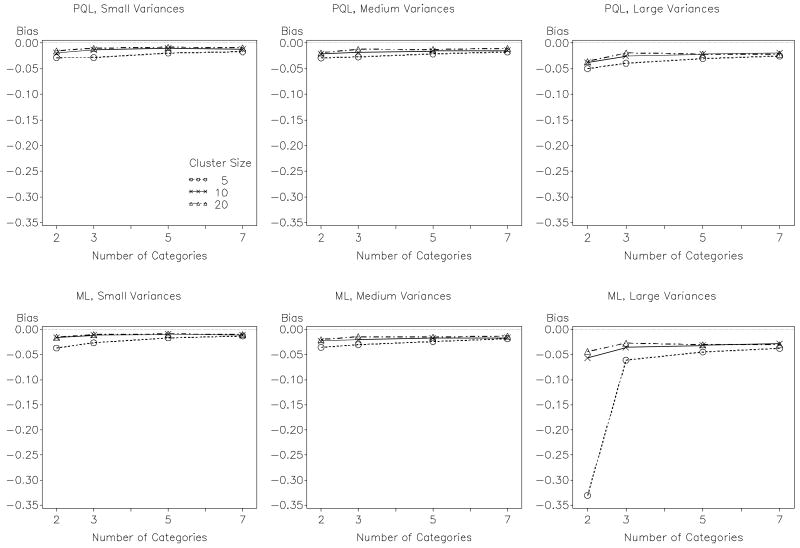
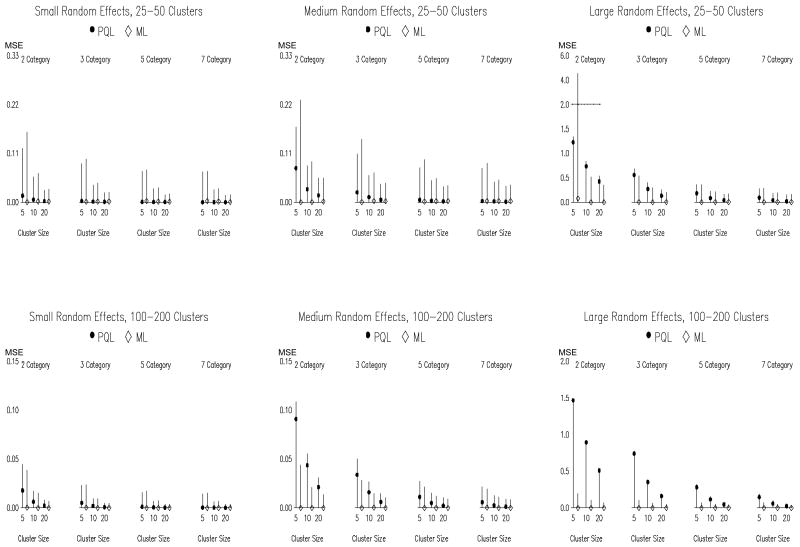
Previous research has compared methods of estimation for fitting multilevel models to binary data, but there are reasons to believe that the results will not always generalize to the ordinal case. This article thus evaluates (a) whether and when fitting multilevel linear models to ordinal outcome data is justified and (b) which estimator to employ when instead fitting multilevel cumulative logit models to ordinal data, maximum likelihood (ML), or penalized quasi-likelihood (PQL). ML and PQL are compared across variations in sample size, magnitude of variance components, number of outcome categories, and distribution shape. Fitting a multilevel linear model to ordinal outcomes is shown to be inferior in virtually all circumstances. PQL performance improves markedly with the number of ordinal categories, regardless of distribution shape. In contrast to binary data, PQL often performs as well as ML when used with ordinal data. Further, the performance of PQL is typically superior to ML when the data include a small to moderate number of clusters (i.e., ≤ 50 clusters).
先前的研究比较了用于拟合二项数据的多层模型估计方法,但有理由认为,这些结果并不总是适用于有序情况。因此,本文评估了(a)将多层线性模型拟合有序结果数据是否合理,以及(b)在将多层累积对数模型拟合有序数据时应采用哪种估计器,最大似然(ML)或惩罚拟似然(PQL)。比较了 ML 和 PQL 在样本量、方差分量大小、结果类别数量和分布形状的变化下的表现。几乎在所有情况下,将多层线性模型拟合有序结果都表现不佳。无论分布形状如何,PQL 的性能都会随着有序类别数量的增加而显著提高。与二项数据不同,当使用有序数据时,PQL 通常与 ML 一样好用。此外,当数据包括少量到中等数量的聚类(即≤50 个聚类)时,PQL 的性能通常优于 ML。