House Research Institute, Los Angeles, CA, USA.
J Speech Lang Hear Res. 2012 Jun;55(3):800-10. doi: 10.1044/1092-4388(2011/11-0124). Epub 2012 Jan 5.
The goal of this study was to investigate how the spectral and temporal properties in background music may interfere with cochlear implant (CI) and normal-hearing listeners' (NH) speech understanding.
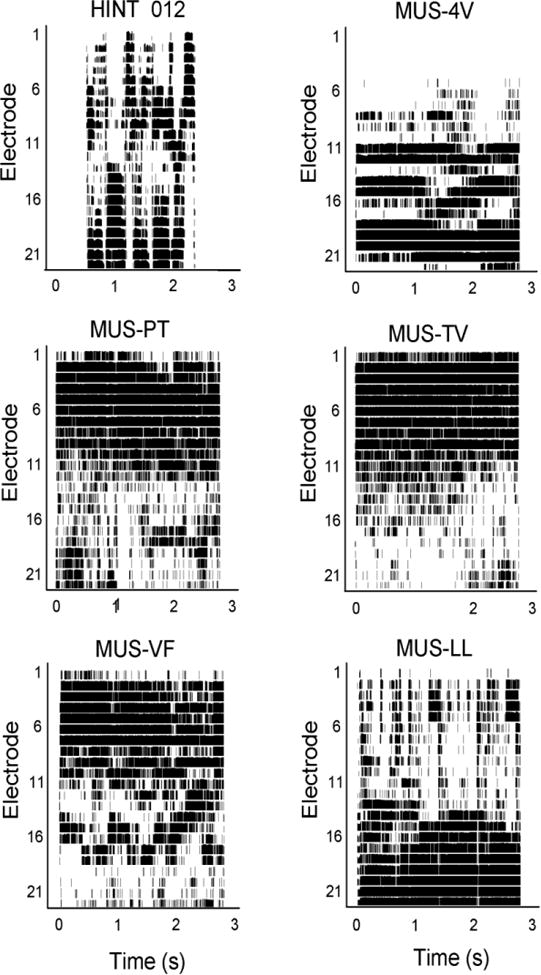
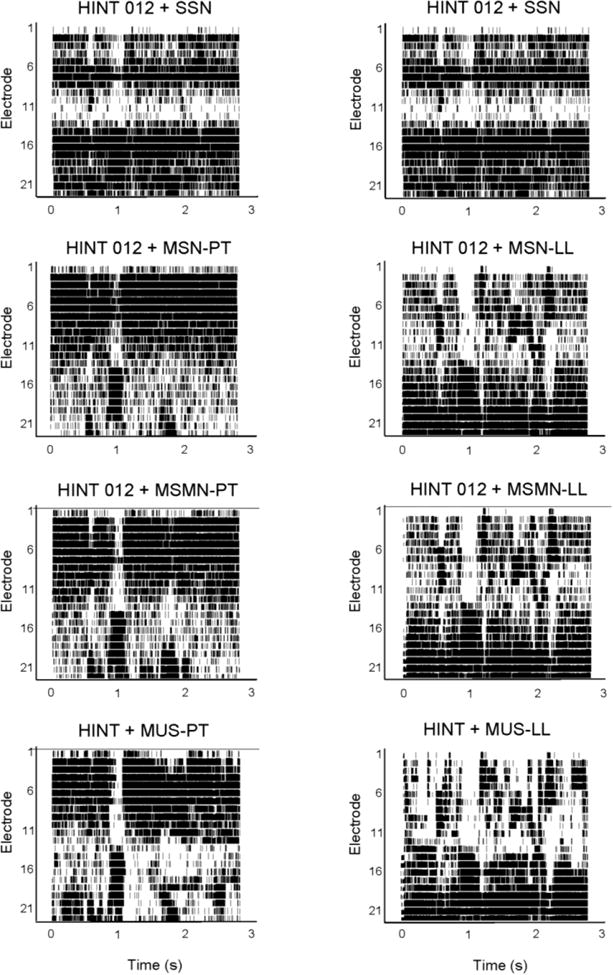
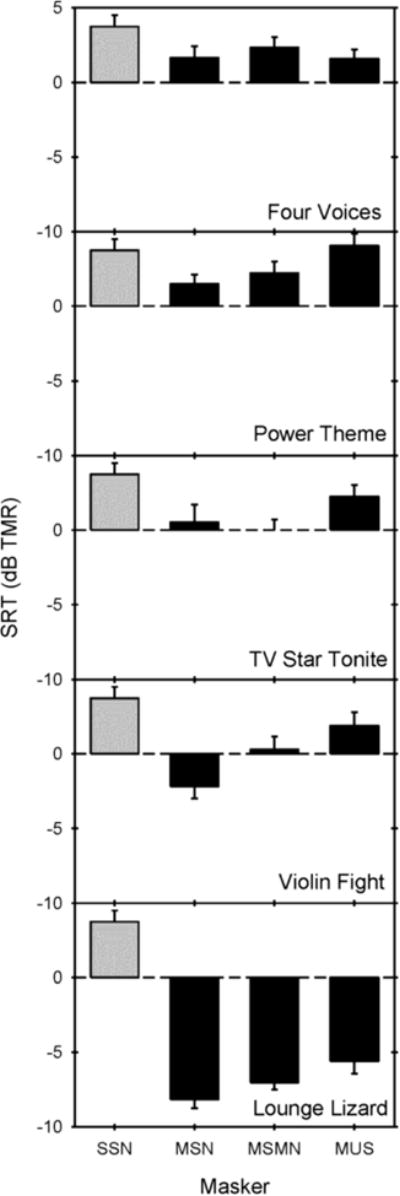
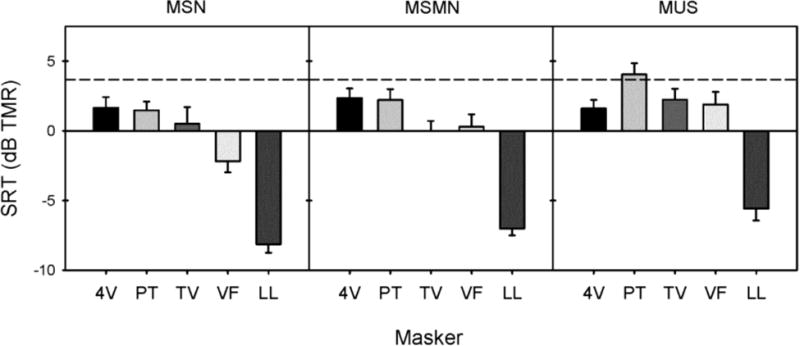
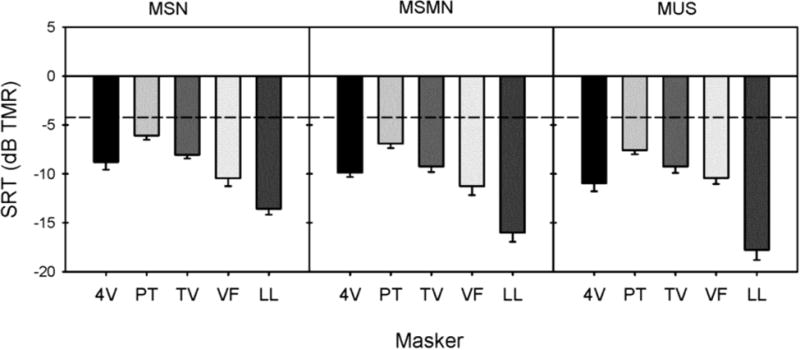
Speech-recognition thresholds (SRTs) were adaptively measured in 11 CI and 9 NH subjects. CI subjects were tested while using their clinical processors; NH subjects were tested while listening to unprocessed audio. Speech was presented with different music maskers (excerpts from musical pieces) and with steady, speech-shaped noise. To estimate the contributions of energetic and informational masking, SRTs were also measured in "music-shaped noise" and in music-shaped noise modulated by the music temporal envelopes.
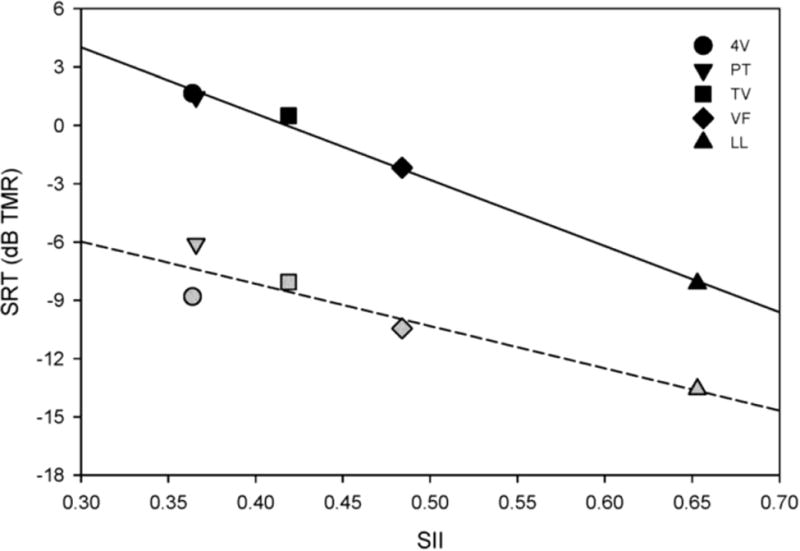
NH performance was much better than CI performance. For both subject groups, SRTs were much lower with the music-related maskers than with speech-shaped noise. SRTs were strongly predicted by the amount of energetic masking in the music maskers. Unlike CI users, NH listeners obtained release from masking with envelope and fine structure cues in the modulated noise and music maskers.
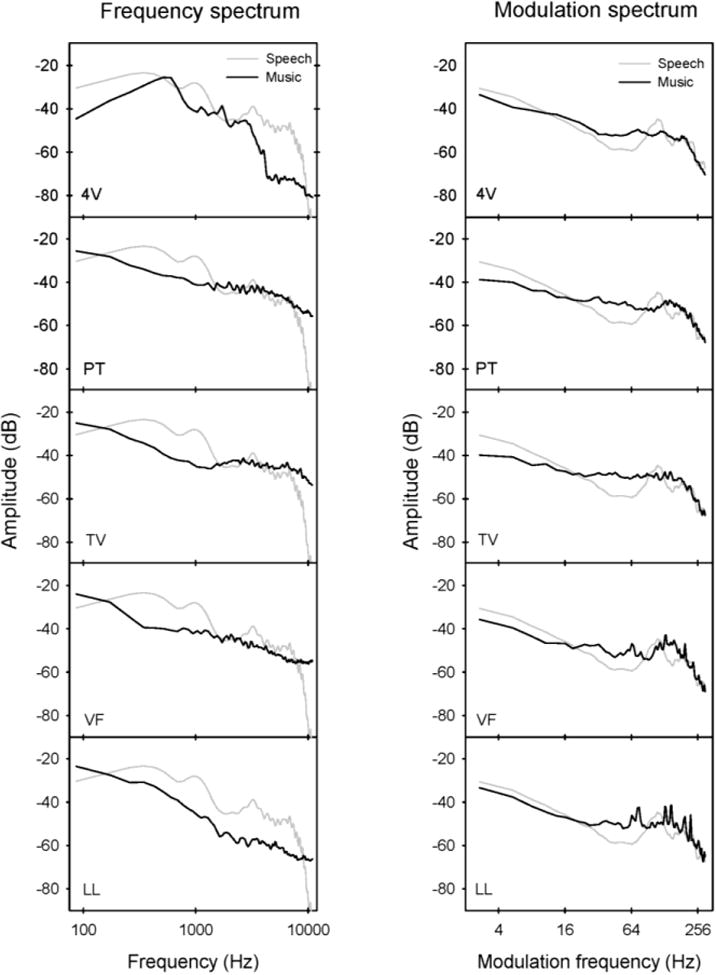
Although speech understanding was greatly limited by energetic masking in both subject groups, CI performance worsened as more spectrotemporal complexity was added to the maskers, most likely due to poor spectral resolution.
本研究旨在探讨背景音乐的光谱和时间特性如何干扰人工耳蜗(CI)和正常听力(NH)听众的言语理解。
对 11 名 CI 和 9 名 NH 受试者进行自适应言语识别阈值(SRT)测量。CI 受试者使用其临床处理器进行测试,NH 受试者使用未经处理的音频进行测试。使用不同的音乐掩蔽器(音乐片段节选)和稳定的言语形状噪声进行言语测试。为了估计能量和信息掩蔽的贡献,还在“音乐形状噪声”和音乐形状噪声调制的音乐时间包络中测量 SRT。
NH 组的表现明显优于 CI 组。对于两个受试者组,与言语形状噪声相比,与音乐相关的掩蔽器的 SRT 低得多。SRT 强烈预测音乐掩蔽器中的能量掩蔽量。与 CI 用户不同,NH 听众在调制噪声和音乐掩蔽器中通过包络和精细结构线索获得掩蔽释放。
尽管在两个受试者组中,言语理解都受到能量掩蔽的极大限制,但 CI 性能随着掩蔽器中添加更多的光谱时间复杂度而恶化,这很可能是由于光谱分辨率差所致。